The Kinode Book
Kinode is a decentralized operating system, peer-to-peer app framework, and node network designed to simplify the development and deployment of decentralized applications. It is also a sovereign cloud computer, in that Kinode can be deployed anywhere and act as a server controlled by anyone. Ultimately, Kinode facilitates the writing and distribution of software that runs on privately-held, personal server nodes or node clusters.
You are reading the Kinode Book, which is a technical document targeted at developers.
Read the Kinode Whitepaper here.
If you're a non-technical user:
- Learn about Kinode at the Kinode blog.
- Spin up a hosted node at Valet.
- Follow us on X.
- Join the conversation on our Discord or Telegram.
If you're a developer:
- Get your hands dirty with the Quick Start, or the more detailed My First Kinode Application tutorial.
- Learn how to boot a Kinode locally in the Installation section.
Quick Start
Run two fake Kinodes and chat between them
# Get Rust and `kit` Kinode development tools
curl --proto '=https' --tlsv1.2 -sSf https://sh.rustup.rs | sh
cargo install --git https://github.com/kinode-dao/kit --locked
# Start two fake nodes, each in a new terminal on ports 8080 and 8081:
## First new terminal:
kit boot-fake-node
## Second new terminal:
kit boot-fake-node --home /tmp/kinode-fake-node-2 --port 8081 --fake-node-name fake2
# Back in the original terminal that is not running a fake node:
## Create and build a chat app from a template:
kit new my-chat-app
kit build my-chat-app
## Load the chat app into each node & start it:
kit start-package my-chat-app
kit start-package my-chat-app --port 8081
## Chat between the nodes:
kit inject-message my-chat-app:my-chat-app:template.os '{"Send": {"target": "fake2.dev", "message": "hello from the outside world"}}'
kit inject-message my-chat-app:my-chat-app:template.os '{"Send": {"target": "fake.dev", "message": "replying from fake2.dev using first method..."}}' --node fake2.dev
kit inject-message my-chat-app:my-chat-app:template.os '{"Send": {"target": "fake.dev", "message": "and second!"}}' -p 8081
# Or, from the terminal running one of the fake nodes:
## First fake node terminal:
m our@my-chat-app:my-chat-app:template.os '{"Send": {"target": "fake2.dev", "message": "hello world"}}'
## Second fake node terminal:
m our@my-chat-app:my-chat-app:template.os '{"Send": {"target": "fake.dev", "message": "wow, it works!"}}'
Next steps
The first chapter of the My First Kinode Application tutorial is a more detailed version of this Quick Start.
Alternatively, you can learn more about kit in the kit documentation.
If instead, you want to learn more about high-level concepts, start with the Introduction and work your way through the book in-order.
Introduction
The Kinode Book describes the Kinode operating system, both in conceptual and practical terms.
Kinode is a decentralized operating system, peer-to-peer app framework, and node network designed to simplify the development and deployment of decentralized applications. It is also a sovereign cloud computer, in that Kinode can be deployed anywhere and act as a server controlled by anyone. Ultimately, Kinode facilitates the writing and distribution of software that runs on privately-held, personal server nodes or node clusters.
Kinode eliminates boilerplate and reduces the complexity of p2p software development by providing four basic and necessary primitives:
| Primitive | Description |
|---|---|
| Networking | Passing messages from peer to peer. |
| Identity | Linking permanent system-wide identities to individual nodes. |
| Data Persistence | Storing data and saving it in perpetuity. |
| Global State | Reading shared global state (blockchain) and composing actions with this state (transactions). |
The focus of this book is how to build and deploy applications on Kinode.
Architecture Overview
Applications are composed of processes, which hold state and pass messages.
Kinode's kernel handles the startup and teardown of processes, as well as message-passing between processes, both locally and across the network.
Processes are programs compiled to Wasm, which export a single init() function.
They can be started once and complete immediately, or they can run "forever".
Peers in Kinode are identified by their onchain username in the "KNS": Kinode Name System, which is modeled after ENS. The modular architecture of the KNS allows for any Ethereum NFT, including ENS names themselves, to generate a unique Kinode identity once it is linked to a KNS entry.
Data persistence and blockchain access, as fundamental primitives for p2p apps, are built directly into the kernel. The filesystem is abstracted away from the developer, and data is automatically persisted across an arbitrary number of encrypted remote backups as configured at the user-system-level. Accessing global state in the form of the Ethereum blockchain is now trivial, with chain reads and writes handled by built-in system runtime modules.
Several other I/O primitives also come with the kernel: an HTTP server and client framework, as well as a simple key-value store. Together, these tools can be used to build performant and self-custodied full-stack applications.
Finally, by the end of this book, you will learn how to deploy applications to the Kinode network, where they will be discoverable and installable by any user with a Kinode.
Kimap and KNS
Kimap is an onchain namespace for the Kinode operating system. It serves as the base-level shared global state that all nodes use to share critical signaling data with the entire network. Kimap is organized as a hierarchical path system and has mutable and immutable keys.
Historically, discoverability of both peers and content has been a major barrier for peer-to-peer developers. Discoverability can present both social barriers (finding a new user on a game or chat) and technical obstacles (automatically acquiring networking information for a particular username). Many solutions have been designed to address this problem, but so far, the ``devex'' (developer experience) of deploying centralized services has continued to outcompete the p2p discoverability options available. Kimap aims to change this by providing a single, shared, onchain namespace that can be used to resolve to arbitrary elements of the Kinode network.
- All keys are strings containing exclusively characters 0-9, a-z (lowercase), - (hyphen) and are at maximum 63 characters long.
- A key may be one of two types, a name-key or a data-key.
- Every name-key may create sub-entries directly beneath it.
- Every name-key is an ERC-7211 NFT (non-fungible token), with a connected token-bound account2 with a counterfactual address.
- The implementation of the token-bound account may be set when a name-key is created.
- If the parent entry of a name-key has a token-bound account implementation set (a "gene"), then the name-key will automatically inherit this implementation.
- Every name-key may inscribe data in data-keys directly beneath it.
- A data-key may be mutable (a "note", prepended with
~) or immutable (a "fact", prepended with!).
https://eips.ethereum.org/EIPS/eip-721
https://ercs.ethereum.org/ERCS/erc-6551
See the Kinode whitepaper for a full specification which goes into detail regarding token-bound accounts, sub-entry management, the use of data keys, and protocol extensibility.
Kimap is tightly integrated into the operating system. At the runtime level, networking identities are verified against the kimap namespace. In userspace, programs such as the App Store make use of kimap by storing and reading data from it to define global state, such as apps available for download.
KNS: Kinode Name System
One of the most important features of a peer-to-peer network is the ability to maintain a unique and persistent identity.
This identity must be self-sovereign, unforgeable, and easy to discover by peers.
Kinode uses a PKI (public-key infrastructure) that runs within kimap to achieve this.
It should be noted that, in our system, the concepts of domain, identity, and username are identical and interchangeable.
Also important to understanding KNS identities is that other onchain identity protocols can be absorbed and supported by KNS. The KNS is not an attempt at replacing or competing with existing onchain identity primitives such as ENS and Lens. This has already been done for ENS protocol.
Kinode names are registered by a wallet and owned in the form of an NFT like any other kimap namespace entry. They contain metadata necessary to cover both:
- Domain provenance - to demonstrate that the NFT owner has provenance of a given Kinode identity.
- Domain resolution - to be able to route messages to a given identity on the Kinode network.
It's easy enough to check for provenance of a given Kinode identity. If you have a Kinode domain, you can prove ownership by signing a message with the wallet that owns the domain. However, to effectively use your Kinode identity as a domain name for your personal server, KNS domains have routing information, similar to a DNS record, that points to an IP address.
Domain Resolution
A KNS identity can either be direct or indirect.
When users first boot a node, they may decide between these two types as they create their initial identity.
Direct nodes share their literal IP address and port in their metadata, allowing other nodes to message them directly.
Again, this is similar to registering a WWW domain name and pointing it at your web server.
However, running a direct node is both technically demanding (you must maintain the ability of your machine to be accessed remotely) and a security risk (you must open ports on the server to the public internet).
Therefore, indirect nodes are the best choice for the majority of users that choose to run their own node.
Instead of sharing their IP and port, indirect nodes simply post a list of routers onchain. These routers are other direct nodes that have agreed to forward messages to indirect nodes. When a node wants to send a message to an indirect node, it first finds the node onchain, and then sends the message to one of the routers listed in the node's metadata. The router is responsible for forwarding the message to the indirect node and similarly forwarding messages from that node back to the network at large.
Specification Within Kimap
The definition of a node identity in the KNS protocol is any kimap entry that has:
- A
~net-keynote AND - Either:
a. A
~routersnote OR b. An~ipnote AND at least one of:~tcp-portnote~udp-portnote~ws-portnote~wt-portnote
Direct nodes are those that publish an ~ip and one or more of the port notes.
Indirect nodes are those that publish ~routers.
The data stored at ~net-key must be 32 bytes corresponding to an Ed25519 public key.
This is a node's signing key which is used across a variety of domains to verify ownership, including in the end-to-end encrypted networking protocol between nodes.
The owner of a namespace entry/node identity may rotate this key at any time by posting a transaction to kimap mutating the data stored at ~net-key.
The bytes at a ~routers entry must parse to an array of UTF-8 strings.
These strings should be node identities.
Each node in the array is treated by other participants in the networking protocol as a router for the parent entry.
Routers should themselves be direct nodes.
If a string in the array is not a valid node identity, or it is a valid node identity but not a direct one, that router will not be used by the networking protocol.
Further discussion of the networking protocol specification can be found here.
The bytes at an ~ip entry must be either 4 or 16 big-endian bytes.
A 4-byte entry represents a 32-bit unsigned integer and is interpreted as an IPv4 address.
A 16-byte entry represents a 128-bit unsigned integer and is interpreted as an IPv6 address.
Lastly, the bytes at any of the following port entries must be 2 big-endian bytes corresponding to a 16-bit unsigned integer:
~tcp-portsub-entry~udp-portsub-entry~ws-portsub-entry~wt-portsub-entry
These integers are translated to port numbers. In practice, port numbers used are between 9000 and 65535. Ports between 8000-8999 are usually saved for HTTP server use.
Design Philosophy
The following is a high-level overview of Kinode's design philosophy, along with the rationale for fundamental design choices.
Decentralized Software Requires a Shared Computing Environment
A single shared computing environment enables software to coordinate directly between users, services, and other pieces of software in a common language. Therefore, the best way to enable decentralized software is to provide an easy-to-use, general purpose node (that can run on anything from laptops to data centers) that runs the same operating system as all other nodes on the network. This environment must integrate with existing protocols, blockchains, and services to create a new set of protocols that operate peer-to-peer within the node network.
Decentralization is Broad
A wide array of companies and services benefit from some amount of decentralized infrastructure, even those operating in a largely centralized context. Additionally, central authority and centralized data are often essential to the proper function of a particular service, including those with decentralized properties. The Kinode environment must be flexible enough to serve the vast majority of the decentralization spectrum.
Blockchains are not Databases
To use blockchains as mere databases would negate their unique value. Blockchains are consensus tools, and exist in a spectrum alongside other consensus strategies such as Raft, lockstep protocols, CRDTs, and simple gossip. All of these are valid consensus schemes, and peer-to-peer software, such as that built on Kinode, must choose the correct strategy for a particular task, program, or application.
Decentralized Software Outcompetes Centralized Software through Permissionlessness and Composability
Therefore, any serious decentralized network must identify and prioritize the features that guarantee permissionless and composable development. Those features include:
- a persistent software environment (software can run forever once deployed)
- client diversity (more actors means fewer monopolies)
- perpetual backwards-compatibility
- a robust node network that ensures individual ownership of software and data
Decentralized Software Requires Decentralized Governance
The above properties are achieved by governance. Successful protocols launched on Kinode will be ones that decentralize their governance in order to maintain these properties. Kinode believes that systems that don't proactively specify their point of control will eventually centralize, even if unintentionally. The governance of Kinode itself must be designed to encourage decentralization, playing a role in the publication and distribution of userspace software protocols. In practice, this looks like an on-chain permissionless App Store.
Good Products Use Existing Tools
Kinode is a novel combination of existing technologies, protocols, and ideas. Our goal is not to create a new programming language or consensus algorithm, but to build a new execution environment that integrates the best of existing tools. Our current architecture relies on the following systems:
- ETH: a trusted execution layer
- Rust: a performant, expressive, and popular programming language
- Wasm: a portable, powerful binary format for executable programs
- Wasmtime: a standalone Wasm runtime
In addition, Kinode is inspired by the Bytecode Alliance and their vision for secure, efficient, and modular software. Kinode makes extensive use of their tools and standards.
Installation
This section will teach you how to get the Kinode core software, required to run a live node. After acquiring the software, you can learn how to run it and Join the Network.
- If you are just interested in starting development as fast as possible, skip to My First Kinode Application.
- If you want to run a Kinode without managing it yourself, use the Valet hosted service.
- If you want to make edits to the Kinode core software, see Build From Source.
Option 1: Download Binary (Recommended)
Kinode core distributes pre-compiled binaries for MacOS and Linux Debian derivatives, like Ubuntu.
First, get the software itself by downloading a precompiled release binary.
Choose the correct binary for your particular computer architecture and OS.
There is no need to download the simulation-mode binary — it is used behind the scenes by kit.
Extract the .zip file: the binary is inside.
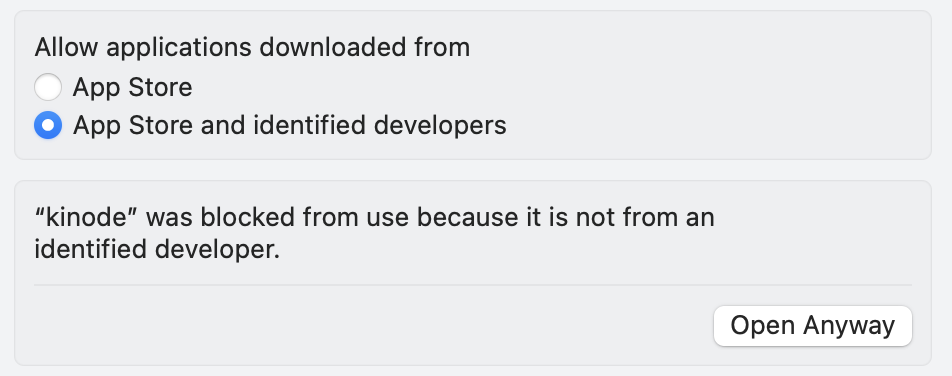
Note that some operating systems, particularly Apple, may flag the download as suspicious.
Apple
First, attempt to run the binary, which Apple will block.
Then, go to System Settings > Privacy and Security and click to Open Anyway for the kinode binary:
Option 2: Docker
Kinode can also be run using Docker. MacOS and Debian derivatives of Linux, like Ubuntu, are supported. Windows may work but is not officially supported.
Installing Docker
First, install Docker. Instructions will be different depending on your OS, but it is recommended to follow the method outlined in the official Docker website.
If you are using Linux, make sure to perform any post-install necessary afterwards. The official Docker website has optional post-install instructions.
Docker Image
The image expects a volume mounted at /kinode-home.
This volume may be empty or may contain another Kinode's data.
It will be used as the home directory of your Kinode.
Each volume is unique to each Kinode.
If you want to run multiple Kinodes, create multiple volumes.
The image includes EXPOSE directives for TCP port 8080 and TCP port 9000.
Port 8080 is used for serving the Kinode web dashboard over HTTP, and it may be mapped to a different port on the host.
Port 9000 is optional and is only required for a direct node.
If you are running a direct node, you must map port 9000 to the same port on the host and on your router.
Otherwise, your Kinode will not be able to connect to the rest of the network.
Run the following command to create a volume:
# Replace this variable with your node's intended name
export NODENAME=helloworld.os
docker volume create kinode-${NODENAME}
Then run the following command to create the container.
Replace kinode-${NODENAME} with the name of your volume if you prefer.
To map the port to a different port (for example, 80 or 6969), change 8080:8080 to PORT:8080, where PORT is the post on the host machine.
docker run -p 8080:8080 --rm -it --name kinode-${NODENAME} \
--mount type=volume,source=kinode-${NODENAME},destination=/kinode-home \
nick1udwig/kinode
which will launch your Kinode container attached to the terminal. Alternatively, you can run it detached:
docker run -p 8080:8080 --rm -dt --name kinode-${NODENAME} \
--mount type=volume,source=kinode-${NODENAME},destination=/kinode-home \
nick1udwig/kinode
Check the status of your Docker processes with docker ps.
To start and stop the container, use docker start kinode-${NODENAME} or docker stop kinode-${NODENAME}.
As long as the volume is not deleted, your data remains intact upon removal or stop. If you need further help with Docker, access the official Docker documentation here.
Option 3: Build From Source
You can compile the binary from source using the following instructions. This is only recommended if:
- The pre-compiled binaries don't work on your system and you can't use Docker for some reason, or
- You need to make changes to the Kinode core source.
Acquire Dependencies
If your system doesn't already have cmake and OpenSSL, download them:
Linux
sudo apt-get install cmake libssl-dev
Mac
brew install cmake openssl
Acquire Rust and various tools
Install Rust and some cargo tools, by running the following in your terminal:
curl --proto '=https' --tlsv1.2 -sSf https://sh.rustup.rs | sh
cargo install wasm-tools
rustup install nightly
rustup target add wasm32-wasip1 --toolchain nightly
cargo install cargo-wasi
For more information, or debugging, see the Rust lang install page.
Kinode uses the stable build of Rust, but the Wasm processes use the nightly build of Rust..
You will want to run the command rustup update on a regular basis to keep your version of the language current, especially if you run into issues compiling the runtime down the line.
You will also need to install NPM in order to build the Wasm processes that are bundled with the core binary.
Acquire Kinode core
Clone and set up the repository:
git clone https://github.com/kinode-dao/kinode.git
Build the packages that are bundled with the binary:
cargo run -p build-packages
Build the binary:
# OPTIONAL: --release flag
cargo build -p kinode
The resulting binary will be at path kinode/target/debug/kinode.
(Note that this is the binary crate inside the kinode workspace.)
You can also build the binary with the --release flag.
Building without --release will produce the binary significantly faster, as it does not perform any optimizations during compilation, but the node will run much more slowly after compiling.
The release binary will be at path kinode/target/release/kinode.
Join the Network
This page discusses joining the network with a locally-run Kinode. To instead join with a hosted node, see Valet.
These directions are particular to the Kinode beta release. Kinode is in active development on Optimism.
Starting the Kinode
Start a Kinode using the binary acquired in the previous section.
Locate the binary on your system (e.g., if you built source yourself, the binary will be in the repository at ./kinode/target/debug/kinode or ./kinode/target/release/kinode).
Print out the arguments expected by the binary:
$ ./kinode --help
A General Purpose Sovereign Cloud Computing Platform
Usage: kinode [OPTIONS] <home>
Arguments:
<home> Path to home directory
Options:
-p, --port <PORT>
Port to bind [default: first unbound at or above 8080]
--ws-port <PORT>
Kinode internal WebSockets protocol port [default: first unbound at or above 9000]
--tcp-port <PORT>
Kinode internal TCP protocol port [default: first unbound at or above 10000]
-v, --verbosity <VERBOSITY>
Verbosity level: higher is more verbose [default: 0]
-l, --logging-off
Run in non-logging mode (toggled at runtime by CTRL+L): do not write all terminal output to file in .terminal_logs directory
--reveal-ip
If set to false, as an indirect node, always use routers to connect to other nodes.
-d, --detached
Run in detached mode (don't accept input)
--rpc <RPC>
Add a WebSockets RPC URL at boot
--password <PASSWORD>
Node password (in double quotes)
--max-log-size <MAX_LOG_SIZE_BYTES>
Max size of all logs in bytes; setting to 0 -> no size limit (default 16MB)
--number-log-files <NUMBER_LOG_FILES>
Number of logs to rotate (default 4)
--max-peers <MAX_PEERS>
Maximum number of peers to hold active connections with (default 32)
--max-passthroughs <MAX_PASSTHROUGHS>
Maximum number of passthroughs serve as a router (default 0)
--soft-ulimit <SOFT_ULIMIT>
Enforce a static maximum number of file descriptors (default fetched from system)
--process-verbosity <JSON_STRING>
ProcessId: verbosity JSON object [default: ]
-h, --help
Print help
-V, --version
Print version
A home directory must be supplied — where the node will store its files.
The --rpc flag is an optional wss:// WebSocket link to an Ethereum RPC, allowing the Kinode to send and receive Ethereum transactions — used in the identity system as mentioned above.
If this is not supplied, the node will use a set of default RPC providers served by other nodes on the network.
If the --port flag is supplied, Kinode will attempt to bind that port for serving HTTP and will exit if that port is already taken.
If no --port flag is supplied, Kinode will bind to 8080 if it is available, or the first port above 8080 if not.
OPTIONAL: Acquiring an RPC API Key
Acquiring an RPC API Key
Create a new "app" on Alchemy for Optimism Mainnet.

Copy the WebSocket API key from the API Key button:

Alternative to Alchemy
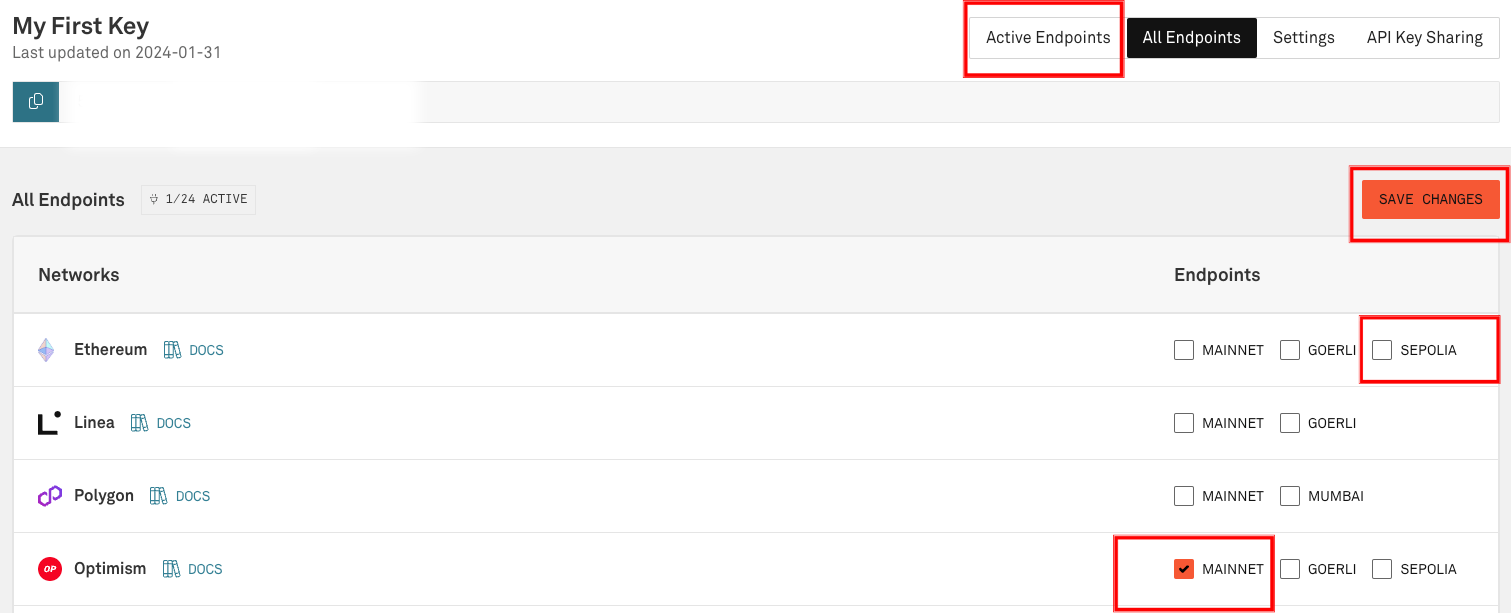
As an alternative to using Alchemy's RPC API key, Infura's endpoints may be used. Upon creating an Infura account, the first key is already created and titled 'My First Key'. Click on the title to edit the key.

Next, check the box next to Optimism "MAINNET". After one is chosen, click "SAVE CHANGES". Then, at the top, click "Active Endpoints".
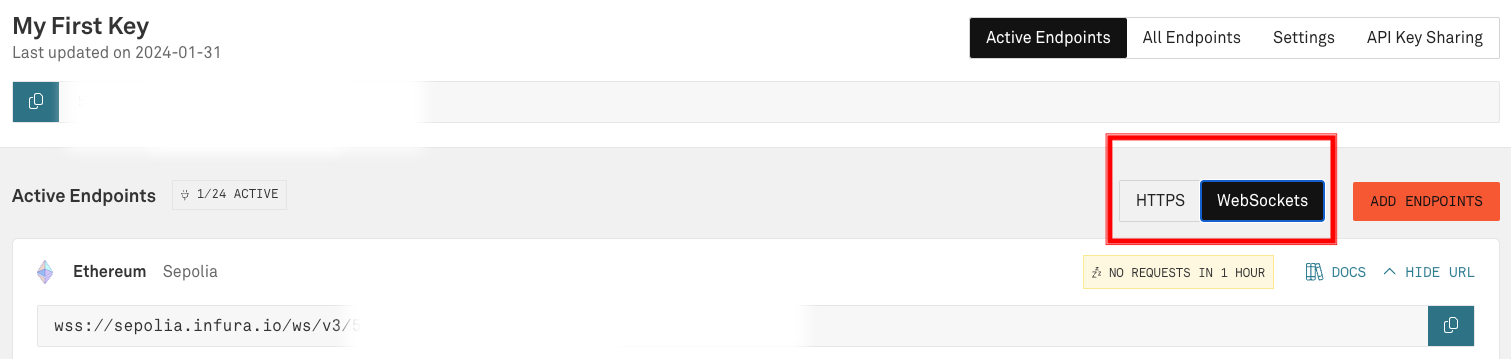
On the "Active Endpoints" tab, there are tabs for "HTTPS" and "WebSockets". Select the WebSockets tab. Copy this endpoint and use it in place of the Alchemy endpoint in the following step, "Running the Binary".
Running the Binary
In a terminal window, run:
./kinode path/to/home
where path/to/home is the directory where you want your new node's files to be placed, or, if booting an existing node, is that node's existing home directory.
A new browser tab should open, but if not, look in the terminal for this line:
login or register at http://localhost:8080
and open that localhost address in a web browser.
Registering an Identity
Next, register an identity.
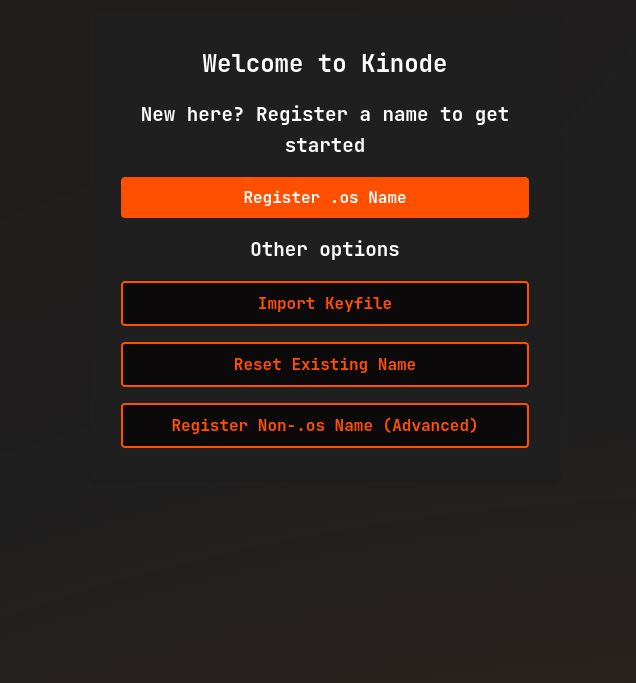
Click Register .os Name.
If you've already got a wallet, proceed to Connecting the Wallet.
Otherwise, you're going to need to Acquire a Wallet.
Aside: Acquiring a Wallet
To register an identity, Kinode must send an Ethereum transaction, which requires ETH and a cryptocurrency wallet. While many wallets will work, the examples below use Metamask. Install Metamask here if you don't already have it.
Connecting the Wallet
After clicking Register .os Name, follow the prompts in the Connect a Wallet modal (if you haven't already connected a wallet):

Aside: Bridging ETH to Optimism
Bridge ETH to Optimism using the official bridge. Many exchanges also allow sending ETH directly to Optimism wallets.
Setting Up Networking (Direct vs. Routed Nodes)
When registering on Kinode, you may choose between running a direct or indirect (routed) node. Most users should use an indirect node. To do this, simply leave the box below name registration unchecked.
An indirect node connects to the network through a router, which is a direct node that serves as an intermediary, passing packets from sender to receiver. Routers make connecting to the network convenient, and so are the default. If you are connecting from a laptop that isn't always on, or that changes WiFi networks, use an indirect node.
A direct node connects directly, without intermediary, to other nodes (though they may, themselves, be using a router). Direct nodes may have better performance, since they remove middlemen from connections. Direct nodes also reduces the number of third parties that know about the connection between your node and your peer's node (if both you and your peer use direct nodes, there will be no third party involved).
Use an indirect node unless you are familiar with running servers. A direct node must be served from a static IP and port, since these are registered on the Ethereum network and are how other nodes will attempt to contact you.
Regardless, all packets, passed directly or via a router, are end-to-end encrypted. Only you and the recipient can read messages.
As a direct node, your IP is published on the blockchain. As an indirect node, only your router knows your IP.
Sending the Registration Transaction
After clicking Register .os name, click through the wallet prompts to send the transaction:
You'll see your node name being pre-committed, and then will send another transaction to mint:
What Does the Password Do?
Finally, you'll set your password.
The password encrypts the node's networking key. The networking key is how your node communicates securely with other nodes, and how other nodes can be certain that you are who you say you are.
Welcome to the Network
After setting the node password, you will be greeted with the homepage.

Try downloading, installing, and using some apps on the App Store. Come ask for recommendations in the Kinode Discord!
System Components
This section describes the various components of the system, including the processes, networking protocol, public key infrastructure, HTTP server and client, files, databases, and terminal.
Processes
Processes are independent pieces of Wasm code running on Kinode. They can either be persistent, in which case they have in-memory state, or temporary, completing some specific task and returning. They have access to long-term storage, like the filesystem or databases. They can communicate locally and over the Kinode network. They can access the internet via HTTP or WebSockets. And these abilities can be controlled using a capabilities security model.
Process Semantics
Overview
On Kinode, processes are the building blocks for peer-to-peer applications. The Kinode runtime handles message-passing between processes, plus the startup and teardown of said processes. This section describes the message design as it relates to processes.
Each process instance has a globally unique identifier, or Address, composed of four elements.
- the publisher's node (containing a-z, 0-9,
-, and.) - the package name (containing a-z, 0-9, and
-) - the process name (containing a-z, 0-9, and
-). This may be a developer-selected string or a randomly-generated number as string. - the node the process is running on (often your node:
ourfor short).
A package is a set of one or more processes and optionally GUIs: a package is synonymous with an App and packages are distributed via the built-in App Store.
The way these elements compose is the following:
PackageIds look like:
[package-name]:[publisher-node]
my-cool-software:publisher-node.os
ProcessIds look like:
[process-name]:[package-name]:[publisher-node]
process-one:my-cool-software:publisher-node.os
8513024814:my-cool-software:publisher-node.os
Finally, Addresses look like:
[node]@[process-name]:[package-name]:[publisher-node]
some-user.os@process-one:my-cool-software:publisher-node.os
Processes are compiled to Wasm. They can be started once and complete immediately, or they can run forever. They can spawn other processes, and coordinate in arbitrarily complex ways by passing messages to one another.
Process State
Kinode processes can be stateless or stateful. In this case, state refers to data that is persisted between process instantiations. Nodes get turned off, intentionally or otherwise. The kernel handles rebooting processes that were running previously, but their state is not persisted by default.
Instead, processes elect to persist data, and what data to persist, when desired. Data might be persisted after every message ingested, after every X minutes, after a certain specific event, or never. When data is persisted, the kernel saves it to our abstracted filesystem, which not only persists data on disk, but also across arbitrarily many encrypted remote backups as configured at the user-system-level.
This design allows for ephemeral state that lives in-memory, or truly permanent state, encrypted across many remote backups, synchronized and safe.
Processes have access to multiple methods for persisting state:
- Saving a state object with the system calls available to every process, seen here.
- Using the virtual filesystem to read and write from disk, useful for persisting state that needs to be shared between processes.
- Using the SQLite or KV APIs to persist state in a database.
Requests and Responses
Processes communicate by passing messages, of which there are two kinds: Requests and Responses.
Addressing
When a Request or Response is received, it has an attached Address, which consists of: the source of the message, including the ID of the process that produced the Request, as well as the ID of the originating node.
The integrity of a source Address differs between local and remote messages.
If a message is local, the validity of its source is ensured by the local kernel, which can be trusted to label the ProcessId and node ID correctly.
If a message is remote, only the node ID can be validated (via networking keys associated with each node ID).
The ProcessId comes from the remote kernel, which could claim any ProcessId.
This is fine — merely consider remote ProcessIds a claim about the initiating process rather than an infallible ID like in the local case.
Please Respond
Requests can be issued at any time by a running process.
A Request can optionally expect a Response.
If it does, the Request will be retained by the kernel, along with an optional context object created by the Requests issuer.
A Request will be considered outstanding until the kernel receives a matching Response, at which point that Response will be delivered to the requester alongside the optional context.
contexts allow Responses to be disambiguated when handled asynchronously, for example, when some information about the Request must be used in handling the Response.
Responses can also be handled in an async-await style, discussed below.
Requests that expect a Response set a timeout value, after which, if no Response is received, the initial Request is returned to the process that issued it as an error.
Send errors are handled in processes alongside other incoming messages.
Inheriting a Response
If a process receives a Request, that doesn't mean it must directly issue a Response.
The process can instead issue Request(s) that "inherit" from the incipient Request, continuing its lineage.
If a Request does not expect a Response and also "inherits" from another Request, Responses to the child Request will be returned to the parent Requests issuer.
This allows for arbitrarily complex Request-Response chains, particularly useful for "middleware" processes.
There is one other use of inheritance, discussed below: passing data in Request chains cheaply.
Awaiting a Response
When sending a Request, a process can await a Response to that specific Request, queueing other messages in the meantime.
Awaiting a Response leads to easier-to-read code:
- The
Responseis handled in the next line of code, rather than in a separate iteration of the message-handling loop - Therefore, the
contextneed not be set.
The downside of awaiting a Response is that all other messages to a process will be queued until that Response is received and handled.
As such, certain applications lend themselves to blocking with an await, and others don't.
A rule of thumb is: await Responses (because simpler code) except when a process needs to performantly handle other messages in the meantime.
For example, if a file-transfer process can only transfer one file at a time, Requests can simply await Responses, since the only possible next message will be a Response to the Request just sent.
In contrast, if a file-transfer process can transfer more than one file at a time, Requests that await Responses will block others in the meantime; for performance it may make sense to write the process fully asynchronously, i.e. without ever awaiting.
The constraint on awaiting is a primary reason why it is desirable to spawn child processes.
Continuing the file-transfer example, by spawning one child "worker" process per file to be transferred, each worker can use the await mechanic to simplify the code, while not limiting performance.
There is more discussion of child processes here, and an example of them in action in the file-transfer cookbook.
Message Structure
Messages, both Requests and Responses, can contain arbitrary data, which must be interpreted by the process that receives it.
The structure of a message contains hints about how best to do this:
First, messages contain a field labeled body, which holds the actual contents of the message.
In order to cross the Wasm boundary and be language-agnostic, the body field is simply a byte vector.
To achieve composability between processes, a process should be very clear, in code and documentation, about what it expects in the body field and how it gets parsed, usually into a language-level struct or object.
A message also contains a lazy_load_blob, another byte vector, used for opaque, arbitrary, or large data.
lazy_load_blobs, along with being suitable location for miscellaneous message data, are an optimization for shuttling messages across the Wasm boundary.
Unlike other message fields, the lazy_load_blob is only moved into a process if explicitly called with (get_blob()).
Processes can thus choose whether to ingest a lazy_load_blob based on the body/metadata/source/context of a given message.
lazy_load_blobs hold bytes alongside a mime field for explicit process-and-language-agnostic format declaration, if desired.
See inheriting a lazy_load_blob for a discussion of why lazy loading is useful.
Lastly, messages contain an optional metadata field, expressed as a JSON-string, to enable middleware processes and other such things to manipulate the message without altering the body itself.
Inheriting a lazy_load_blob
The reason lazy_load_blobs are not automatically loaded into a process is that an intermediate process may not need to access the blob.
If process A sends a message with a blob to process B, process B can send a message that inherits to process C.
If process B does not attach a new lazy_load_blob to that inheriting message, the original blob from process A will be attached and accessible to C.
For example, consider again the file-transfer process discussed above.
Say one node, send.os, is transferring a file to another node, recv.os.
The process of sending a file chunk will look something like:
recv.ossends aRequestfor chunk Nsend.osreceives theRequestand itself makes aRequestto the filesystem for the piece of the filesend.osreceives aResponsefrom the filesystem with the piece of the file in thelazy_load_blob;send.ossends aResponsethat inherits the blob back torecv.oswithout itself having to load the blob, saving the compute and IO required to move the blob across the Wasm boundary.
This is the second functionality of inheritance; the first is discussed above: eliminating the need for bucket-brigading of Responses.
Errors
Messages that result in networking failures, like Requests that timeout, are returned to the process that created them as an error.
There are only two kinds of send errors: Offline and Timeout.
Offline means a message's remote target definitively cannot be reached.
Timeout is multi-purpose: for remote nodes, it may indicate compromised networking; for both remote and local nodes, it may indicate that a process is simply failing to respond in the required time.
A send error will return to the originating process the initial message, along with any optional context, so that the process can re-send the message, crash, or otherwise handle the failure as the developer desires.
If the error results from a Response, the process may optionally try to re-send a Response: it will be directed towards the original outstanding Request.
Capabilities
Processes must acquire capabilities from the kernel in order to perform certain operations. Processes themselves can also produce capabilities in order to give them to other processes. For more information about the general capabilities-based security paradigm, see the paper "Capability Myths Demolished".
The kernel gives out capabilities that allow a process to message another local process.
It also gives a capability allowing processes to send and receive messages over the network.
A process can optionally mark itself as public, meaning that it can be messaged by any local process regardless of capabilities.
See the capabilities chapter for more details.
Spawning child processes
A process can spawn "child" processes — in which case the spawner is known as the "parent". As discussed above, one of the primary reasons to write an application with multiple processes is to enable both simple code and high performance.
Child processes can be used to:
- Run code that may crash without risking crashing the parent
- Run compute-heavy code without blocking the parent
- Run IO-heavy code without blocking the parent
- Break out code that is more easily written with awaits to avoid blocking the parent
There is more discussion of child processes here, and an example of them in action in the file-transfer cookbook.
Conclusion
This is a high-level overview of process semantics. In practice, processes are combined and shared in packages, which are generally synonymous with apps.
Wasm and Kinode
It's briefly discussed here that processes are compiled to Wasm. The details of this are not covered in the Kinode Book, but can be found in the documentation for the Kinode runtime, which uses Wasmtime, a WebAssembly runtime, to load, execute, and provide an interface for the subset of Wasm components that are valid Kinode processes.
Wasm runs modules by default, or components, as described here: components are just modules that follow some specific format.
Kinode processes are Wasm components that have certain imports and exports so they can be run by Kinode.
Pragmatically, processes can be compiled using the kit tools.
The long term goal of Kinode is, using WASI, to provide a secure, sandboxed environment for Wasm components to make use of the kernel features described in this document. Further, Kinode has a Virtual File System (VFS) which processes can interact with to access files on a user's machine, and in the future WASI could also expose access to the filesystem for Wasm components directly.
Capability-Based Security
Capabilities are a security paradigm in which an ability that is usually handled as a permission (i.e. certain processes are allowed to perform an action if they are saved on an "access control list") are instead handled as a token (i.e. the process that possesses token can perform a certain action). These unforgeable tokens (as enforced by the kernel) can be passed to other owners, held by a given process, and checked for.
On Kinode, each process has an associated set of capabilities, which are each represented internally as an arbitrary JSON object with a source process:
#![allow(unused)] fn main() { pub struct Capability { pub issuer: Address, pub params: String, // JSON-string } }
The kernel abstracts away the process of ensuring that a capability is not forged. As a process developer, if a capability comes in on a message or is granted to you by the kernel, you are guaranteed that it is legitimate.
Runtime processes, including the kernel itself, the filesystem, and the HTTP client, issue capabilities to processes. Then, when a request is made by a process, the responder verifies the process's capability. If the process does not have the capability to make such a request, it will be denied.
To give a concrete example: the filesystem can read/write, and it has the capabilities for doing so. The FS may issue capabilities to processes to read/write to certain drives. A process can request to read/write somewhere, and then the FS checks if that process has the required capability. If it does, the FS does the read/write; if not, the request will be denied.
System level capabilities like the above can only be given when a process is first installed.
Startup Capabilities with manifest.json
When developing an application, manifest.json will be your first encounter with capabilties. With this file, capabilities are directly granted to a process on startup.
Upon install, the package manager (also referred to as "app store") surfaces these requested capabilities to the user, who can then choose to grant them or not.
Here is a manifest.json example for the chess app:
[
{
"process_name": "chess",
"process_wasm_path": "/chess.wasm",
"on_exit": "Restart",
"request_networking": true,
"request_capabilities": [
"net:distro:sys"
],
"grant_capabilities": [
"http-server:distro:sys"
],
"public": true
}
]
By setting request_networking: true, the kernel will give it the "networking" capability. In the request_capabilities field, chess is asking for the capability to message net:distro:sys.
Finally, in the grant_capabilities field, it is giving http-server:distro:sys the ability to message chess.
When booting the chess app, all of these capabilities will be granted throughout your node.
If you were to print out chess' capabilities using kinode_process_lib::our_capabilities() -> Vec<Capability>, you would see something like this:
#![allow(unused)] fn main() { [ // obtained because of `request_networking: true` Capability { issuer: "our-node.os@kernel:distro:sys", params: "\"network\"" }, // obtained because we asked for it in `request_capabilities` Capability { issuer: "our-node.os@net:distro:sys", params: "\"messaging\"" } ] }
Note that userspace capabilities, those created by other processes, can also be requested in a package manifest, though it's not guaranteed that the user will have installed the process that can grant the capability.
Therefore, when a userspace process uses the capabilities system, it should have a way to grant capabilities through its body protocol, as described below.
Userspace Capabilities
While the manifest fields are useful for getting a process started, it is not sufficient for creating and giving custom capabilities to other processes.
To create your own capabilities, simply declare a new one and attach it to a Request or Response like so:
#![allow(unused)] fn main() { let my_new_cap = kinode_process_lib::Capability::new(our, "\"my-new-capability\""); Request::new() .to(a_different_process) .capabilities(vec![my_new_cap]) .send(); }
On the other end, if a process wants to save and reuse that capability, they can do something like this:
#![allow(unused)] fn main() { kinode_process_lib::save_capabilities(req.capabilities); }
This call will automatically save the caps for later use.
Next time you attach this capability to a message, whether that is for authentication with the issuer, or to share it with another process, it will reach the other side just fine, and they can check it using the exact same flow.
For a code example of creating and using capabilities in userspace, see this cookbook recipe.
Startup, Spindown, and Crashes
Along with learning how processes communicate, understanding the lifecycle paradigm of Kinode processes is essential to developing useful p2p applications.
Recall that a 'package' is a userspace construction that contains one or more processes.
The Kinode kernel is only aware of processes.
When a process is first initialized, its compiled Wasm code is loaded into memory and, if the code is valid, the process is added to the kernel's process table.
Then, the kernel starts the process by calling the init() function (which is common to all processes).
This scenario is identical to when a process is re-initialized after being shut down. From the perspective of both the kernel and the process code, there is no difference.
Defining Exit Behavior
In the capabilities chapter, we saw manifest.json used to request and grant capabilities to a process. Another field in the manifest is on_exit, which defines the behavior of the process when it exits.
There are three possible behaviors for a process when it exits:
-
OnExit::None- The process is not restarted and nothing happens. -
OnExit::Restart- The process is restarted. -
OnExit::Requests- The process is not restarted, and a list of requests set by the process are fired off. These requests have thesourceandcapabilitiesof the exiting process.
Once a process has been initialized it can exit in 4 ways:
- Process code executes to completion --
init()returns. - Process code panics for any reason.
- The kernel shuts it down via
KillProcesscall. - The runtime shuts it down via graceful exit or crash.
In the event of a runtime exit the process often is best suited by restarting on the next boot. But this should be optional. This is the impetus for OnExit::Restart and OnExit::None. However, OnExit::Requests is also useful in this case, as the process can notify the appropriate services (which restarted, most likely) that it has exited.
If a process is killed by the kernel, it doesn't make sense to honor OnExit::Restart. This would reduce the strength of KillProcess and forces a full package uninstall to get it to stop running. Therefore, OnExit::Restart is treated as OnExit::None in this case only.
NOTE: If a process crashes for a 'structural' reason, i.e. the process code leads directly to a panic, and uses OnExit::Restart, it will crash continuously until it is uninstalled or killed manually.
Be careful of this!
The kernel waits an exponentially-increasing time between process restarts to avoid DOSing iteself with a crash-looping process.
If a process executes to completion, its exit behavior is always honored.
Thus we can rewrite the three possible OnExit behaviors with their full accurate logic:
-
OnExit::None- The process is not restarted and nothing happens -- no matter what. -
OnExit::Restart- The process is restarted, unless it was killed by the kernel, in which case it is treated asOnExit::None. -
OnExit::Requests- The process is not restarted, and a list ofRequests set by the process are fired off. TheseRequests have thesourceandcapabilitiesof the exiting process. If the target process of a givenRequestin the list is no longer running, theRequestwill be dropped.
Implications
Here are some good practices for working with these behaviors:
-
When a process has
OnExit::Restartas its behavior, it should be written in such a way that it can restart at any time. This means that theinit()function should start by picking up where the process may have left off, for example, reading from a local database that the process uses, or re-establishing an ETH RPC subscription (and making sure toget_logsfor any events that may have been missed!). -
Processes that produce 'child' processes should handle the exit behavior of those children. A parent process should usually use
OnExit::Restartas its behavior unless it intends to hand off the child processes to another process via some established API. A child process can useNone,Restart, orRequests, depending on its needs. -
If a child process uses
OnExit::None, the parent must be aware that the child could exit at any time and not notify the parent. This can be fine and easy to deal with if the parent has outstandingRequests to the child and can assume failure on timeout, or if the work-product of the child is irrelevant to the continued operations of the parent. -
If a child process uses
OnExit::Restart, the parent must be aware that the child will persist itself indefinitely. This is a natural fit for long-lived child processes which engage in cross-network activity and are themselves presenting a useful API. However, likeOnExit::None, the parent will not be notified if the child process is manually killed. Again, the parent should be programmed to consider this. -
If a child process uses
OnExit::Requests, it has the ability to notify the parent process when it exits. This is quite useful for child processes that create a work-product to return to the parent or if it is important that the parent do some action immediately upon the child's exit. Note that the programmer must create theRequests in the child process. They can target any process, as long as the child process has the capability to message that target. The target will often simply be the parent process. -
Requests made in
OnExit::Requestsmust also comport to the capabilities requirements that applied to the process when it was alive. -
If your processes does not have any places that it can panic, you don't have to worry about crash behavior, Rust is good for this :)
-
Parent processes "kill" child processes by building in a
Requesttype that the child will respond to by exiting, which the parent can then send. The kernel does not actually have any conception of hierarchical process relationships. The actual kernelKillProcesscommand requires root capabilities to use, and it is unlikely that your app will acquire those.
Persisting State With Processes
Given that Kinodes can, comporting with the realities of the physical world, be turned off, a well-written process must withstand being shut down and re-initialized at any time.
This raises the question: how does a process persist information between initializations?
There are two ways: either the process can use the built-in set_state and get_state functions, or it can send data to a process that does this for them.
The first option is a maximally-simple way to write some bytes to disk (where they'll be backed up, if the node owner has configured that behavior). The second option is vastly more general, because runtime modules, which can be messaged directly from custom userspace processes, offer any number of APIs. So far, there are three modules built into Kinode that are designed for persisted data: a filesystem, a key-value store, and a SQLite database.
Each of these modules offer APIs accessed via message-passing and write data to disk. Between initializations of a process, this data remains saved, even backed up. The process can then retrieve this data when it is re-initialized.
Extensions
Extensions supplement and compliment Kinode processes. Kinode processes have many features that make them good computational units, but they also have constraints. Extensions remove the constraints (e.g., not all libraries can be built to Wasm) while maintaining the advantages (e.g., the integration with the Kinode Request/Response system). The cost of extensions is that they are not as nicely bundled within the Kinode system: they must be run separately.
What is an Extension?
Extensions are WebSocket clients that connect to a paired Kinode process to extend library, language, or hardware support.
Kinode processes are Wasm components, which leads to advantages and disadvantages. The rest of the book (and in particular the processes chapter) discusses the advantages (e.g., integration with the Kinode Request/Response system and the capabilities security model). Two of the main disadvantages are:
- Only certain libraries and languages can be used.
- Hardware accelerators like GPUs are not easily accessible.
Extensions solve both of these issues, since an extension runs natively. Any language with any library supported by the bare metal host can be run as long as it can speak WebSockets.
Downsides of Extensions
Extensions enable use cases that pure processes lack. However, they come with a cost. Processes are contained and managed by your Kinode, but extensions are not. Extensions are independent servers that run alongside your Kinode. They do not yet have a Kinode-native distribution channel.
As such, extensions should only be used when absolutely necessary. Processes are more stable, maintainable, and easily upgraded. Only write an extension if there is no other choice.
How to Write an Extension?
An extension is composed of two parts: a Kinode package and the extension itself. They communicate with each other over a WebSocket connection that is managed by Kinode. Look at the Talking to the Outside World recipe for an example. The examples below show some more working extensions.
The WebSocket protocol
The process binds a WebSocket, so Kinode acts as the WebSocket server. The extension acts as a client, connecting to the WebSocket served by the Kinode process.
The process sends HttpServerAction::WebSocketExtPushOutgoing Requests to the http-server(look here and here) to communicate with the extension (see the enum defined at the bottom of this section).
Table 1: HttpServerAction::WebSocketExtPushOutgoing Inputs
| Field Name | Description |
|---|---|
channel_id | Given in a WebSocket message after a client connects. |
message_type | The WebSocketMessage type — recommended to be WsMessageType::Binary. |
desired_reply_type | The Kinode MessageType type that the extension should return — Request or Response. |
The lazy_load_blob is the payload for the WebSocket message.
The http-server converts the Request into a HttpServerAction::WebSocketExtPushData, MessagePacks it, and sends it to the extension.
Specifically, it attaches the Message's id, copies the desired_reply_type to the kinode_message_type field, and copies the lazy_load_blob to the blob field.
The extension replies with a MessagePacked HttpServerAction::WebSocketExtPushData.
It should copy the id and kinode_message_type of the message it is serving into those same fields of the reply.
The blob is the payload.
#![allow(unused)] fn main() { pub enum HttpServerAction { //... /// When sent, expects a `lazy_load_blob` containing the WebSocket message bytes to send. /// Modifies the `lazy_load_blob` by placing into `WebSocketExtPushData` with id taken from /// this `KernelMessage` and `kinode_message_type` set to `desired_reply_type`. WebSocketExtPushOutgoing { channel_id: u32, message_type: WsMessageType, desired_reply_type: MessageType, }, /// For communicating with the ext. /// Kinode's http-server sends this to the ext after receiving `WebSocketExtPushOutgoing`. /// Upon receiving reply with this type from ext, http-server parses, setting: /// * id as given, /// * message type as given (Request or Response), /// * body as HttpServerRequest::WebSocketPush, /// * blob as given. WebSocketExtPushData { id: u64, kinode_message_type: MessageType, blob: Vec<u8>, }, //... } }
The Package
The package is, minimally, a single process that serves as interface between Kinode and the extension. Each extension must come with a corresponding Kinode package.
Specifically, the interface process must:
- Bind an extension WebSocket: this will be used to communicate with the extension.
- Handle Kinode messages: e.g., Requests to be passed to the extension for processing.
- Handle WebSocket messages: these will come from the extension.
'Interface process' will be used interchangeably with 'package' throughout this page.
Bind an Extension WebSocket
The kinode_process_lib provides an easy way to bind an extension WebSocket:
kinode_process_lib::http::bind_ext_path("/")?;
which, for a process with process ID process:package:publisher.os, serves a WebSocket server for the extension to connect to at ws://localhost:8080/process:package:publisher.os.
Passing a different endpoint like bind_ext_path("/foo") will append to the WebSocket endpoint like ws://localhost:8080/process:package:publisher.os/foo.
Handle Kinode Messages
Like any Kinode process, the interface process must handle Kinode messages. These are how other Kinode processes will make Requests that are served by the extension:
- Process A sends Request.
- Interface process receives Request, optionally does some logic, sends Request on to extension via WS.
- Extension does computation, replies on WS.
- Interface process receives Response, optionally does some logic, sends Response on to process A.
The WebSocket protocol section above discusses how to send messages to the extension over WebSockets.
Briefly, a HttpServerAction::WebSocketExtPushOutgoing Request is sent to the http-server, with the payload in the lazy_load_blob.
It is recommended to use the following protocol:
- Use the
WsMessageType::BinaryWebSocket message type and use MessagePack to (de)serialize your messages. MessagePack is space-efficient and well supported by a variety of languages. Structs, dictionaries, arrays, etc. can be (de)serialized in this way. The extension must support MessagePack anyways, since theHttpServerAction::WebSocketExtPushDatais (de)serialized using it. - Set
desired_reply_typetoMessageType::Responsetype. Then the extension can indicate its reply is a Response, which will allow your Kinode process to properly route it back to the original requestor. - If possible, the original requestor should serialize the
lazy_load_blob, and the type oflazy_load_blobshould be defined accordingly. Then, all the interface process needs to do isinheritthelazy_load_blobin itshttp-serverRequest. This increases efficiency since it avoids bringing those bytes across the Wasm boundry between the process and the runtime (see more discussion here).
Handle WebSocket Messages
At a minimum, the interface process must handle:
Table 2: HttpServerRequest Variants
HttpServerRequest variant | Description |
|---|---|
WebSocketOpen | Sent when an extension connects. Provides the channel_id of the WebSocket connection, needed to message the extension: store this! |
WebSocketClose | Sent when the WebSocket closes. A good time to clean up the old channel_id, since it will no longer be used. |
WebSocketPush | Used for sending payloads between interface and extension. |
Although the extension will send a HttpServerAction::WebSocketExtPushData, the http-server converts that into a HttpServerRequest::WebSocketPush.
The lazy_load_blob then contains the payload from the extension, which can either be processed in the interface or inherited and passed back to the original requestor process.
The Extension
The extension is, minimally, a WebSocket client that connects to the Kinode interface process. It can be written in any language and it is run natively on the host as a "side car" — a separate binary.
The extension should first connect to the interface process.
The recommended pattern is to then iteratively accept and process messages from the WebSocket.
Messages come in as MessagePack'd HttpServerAction::WebSocketExtPushData and must be replied to in the same format.
The blob field is recommended to also be MessagePack'd.
The id and kinode_message_type should be mirrored by the extension: what it receives in those fields should be copied in its reply.
Examples
Find some working examples of runtime extensions below:
WIT APIs
This document describes how Kinode processes use WIT to export or import APIs at a conceptual level. If you are interested in usage examples, see the Package APIs recipe.
High-level Overview
Kinode runs processes that are WebAssembly components, as discussed elsewhere. Two key advantages of WebAssembly components are
- The declaration of types and functions using the cross-language Wasm Interface Type (WIT) language
- The composibility of components. See discussion here.
Kinode processes make use of these two advantages.
Processes within a package — a group of processes, also referred to as an app — may define an API in WIT format.
Each process defines a WIT interface; the package defines a WIT world.
The API is published alongside the package.
Other packages may then import and depend upon that API, and thus communicate with the processes in that package.
The publication of the API also allows for easy inspection by developers or by machines, e.g., LLM agents.
More than types can be published. Because components are composable, packages may publish, along with the types in their API, library functions that may be of use in interacting with that package. When set as as a dependency, these functions will be composed into new packages. Libraries unassociated with packages can also be published and composed.
WIT for Kinode
The following is a brief discussion of the WIT language for use in writing Kinode package APIs. A more full discussion of the WIT language is here.
Conventions
WIT uses kebab-case for multi-word variable names.
WIT uses // C-style comments.
Kinode package APIs must be placed in the top-level api/ directory.
They have a name matching the PackageId and appended with a version number, e.g.,
$ tree chat
chat
├── api
│ └── chat:template.os-v0.wit
...
What WIT compiles into
WIT compiles into types of your preferred language.
Kinode currently recommends Rust, but also supports Python and Javascript, with plans to support C/C++ and JVM languages like Java, Scala, and Clojure.
You can see the code generated by your WIT file using the wit-bindgen CLI.
For example, to generate the Rust code for the app-store API in Kinode core, use, e.g.,
kit b app-store
wit-bindgen rust -w app-store-sys-v1 --generate-unused-types --additional_derive_attribute serde::Deserialize app-store/app-store/target/wit
In the case of Rust, kebab-case WIT variable names become UpperCamelCase.
Rust derive macros can be applied to the WIT types in the wit_bindgen::generate! macro that appears in each process.
A typical macro invocation looks like
#![allow(unused)] fn main() { wit_bindgen::generate!({ path: "target/wit", world: "chat-template-dot-os-v0", generate_unused_types: true, additional_derives: [serde::Deserialize, serde::Serialize, process_macros::SerdeJsonInto], }); }
where the field of interest here is the additional_derives.
Types
The built-in types of WIT closely mirror Rust's types, with the exception of sets and maps.
Users can define struct-like types called records, and enum-like types called variants.
Users can also define funcs with function signatures.
Interfaces
interfaces define a set of types and functions and, in Kinode, are how a process signals its API.
Worlds
worlds define a set of imports and exports and, in Kinode, correspond to a package's API.
They can also include other worlds, copying that worlds imports and exports.
An export is an interface that a package defines and makes available, while an import is an interface that must be made available to the package.
If an interface contains only types, the presence of the WIT file is enough to provide that interface: the types can be generated from the WIT file.
However, if an imported interface contains funcs as well, a Wasm component is required that exports those functions.
For example, consider the chat template's test/ package (see kit installation instructions):
kit n chat
cat chat/test/chat_test/api/*
cat chat/api/*
Here, chat-template-dot-os-v0 is the test/ package world.
It imports types from interfaces defined in two other WIT files: the top-level chat as well as tester.
Networking Protocol
1. Protocol Overview and Motivation
The Kinode networking protocol is designed to be performant, reliable, private, and peer-to-peer, while still enabling access for nodes without a static public IP address.
The networking protocol is NOT designed to be all-encompassing, that is, the only way that two Kinodes will ever communicate. Many Kinode runtimes will provide userspace access to HTTP server/client capabilities, TCP sockets, and much more. Some applications will choose to use such facilities to communicate. This networking protocol is merely a common language that every Kinode is guaranteed to speak. For this reason, it is the protocol on which system processes will communicate, and it will be a reasonable default for most applications.
In order for nodes to attest to their identity without any central authority, all networking information is made available onchain. Networking information can take two forms: direct or routed. The former allows for completely direct peer-to-peer connections, and the latter allows nodes without a physical network configuration that permits direct connections to route messages through a peer.
The networking protocol can and will be implemented in multiple underlying protocols. Since the protocol is encrypted, a secure underlying connection with TLS or HTTPS is never necessary. WebSockets are prioritized since to make purely in-browser Kinodes a possibility. The other transport protocols with slots in the onchain identity data structure are: TCP, UDP, and WebTransport.
Currently, only WebSockets and TCP are implemented in the runtime. As part of the protocol, nodes identify the supported transport protocols of their counterparty and choose the optimal one to use. Even nodes that do not share common transport protocols may communicate via routers. Direct nodes must have at least one transport protocol in common. It is strongly recommended that all nodes support WebSockets, including future browser-based nodes and mobile-nodes.
2. Onchain Networking Information
All nodes must publish an Ed25519 EdDSA networking public key onchain using the protocol registry contract. A new key transaction may be posted at any time, but because agreement on networking keys is required to establish a connection and send messages between nodes, changes to onchain networking information will temporarily disrupt networking. Therefore, all nodes must have robust access to the onchain PKI, meaning: multiple backup options and multiple pathways to read onchain data. Because it may take time for a new networking key to proliferate to all nodes, (anywhere from seconds to days depending on chain indexing access) a node that changes its networking key should expect downtime immediately after doing so.
Nodes that wish to make direct connections must post an IP and port onchain.
This is done by publishing note keys in kimap.
In particular, the networking protocol expects the following pattern of data available:
- A
~net-keynote AND - Either:
a. A
~routersnote OR b. An~ipnote AND at least one of:~tcp-portnote~udp-portnote~ws-portnote~wt-portnote
Nodes with onchain networking information (an IP address and at least one port) are referred to as direct nodes, and ones without are referred to as indirect or routed nodes.
If a node is indirect, it must initiate a connection with at least one of its allowed routers in order to begin networking. Until such a connection is successfully established, the indirect node is offline. In practice, an indirect node that wants reliable access to the network should (1) have many routers listed onchain and (2) connect to as many of them as possible on startup. In order to acquire such routers in practice, a node will likely need to provide some payment or service to them.
3. Protocol Selection
When one node seeks to send a message to another node, it first checks to see if it has an existing route to send it on. If it does, that route is used. If not, the node will use the information available about the other node to try and establish a route.
If the target node is direct, the route may be direct, using one of the available transport methods. If a direct node presents multiple ports using notes in kimap, the priority is currently:
- TCP
- WS
As more protocols are supported by various runtimes, this priority list will expand.
Once a transport method is selected, if the connection fails, the target will be considered offline. A node does not need to try every route available: if a direct node presents a port, it must service connections on that method to be considered online.
If the target node is indirect, the route must be established through one of their routers. As many routers as can be attempted within the message's timeout may be tried. The selection of which routers to try in what order is implementation-specific. When a router is being attempted, the transport method will be determined as in a standard direct connection, described above. If a router is offline, the next router is tried. If no routers are online, the indirect node will be considered offline.
4. WebSockets Protocol
This protocol does not make use of any WebSocket frames other than Binary, Ping, and Pong.
Pings should be responded to with a Pong.
These are only used to keep the connection alive.
All content is sent as Binary frames.
Binary frames in the current protocol version (1) are limited to 10MB. This includes the full serialized KernelMessage.
All data structures are serialized and deserialized using MessagePack.
4.1. Establishing a Connection
The WebSockets protocol uses the Noise Protocol Framework to encrypt all messages end-to-end.
The parameters used are Noise_XX_25519_ChaChaPoly_BLAKE2s.
Using the XX pattern means following this interactive pattern:
-> e
<- e, ee, s, es
-> s, se
The initiator is the node that is trying to establish a connection.
If the target is direct, the intiator uses the IP and port provided onchain to establish a WebSocket connection. If the connection fails, the target is considered offline.
If the target is indirect, the initiator uses the IP and port of one of the target's routers to establish a WebSocket connection. If a given router is unreachable, or fails to comport to the protocol, others should be tried until they are exhausted or too much time has passed (subject to the specific implementation). If this process fails, the target is considered offline.
If the target is indirect, before beginning the XX handshake pattern, the initiator sends a RoutingRequest to the target.
#![allow(unused)] fn main() { pub struct RoutingRequest { pub protocol_version: u8, pub source: String, pub signature: Vec<u8>, pub target: String, } }
The protocol_version is the current protocol version, which is 1.
The source is the initiator's node ID, as provided onchain.
The signature must be created by the initiator's networking public key.
The content is the routing target's node ID (i.e., the node which the initiator would like to establish an e2e encrypted connection with) concatenated with the router's node ID (i.e., the node which the initiator is sending the RoutingRequest to, which will serve as a router for the connection if it accepts).
The target is the routing target's node ID that must be signed above.
Once a connection is established, the initiator sends an e message, containing an empty payload.
The target responds with the e, ee, s, es pattern, including a HandshakePayload serialized with MessagePack.
#![allow(unused)] fn main() { struct HandshakePayload { pub protocol_version: u8, pub name: String, pub signature: Vec<u8, Global>, pub proxy_request: bool, } }
The current protocol_version is 1.
The name is the name of the node, as provided onchain.
The signature must be created by the node's networking public key, visible onchain.
The content is the public key they will use to encrypt messages on this connection.
How often this key changes is implementation-specific but should be frequent.
The proxy_request is a boolean indicating whether the initiator is asking for routing service to another node.
As the target, or receiver of the new connection, proxy_request will always be false. This field is only used by the initiator.
Finally, the initiator responds with the s, se pattern, including a HandshakePayload of their own.
After this pattern is complete, the connection switches to transport mode and can be used to send and receive messages.
4.2. Sending Messages
Every message sent over the connection is a KernelMessage, serialized with MessagePack, then encrypted using the keys exchanged in the Noise protocol XX pattern, sent in a single Binary WebSockets message.
#![allow(unused)] fn main() { struct KernelMessage { pub id: u64, pub source: Address, pub target: Address, pub rsvp: Rsvp, pub message: Message, pub lazy_load_blob: Option<LazyLoadBlob> } }
See Address, Rsvp, Message,and LazyLoadBlob data types.
4.3. Receiving Messages
When listening for messages, the protocol may ignore messages other than Binary, but should also respond to Ping messages with Pongs.
When a Binary message is received, it should first be decrypted using the keys exchanged in the handshake exchange, then deserialized as a KernelMessage.
If this fails, the message should be ignored and the connection must be closed.
Successfully decrypted and deserialized messages should have their source field checked for the correct node ID and then passed to the kernel.
4.4. Closing a Connection
A connection can be intentionally closed by any party, at any time. Other causes of connection closure are discussed in this section.
All connection errors must result in closing a connection.
Failure to send a message must be treated as a connection error.
Failure to decrypt or deserialize a message must be treated as a connection error.
If a KernelMessage's source is not the node ID which the message recipient is expecting, it must be treated as a connection error.
These behaviors are necessary since they indicate that the networking information of a counterparty may have changed and a new connection must be established using the new data onchain.
Connections may be closed due to inactivity or load-balancing. This behavior is implementation-specific.
5. TCP Protocol
The TCP protocol is largely the same as the WebSockets protocol but without the use of Binary frames. KernelMessages are instead streamed.
More documentation to come -- for now, read source here:
https://github.com/kinode-dao/kinode/blob/main/kinode/src/net/tcp/utils.rs
6. Connection Maintenance and Errors
The system's networking module seeks to abstract away the many complexities of p2p networking from app developers. To this end, it reduces all networking issues to either Offline or Timeout.
Messages do not have to expect a response. If no response is expected, a networking-level offline or timeout error may still be thrown. Local messages will only receive timeout errors if they expect a response.
If a peer is direct, i.e. they have networking information published onchain, determining their offline status is simple: try to create a connection and send a message; if the underlying transport protocol experiences any errors while doing so, throw an 'offline' error. If a message is not responded to before the timeout counter expires, it will throw a timeout.
If a peer is indirect, i.e. they have routers, multiple attempts must be made before either an offline error is thrown. The specific implementation of the protocol may vary in this regard (e.g. it may try to connect to all routers, or limit the number of attempts to a subset of routers). As with direct peers, if a message is not responded to before the timeout counter expires, it will throw a timeout.
HTTP Server & Client
No server or web services backend would be complete without an HTTP interface. Kinode can both create and serve HTTP requests. As a result, Kinode apps can read data from the web (and other Kinodes), and also serve both public and private websites and APIs. The HTTP server is how most processes in Kinode present their interface to the user, through an authenticated web browser.
The specification for the server and client APIs are available in the API reference.
These APIs are accessible via messaging the http-server:distro:sys and http-client:distro:sys runtime modules, respectively.
The only capability required to use either process is the one to message it, granted by the kernel.
It is recommended to interact with the http-server and http-client using the kinode_process_lib
WebSocket server/client functionality is presented alongside HTTP.
At startup, the server either:
- Binds to the port given at the commandline, or
- Searches for an open port (starting at 8080, if not, then 8081, etc.).
The server then binds this port, listening for HTTP and WebSocket requests.
You can find usage examples here.
See also kit news chat with GUI template which you can create using
kit new my-chat --ui
Private and Public Serving
All server functionality can be either private (authenticated) or public. If a given functionality is public, the Kinode serves HTTP openly to the world; if it is authenticated, you need your node's password so that your node can generate a cookie that grants you access.
Direct and Indirect Nodes
Since direct nodes are expected to be accessible over IP, their HTTP server is likely to work if the bound port is accessible. Note that direct nodes will need to do their own IP/DNS configuration, as Kinode doesn't provide any DNS management.
Indirect nodes may not be accessible over IP, so their HTTP server may or may not function outside the local network.
Read+Write to Chain
Kinode comes with a built-in provider module for Ethereum and other EVM chains/rollups.
This runtime module lives in eth:distro:sys and is usable by any package that acquires the messaging capability for it.
In addition to allowing read/write connections directly to WebSocket RPC endpoints, the provider module can also connect via the Kinode networking protocol to other Kinodes and use their provider modules as a relay to an RPC endpoint (or to another Kinode, forming a relay chain).
The node must be configured to allow relay connections, which can be done with a public/private flag or explicit allow/deny list.
As with other runtime modules, processes should generally use the kinode_process_lib to interact with the RPC provider.
See Reading Data from ETH for an example of doing this in a process.
For more advanced or direct usage, such as configuring the provider module, see the API Reference.
Supported Chains
The provider module is capable of using any RPC endpoint that follows the JSON-RPC API that is used by Ethereum and most other EVM chains and rollups. The runtime uses the Alloy family of libraries to connect to WS RPC endpoints. It does not currently support HTTP endpoints, as subscriptions are vastly preferable for many of the features that Kinode uses.
Configuration
The API Reference demonstrates how to format requests to eth:distro:sys that adjust its config during runtime.
This includes adding and removing providers (whether other Kinodes or chain RPCs) and adjusting the permissions for other nodes to use this node as a relay.
However, most configuration is done in an optional file named .eth-providers inside the home folder of a node.
If this file is not present, a node will boot using the default providers hardcoded for testnet or mainnet, depending on where the node lives.
If it is present, the node will load in those providers and use them.
The file is a JSON object: a list of providers, with the following shape (example data):
[
{
"chain_id": 1,
"trusted": false,
"provider": {
"RpcUrl": "wss://ethereum.publicnode.com"
}
},
{
"chain_id": 11155111,
"trusted": false,
"provider": {
"Node": {
"use_as_provider": true,
"kns_update": {
"name": "default-router-1.os",
"owner": "",
"node": "0xb35eb347deb896bc3fb6132a07fca1601f83462385ed11e835c24c33ba4ef73d",
"public_key": "0xb1b1cf23c89f651aac3e5fd4decb04aa177ab0ec8ce5f1d3877b90bb6f5779db",
"ip": "123.456.789.101",
"port": 9000,
"routers": []
}
}
}
}
]
One can see that the provider list includes both node-providers (other Kinodes that are permissioned for use as a relay) and url-providers (traditional RPC endpoints).
Nodes that wish to maximize their connectivity should supply themselves with url-providers, ideally trusted ones — they can even be running locally, with a light client for Ethereum such as Helios.
In fact, a future update to the provider module will likely integrate Helios, which will allow nodes to convert untrusted endpoints to trusted ones. This is the reason for the trusted flag in the provider object.
Lastly, note that the kns_update object must fully match the onchain PKI data for the given node, otherwise the two nodes will likely not be able to establish a connection.
Files
Virtual File System (VFS)
The primary way to access files within your node is through the VFS API.
The VFS API follows std::fs closely, while also adding some capabilities checks on paths.
Use the kinode_process_lib to interact with the VFS.
VFS files exist in the vfs/ directory within your home node, and files are grouped by PackageId.
For example, part of the VFS might look like:
node-home/vfs
├── app-store:sys
│ ├── pkg
│ │ ├── api
│ │ │ └── app-store:sys-v0.wit
│ │ ├── app-store.wasm
│ │ ├── manifest.json
│ │ ...
│ └── tmp
├── chess:sys
│ ├── pkg
│ │ ├── api
│ │ │ └── chess:sys-v0.wit
│ │ ├── chess.wasm
│ │ ├── manifest.json
│ │ └── ui
│ │ │
│ │ ...
│ └── tmp
├── homepage:sys
│ ├── pkg
│ │ ├── api
│ │ │ └── homepage:sys-v0.wit
│ │ ├── homepage.wasm
│ │ ├── manifest.json
│ │ └── ui
│ │ │
│ │ ...
│ └── tmp
...
Drives
A drive is a directory within a package's VFS directory, e.g., app-store:sys/pkg/ or your-package:publisher.os/my-drive/.
Drives are owned by processes.
Processes can share access to drives they own via capabilities.
Each package is spawned with two drives: pkg/ and tmp/.
All processes in a package have caps to these default drives.
Processes can also create additional drives.
These new drives are permissioned at the process-level: other processes will need to be granted capabilities to read or write these drives.
pkg/ drive
The pkg/ drive contains metadata about the package that Kinode requires to run that package, .wasm binaries, and optionally the API of the package and the UI.
When creating packages, the pkg/ drive is populated by kit build and loaded into the Kinode using kit start-package.
tmp/ drive
The tmp/ drive can be written to directly by the owning package using standard filesystem functionality (i.e. std::fs in Rust) via WASI in addition to the Kinode VFS.
Usage
For usage examples, see the VFS API.
Databases
Kinode provides key-value databases via RocksDB, and relational databases via SQLite. Processes can create independent databases using wrappers over these libraries, and can read, write, and share these databases with other processes. The APIs for doing are found here: KV and SQLite.
Similarly to drives in the VFS, they are accessed by package_id and a db name (i.e. kv::open() and sqlite::open()).
Capabilities to read and write can be shared with other processes.
All examples are using the kinode_process_lib functions.
Usage
For usage examples, see the key-value API and the SQlite API.
Terminal
The terminal syntax is specified in the main Kinode repository.
Commands
All commands in the terminal are calling scripts — a special kind of process.
Kinode comes pre-loaded with a number of scripts useful for debugging and everyday use.
These scripts are fully named <SCRIPT>:terminal:sys e.g hi:terminal:sys, but the distro aliases these to short names, in this case just hi, for convenience.
hi - ping another kinode
Usage: hi <KNS_ID> <MESSAGE>
Arguments:
<KNS_ID> id of the node you want to message, e.g. some-node.os
<MESSAGE> any string
Example:
hi other-node.os Hello other-node.os! how are you?
m - message a process
Usage: m <ADDRESS> <BODY>
Arguments:
<ADDRESS> kns addresss e.g. some-node.os@process:pkg:publisher.os
<BODY> json payload wrapped in single quotes, e.g. '{"foo": "bar"}'
Options:
-a, --await <SECONDS> await the response, timing out after SECONDS
Example:
m -a 5 our@foo:bar:baz '{"some payload": "value"}'
- this will await the response and print it out
m our@foo:bar:baz '{"some payload": "value"}'
- this one will not await the response or print it out
top - display information about processes
Usage: top [PROCESS_ID]
Arguments:
[PROCESS_ID] optional process id, just print information about this process
Example:
top
- this prints all information for all processes
top terminal:terminal:sys
- this prints information for just the requested process
alias - alias a script name
Usage: alias <NAME> [SCRIPT]
Arguments:
<NAME> the name you want to assign the script to
[SCRIPT] the script-id
Example:
alias my-script my-script:my-package:my-name.os
- this lets you call my-script in the terminal as a shorthand
alias my-script
- this removes the my-script alias
cat - print the contents of a file in your vfs
Usage: cat <FILE_PATH>
Arguments:
<FILE_PATH> the file path in your vfs
Example:
cat terminal:sys/pkg/scripts.json
echo - print the argument
echo is mostly an example script for developers to look at.
Usage: echo <MESSAGE>
Arguments:
<MESSAGE> any string
Example:
echo Hello World!
For more information on writing your own scripts, see the cookbook.
Packaging Scripts with scripts.json
For your scripts to be usable by the terminal, you must include a pkg/scripts.json file, like this one.
Note that this is a core package and this file should not be edited, but rather you should create one in your own package.
For more discussion on package folder structure, look here.
The JSON object in scripts.json describes the configuration for each script in your package.
Each top-level key represents the path of a process in your package, usually just "myscript.wasm", "echo.wasm", etc.
Within this JSON object, for each key (i.e., process) the value is an object that specifies the configuration for that particular process. The object can contain the following fields:
| Field | Type | Description |
|---|---|---|
"root" | Boolean | Indicates whether the script has "root" privileges - meaning whether it gets every capability that the terminal has (not necessarily every capability in existence on your machine) |
"public" | Boolean | Determines if the script is publicly accessible by other processes |
"request_networking" | Boolean | Specifies whether the script will get networking capabilities |
"request_capabilities" | Array | An array that lists the capabilities requested by the script. Each element in the array can be either a string or an object. The string represents a ProcessId that this script will be able to message. When an object is used, it specifies a different kind of capability from issuer with params as an arbitrary json object. |
"grant_capabilities" | Array of strings | An array of ProcessIds which represents which processes will be able to send a Response back to this script. If this script is public, grant_capabilities can stay empty. |
"wit_version" | Unsigned integer | The WIT version to use |
Processes may not necessarily use all these fields.
For instance, m.wasm only uses root, public, and request_networking, omitting request_capabilities and grant_capabilities.
Example
This is a scripts.json that publishes a single script, hi, which doesn't receive all of its parent's capabilities (root=false), is not public, can send messages over the network, will receive the capability to message net:distro:sys, and gives net:distro:sys the ability to message it back:
{
"hi.wasm": {
"root": false,
"public": false,
"request_networking": true,
"request_capabilities": [
"net:distro:sys"
],
"grant_capabilities": [
"net:distro:sys"
],
"wit_version": 1
}
}
process_lib Overview
This page serves as an introduction to the process standard library, which makes writing Rust apps on Kinode easy. The full documentation can be found here, and the crate lives here.
In your Cargo.toml file, use a version tag like this:
kinode_process_lib = "0.10.0"
Make sure to use a recent version of the process_lib while the system is in beta and active development.
The major version of the process_lib will always match the major version of Kinode.
Since the current major version of both is 0, breaking changes can occur at any time.
Once the major version reaches 1, breaking changes will only occur between major versions.
As is, developers may have to update their version of process_lib as they update Kinode.
Since Kinode apps use the WebAssembly Component Model, they are built on top of a WIT (Wasm Interface Type) package.
wit-bindgen is used to generate Rust code from a WIT file.
The generated code then contains the core types and functions that are available to all Kinode apps.
However, the types themselves are unwieldy to use directly, and runtime modules present APIs that can be drastically simplified by using helper functions and types in the process standard library.
Almost all code examples in this book make use of the process_lib.
For specific examples of its usage, check out the docs or just follow the tutorials later in this book.
kit
kit is a CLI toolkit to make development on Kinode ergonomic.
Table of Contents
- Installation
kit boot-fake-nodekit newkit buildkit start-packagepublishkit build-start-packagekit remove-packagekit chainkit dev-uikit inject-messagekit run-testskit connectkit reset-cachekit boot-real-nodekit view-api
Install kit
These documents describe some ways you can use these tools, but do not attempt to be completely exhaustive.
You are encouraged to make use of the --help flag, which can be used for the top-level kit command:
$ kit --help
Development toolkit for Kinode
Usage: kit <COMMAND>
Commands:
boot-fake-node Boot a fake node for development [aliases: f]
boot-real-node Boot a real node [aliases: e]
build Build a Kinode package [aliases: b]
build-start-package Build and start a Kinode package [aliases: bs]
chain Start a local chain for development [aliases: c]
connect Connect (or disconnect) a ssh tunnel to a remote server
dev-ui Start the web UI development server with hot reloading (same as `cd ui && npm i && npm run dev`) [aliases: d]
inject-message Inject a message to a running Kinode [aliases: i]
new Create a Kinode template package [aliases: n]
publish Publish or update a package [aliases: p]
remove-package Remove a running package from a node [aliases: r]
reset-cache Reset kit cache (Kinode core binaries, logs, etc.)
run-tests Run Kinode tests [aliases: t]
setup Fetch & setup kit dependencies
start-package Start a built Kinode package [aliases: s]
update Fetch the most recent version of kit
view-api Fetch the list of APIs or a specific API [aliases: v]
help Print this message or the help of the given subcommand(s)
Options:
-v, --version Print version
-h, --help Print help
or for any of the subcommands, e.g.:
kit new --help
The first chapter of the My First Kinode App tutorial shows the kit tools in action.
Getting kit
kit requires Rust.
To get kit, run
# Install Rust if you don't have it.
curl --proto '=https' --tlsv1.2 -sSf https://sh.rustup.rs | sh
# Install `kit`.
cargo install --git https://github.com/kinode-dao/kit --locked
To update, run that same command or
kit update
You can find the source for kit at https://github.com/kinode-dao/kit.
You can find a video guide that walks through setting up kit here.
Logging
Logs are printed to the terminal and stored, by default, at /tmp/kinode-kit-cache/logs/log.log.
The default logging level is info.
Other valid logging levels are: debug, warning and error.
These defaults can be changed by setting environment variables:
| Environment Variable | Description |
|---|---|
KIT_LOG_PATH | Set log path (default /tmp/kinode-kit-cache/logs/log.log). |
RUST_LOG | Set log level (default info). |
For example, in Bash:
export RUST_LOG=info
kit boot-fake-node
short: kit f
kit boot-fake-node starts a "fake" node connected to a "fake" chain (i.e. not connected to the live network), e.g.,
kit boot-fake-node
By default, boot-fake-node fetches a prebuilt binary and launches the node using it.
Alternatively, boot-fake-node can build a local Kinode core repo and use the resulting binary.
It also boots a fake chain with anvil in the background (see kit chain).
The fake chain comes preseeded with two contracts: KNS, which nodes use to index networking info of other nodes; and app-store, which nodes use to index published packages.
Example Usage
You can start a network of fake nodes that can communicate with each other (but not the live network).
You'll need to start a new terminal for each fake node.
For example, to start two fake nodes, fake.dev and fake2.dev:
kit boot-fake-node
# In a new terminal
kit boot-fake-node -f fake2.dev -p 8081 -o /tmp/kinode-fake-node-2
# Send a message from fake2.dev to fake.dev
# In the terminal of fake2.dev:
hi fake.dev hello!
# You should see "hello!" in the first node's terminal
Discussion
Fake nodes make development easier.
A fake node is not connected to the network, but otherwise behaves the same as a live node.
Fake nodes are connected to each other on your local machine through a network router that passes messages between them.
Fake nodes also clean up after themselves, so you don't have to worry about state from a previous iterations messing up the current one.
If you wish to persist the state of a fake node between boots, you can do so with --persist.
Thus, fake nodes are an excellent testing ground during development for fast iteration.
There are some cases where fake nodes are not appropriate. The weakness of fake nodes is also their strength: they are not connected to the live Kinode network. Though this lack of connectivity makes them easy to spin up and throw away, the downside is no access to services on the network which live Kinodes may provide.
Arguments
$ kit boot-fake-node --help
Boot a fake node for development
Usage: kit boot-fake-node [OPTIONS]
Options:
-r, --runtime-path <PATH>
Path to Kinode core repo (overrides --version)
-v, --version <VERSION>
Version of Kinode binary to use (overridden by --runtime-path) [default: latest] [possible values: latest, v0.8.7, v0.8.6, v0.8.5]
-p, --port <NODE_PORT>
The port to run the fake node on [default: 8080]
-o, --home <HOME>
Path to home directory for fake node [default: /tmp/kinode-fake-node]
-f, --fake-node-name <NODE_NAME>
Name for fake node [default: fake.dev]
-c, --fakechain-port <FAKECHAIN_PORT>
The port to run the fakechain on (or to connect to) [default: 8545]
--rpc <RPC_ENDPOINT>
Ethereum Optimism mainnet RPC endpoint (wss://)
--persist
If set, do not delete node home after exit
--password <PASSWORD>
Password to login [default: secret]
--release
If set and given --runtime-path, compile release build [default: debug build]
--verbosity <VERBOSITY>
Verbosity of node: higher is more verbose [default: 0]
-h, --help
Print help
--runtime-path
short: -r
Pass to build a local Kinode core repo and use the resulting binary to boot a fake node, e.g.
kit boot-fake-node --runtime-path ~/git/kinode
for a system with the Kinode core repo living at ~/git/kinode.
Overrides --version.
--version
short: -v
Fetch and run a specific version of the binary; defaults to most recent version.
Overridden by --runtime-path.
--port
short: -p
Run the fake node on this port; defaults to 8080.
--home
short: -o
Path to home directory for fake node; defaults to /tmp/kinode-fake-node.
--fake-node-name
short: -f
The name of the fake node; defaults to fake.os.
--fakechain-port
Run the anvil chain on this port; defaults to 8545.
Additional fake nodes must point to the same port to connect to the chain.
--rpc
The Ethereum RPC endpoint to use, if desired.
--persist
Persist the node home directory after exit, rather than cleaning it up.
Example usage:
kit boot-fake-node --persist --home ./my-fake-node
After shutting down the node, to run it again:
kit boot-fake-node --home ./my-fake-node
--password
The password of the fake node; defaults to "secret".
--release
If --runtime-path is given, build the runtime for release; default is debug.
The tradeoffs between the release and default version are described here.
--verbosity
Set the verbosity of the node; higher is more verbose; default is 0, max is 3.
kit new
short: kit n
kit new creates a Kinode package template at the specified path, e.g.,
kit new foo
creates the default template (a Rust chat app with no UI) in the foo/ directory.
The package name must be "Kimap-safe": contain only a-z, 0-9, and -.
Example Usage
# Create the default template: rust chat with no UI
kit new my-rust-chat
# Create rust chat with UI
kit new my-rust-chat-with-ui --ui
Discussion
You can create a variety of templates using kit new.
Currently, one language is supported: rust.
Ask us in the Discord about python, and javascript templates.
Four templates are currently supported, as described in the following section.
In addition, some subset of these templates also have a UI-enabled version.
Exists/Has UI-enabled Version
The following table specifies whether a template "Exists/Has UI-enabled version" for each language/template combination:
| Language | chat | echo | fibonacci | file-transfer |
|---|---|---|---|---|
rust | yes/yes | yes/no | yes/no | yes/no |
Brief description of each template:
chat: A simple chat app.echo: Echos back any message it receives.fibonacci: Computes the n-th Fibonacci number.file-transfer: Allows for file transfers between nodes.
Arguments
$ kit new --help
Create a Kinode template package
Usage: kit new [OPTIONS] <DIR>
Arguments:
<DIR> Path to create template directory at (must contain only a-z, 0-9, `-`)
Options:
-a, --package <PACKAGE> Name of the package (must contain only a-z, 0-9, `-`) [default: DIR]
-u, --publisher <PUBLISHER> Name of the publisher (must contain only a-z, 0-9, `-`, `.`) [default: template.os]
-l, --language <LANGUAGE> Programming language of the template [default: rust] [possible values: rust]
-t, --template <TEMPLATE> Template to create [default: chat] [possible values: blank, chat, echo, fibonacci, file-transfer]
--ui If set, use the template with UI
-h, --help Print help
Positional arg: DIR
Create the template package in this directory.
By default the package name is set to the name specified here, if not supplied by --package.
--package
short: -a
Name of the package; defaults to DIR.
Must be Kimap-safe: contain only a-z, 0-9, and -.
--publisher
short: -u
Name of the publisher; defaults to template.os.
Must be Kimap-safe (plus .): contain only a-z, 0-9, -, and ..
--language
short: -l
Template language; defaults to rust.
Currently supports rust.
Ask us in the Discord about python, and javascript templates.
--template
short: -t
Which template to create; defaults to chat.
Options are outlined in Exists/Has UI-enabled version.
--ui
Create the template with a UI.
Currently, only rust chat has UI support.
kit build
short: kit b
kit build builds the indicated package directory, or the current working directory if none supplied, e.g.,
kit build foo
or
kit build
kit build builds each process in the package and places the .wasm binaries into the pkg/ directory for installation with kit start-package.
It automatically detects what language each process is, and builds it appropriately (from amongst the supported rust, python, and javascript).
Discussion
kit build builds a Kinode package directory.
Specifically, it iterates through all directories within the given package directory and looks for src/lib.??, where the ?? is the file extension.
Currently, rs is supported, corresponding to processes written in rust.
Note that a package may have more than one process and those processes need not be written in the same language.
After compiling each process, it places the output .wasm binaries within the pkg/ directory at the top-level of the given package directory.
Here is an example of what a package directory will look like after using kit build:
my-rust-chat
├── Cargo.lock
├── Cargo.toml
├── metadata.json
├── pkg
│ ├── manifest.json
│ ├── my-rust-chat.wasm
│ ├── scripts.json
│ └── send.wasm
├── my-rust-chat
│ └── ...
└── send
└── ...
The pkg/ directory is then zipped and can be injected into the node with kit start-package.
kit build also builds the UI if it is found in pkg/ui/.
There must exist a ui/package.json file with a scripts object containing the following arguments:
"scripts": {
"build": "tsc && vite build",
"copy": "mkdir -p ../pkg/ui && rm -rf ../pkg/ui/* && cp -r dist/* ../pkg/ui/",
"build:copy": "npm run build && npm run copy",
}
Additional UI dev info can be found here.
To both build and start-package in one command, use kit build-start-package.
Arguments
$ kit build --help
Build a Kinode package
Usage: kit build [OPTIONS] [DIR]
Arguments:
[DIR] The package directory to build [default: /home/nick/git/kinode-book/src]
Options:
--no-ui
If set, do NOT build the web UI for the process; no-op if passed with UI_ONLY
--ui-only
If set, build ONLY the web UI for the process; no-op if passed with NO_UI
-i, --include <INCLUDE>
Build only these processes/UIs (can specify multiple times) [default: build all]
-e, --exclude <EXCLUDE>
Build all but these processes/UIs (can specify multiple times) [default: build all]
-s, --skip-deps-check
If set, do not check for dependencies
--features <FEATURES>
Pass these comma-delimited feature flags to Rust cargo builds
-p, --port <NODE_PORT>
localhost node port; for remote see https://book.kinode.org/hosted-nodes.html#using-kit-with-your-hosted-node [default: 8080]
-d, --download-from <NODE>
Download API from this node if not found
-w, --world <WORLD>
Fallback WIT world name
-l, --local-dependency <DEPENDENCY_PACKAGE_PATH>
Path to local dependency package (can specify multiple times)
-a, --add-to-api <PATH>
Path to file to add to api.zip (can specify multiple times)
-r, --reproducible
Make a reproducible build using Docker
-f, --force
Force a rebuild
-v, --verbose
If set, output stdout and stderr
-h, --help
Print help
Optional positional arg: DIR
The package directory to build; defaults to the current working directory.
--no-ui
Do not build the web UI for the process.
Does nothing if passed with --ui-only.
--ui-only
Build ONLY the UI for a package with a UI. Otherwise, for a package with a UI, both the package and the UI will be built.
--include
short: -i
Only build these processes/UIs within the package. Can be specified multiple times.
If not specified, build all.
--exclude
short: -e
Do not build these processes/UIs within the package. Can be specified multiple times.
If not specified, build all.
--skip-deps-check
short: -s
Don't check for dependencies.
--features
Build the package with the given cargo features.
Features can be used like shown here.
Currently the only feature supported system-wide is simulation-mode.
--port
short: -p
Node to pull dependencies from. A package's dependencies can be satisfied by either:
- A live node, the one running at the port given here, or
- By local dependencies (specified using
--local-dependency, below).
--download-from
short: -d
The mirror to download dependencies from (default: package publisher).
--world
short: -w
WIT world to use.
Not required for Rust processes; use for py or js.
--local-dependency
short: -l
A path to a package that satisfies a build dependency. Can be specified multiple times.
--add-to-api
short: -a
A path to a file to include in the API published alongside the package. Can be specified multiple times.
--reproducible
short: -r
Make a reproducible build with a deterministic hash.
Rust does not produce reproducible builds unless:
- The path of the source is the same.
- Compiler versions match (e.g.,
rustc,gcc,ld). build.rsis deterministic.
kit allows reproducible builds by building the package inside a Docker image, which controls 1 and 2.
The Docker image is published for x86_64 Linux machines specifically, but also works on x86_64 MacOS machines.
--force
short: -f
Don't check if package doesn't need to be rebuilt: just build it.
--verbose
short: -v
Always output stdout and stderr if set.
kit start-package
short: kit s
kit start-package installs and starts the indicated package directory (or current working directory) on the given Kinode (at localhost:8080 by default), e.g.,
kit start-package foo
or
kit start-package
Discussion
kit start-package injects a built package into the given node and starts it.
start-package is designed to be used after a package has been built with kit build.
The pkg/ directory contains metadata about the package for the node as well as the .wasm binaries for each process.
The final step in the build process is to zip the pkg/ directory.
kit start-package looks for the zipped pkg/ and then injects a message to the node to start the package.
To both build and start-package in one command, use kit build-start-package.
Arguments
$ kit start-package --help
Start a built Kinode package
Usage: kit start-package [OPTIONS] [DIR]
Arguments:
[DIR] The package directory to start [default: CWD]
Options:
-p, --port <NODE_PORT> localhost node port; for remote see https://book.kinode.org/hosted-nodes.html#using-kit-with-your-hosted-node [default: 8080]
-h, --help Print help
Optional positional arg: DIR
The package directory to install and start on the node; defaults to current working directory.
--port
short: -p
The localhost port of the node; defaults to 8080.
To interact with a remote node, see here.
kit publish
short: kit p
kit publish creates entries in the Kimap, publishing the given package according to the app-stores protocol.
It can also be used to update or unpublish previously-published packages.
kit publish directly writes to the Kimap: it does not interact with a Kinode.
Example Usage
# Publish a package on the real network (Optimism mainnet).
kit publish --metadata-uri https://raw.githubusercontent.com/path/to/metadata.json --keystore-path ~/.foundry/keystores/dev --rpc wss://opt-mainnet.g.alchemy.com/v2/<ALCHEMY_API_KEY> --real
# Unublish a package.
kit publish --metadata-uri https://raw.githubusercontent.com/path/to/metadata.json --keystore-path ~/.foundry/keystores/dev --rpc wss://opt-mainnet.g.alchemy.com/v2/<ALCHEMY_API_KEY> --real --unpublish
See Sharing with the World for a tutorial on how to use kit publish.
Arguments
$ kit publish --help
Publish or update a package
Usage: kit publish [OPTIONS] --metadata-uri <URI> --keystore-path <PATH> --rpc <RPC_URI> [DIR]
Arguments:
[DIR] The package directory to publish [default: CWD]
Options:
-k, --keystore-path <PATH>
Path to private key keystore (choose 1 of `k`, `l`, `t`)
-l, --ledger
Use Ledger private key (choose 1 of `k`, `l`, `t`)
-t, --trezor
Use Trezor private key (choose 1 of `k`, `l`, `t`)
-u, --metadata-uri <URI>
URI where metadata lives
-r, --rpc <RPC_URI>
Ethereum Optimism mainnet RPC endpoint (wss://)
-e, --real
If set, deploy to real network [default: fake node]
--unpublish
If set, unpublish existing published package [default: publish a package]
-g, --gas-limit <GAS_LIMIT>
The ETH transaction gas limit [default: 1_000_000]
-p, --priority-fee <MAX_PRIORITY_FEE_PER_GAS>
The ETH transaction max priority fee per gas [default: estimated from network conditions]
-f, --fee-per-gas <MAX_FEE_PER_GAS>
The ETH transaction max fee per gas [default: estimated from network conditions]
-h, --help
Print help
Positional arg: DIR
Publish the metadata for the package in this directory.
--metadata-uri
short: -u
The URI hosting the metadata.json.
You must place the metadata.json somewhere public before publishing your package on Kimap.
A common place to host metadata.json is on your package's GitHub repo.
If you use GitHub, make sure to use the static link to the specific commit, not a branch-specific URL (e.g. main) that will change with new commits.
For example, https://raw.githubusercontent.com/nick1udwig/chat/master/metadata.json is not the correct link to use, because it will change when new commits are added.
You want to use a link like https://raw.githubusercontent.com/nick1udwig/chat/191dce595ad00a956de04b9728f479dee04863c7/metadata.json which will not change when new commits are added.
--keystore-path
short: -k
Use private key from keystore given by path. The keystore is a Web3 Secret Storage file that holds an encrypted copy of your private keys. See the Sharing with the World usage example for one way to create a keystore.
Must supply one and only one of --keystore-path, --ledger, or --trezor.
--ledger
short: -l
Use private key from Ledger.
Must supply one and only one of --keystore-path, --ledger, or --trezor.
--trezor
short: -t
Use private key from Trezor.
Must supply one and only one of --keystore-path, --ledger, or --trezor.
--rpc
short: -r
The Ethereum RPC endpoint to use.
For fakenodes this runs by default at ws://localhost:8545.
--real
short: -e
Manipulate the real (live) Kimap. Default is to manipulate the fakenode Kimap.
--unpublish
Remove a previously-published package.
--gas-limit
short: -g
Set the gas limit for the transaction.
--priority-fee
short: -p
Set the priority fee for the transaction.
--fee-per-gas
short: -f
Set the price of gas for the transaction.
kit build-start-package
short: kit bs
kit build-start-package builds, installs and starts the indicated package directory, or the current working directory if none supplied, e.g.,
kit build-start-package foo
or
kit build-start-package
Discussion
kit build-start-package runs kit build followed by kit start-package.
Arguments
$ kit build-start-package --help
Build and start a Kinode package
Usage: kit build-start-package [OPTIONS] [DIR]
Arguments:
[DIR] The package directory to build [default: /home/nick/git/kit]
Options:
-p, --port <NODE_PORT>
localhost node port; for remote see https://book.kinode.org/hosted-nodes.html#using-kit-with-your-hosted-node [default: 8080]
-d, --download-from <NODE>
Download API from this node if not found
-w, --world <WORLD>
Fallback WIT world name
-l, --local-dependency <DEPENDENCY_PACKAGE_PATH>
Path to local dependency package (can specify multiple times)
-a, --add-to-api <PATH>
Path to file to add to api.zip (can specify multiple times)
--no-ui
If set, do NOT build the web UI for the process; no-op if passed with UI_ONLY
--ui-only
If set, build ONLY the web UI for the process
-i, --include <INCLUDE>
Build only these processes/UIs (can specify multiple times) (default: build all)
-e, --exclude <EXCLUDE>
Build all but these processes/UIs (can specify multiple times) (default: build all)
-s, --skip-deps-check
If set, do not check for dependencies
--features <FEATURES>
Pass these comma-delimited feature flags to Rust cargo builds
-r, --reproducible
Make a reproducible build using Docker
-f, --force
Force a rebuild
-v, --verbose
If set, output stdout and stderr
-h, --help
Print help
Optional positional arg: DIR
The package directory to build, install and start on the node; defaults to the current working directory.
--port
short: -p
The localhost port of the node; defaults to 8080.
To interact with a remote node, see here.
--download-from
short: -d
The mirror to download dependencies from (default: package publisher).
--world
short: -w
WIT world to use.
Not required for Rust processes; use for py or js.
--local-dependency
short: -l
A path to a package that satisfies a build dependency. Can be specified multiple times.
--add-to-api
short: -a
A path to a file to include in the API published alongside the package. Can be specified multiple times.
--no-ui
Do not build the web UI for the process.
Does nothing if passed with --ui-only.
--ui-only
Build ONLY the UI for a package with a UI. Otherwise, for a package with a UI, both the package and the UI will be built.
--include
short: -i
Only build these processes/UIs within the package. Can be specified multiple times.
If not specified, build all.
--exclude
short: -e
Do not build these processes/UIs within the package. Can be specified multiple times.
If not specified, build all.
--skip-deps-check
short: -s
Don't check for dependencies.
--features
Build the package with the given cargo features.
Features can be used like shown here.
Currently the only feature supported system-wide is simulation-mode.
--reproducible
short: -r
Make a reproducible build with a deterministic hash.
Rust does not produce reproducible builds unless:
- The path of the source is the same.
- Compiler versions match (e.g.,
rustc,gcc,ld). build.rsis deterministic.
kit allows reproducible builds by building the package inside a Docker image, which controls 1 and 2.
The Docker image is published for x86_64 Linux machines specifically, but also works on x86_64 MacOS machines.
--force
short: -f
Don't check if package doesn't need to be rebuilt: just build it.
--verbose
short: -v
Always output stdout and stderr if set.
kit remove-package
short: kit r
kit remove-package removes an installed package from the given node (defaults to localhost:8080).
For example,
kit remove-package foo
or
kit remove-package -package foo --publisher template.os
Discussion
If passed an optional positional argument DIR (the path to a package directory), the metadata.json therein is parsed to get the package_id and that package is removed from the node.
If no arguments are provided, the same process happens for the current working directory.
Alternatively, a --package and --publisher can be provided as arguments, and that package will be removed.
Arguments
$ kit remove-package --help
Remove a running package from a node
Usage: kit remove-package [OPTIONS] [DIR]
Arguments:
[DIR] The package directory to remove (Overridden by PACKAGE/PUBLISHER) [default: CWD]
Options:
-a, --package <PACKAGE> Name of the package (Overrides DIR)
-u, --publisher <PUBLISHER> Name of the publisher (Overrides DIR)
-p, --port <NODE_PORT> localhost node port; for remote see https://book.kinode.org/hosted-nodes.html#using-kit-with-your-hosted-node [default: 8080]
-h, --help Print help
Optional positional arg: DIR
The package directory to be removed from the node; defaults to current working directory.
--package
short: -a
The package name of the package to be removed; default is derived from metadata.json in DIR.
--publisher
short -u
The publisher of the package to be removed; default is derived from metadata.json in DIR.
--port
short: -p
For nodes running on localhost, the port of the node; defaults to 8080.
--port is overridden by --url if both are supplied.
--url
short: -u
The URL the node is hosted at.
Can be either localhost or remote.
--url overrides --port if both are supplied.
kit chain
short: kit c
kit chain starts a local fakechain with foundry's anvil, e.g.,
kit chain
The default port is 8545 and the chain ID is 31337.
Discussion
kit chain starts an anvil node with the arguments --load-state kinostate.json.
This json file includes the KNS (Kinode Name System) & app-store contracts, and is included in the kit binary.
The kinostate.json files can be found written into /tmp/kinode-kit-cache/kinostate-{hash}.json upon running the command.
Note that while the kns-indexer and app-store apps in fake nodes use this chain to index events, any events loaded from a json statefile, aren't replayed upon restarting anvil.
Arguments
$ kit chain --help
Start a local chain for development
Usage: kit chain [OPTIONS]
Options:
-p, --port <PORT> Port to run the chain on [default: 8545]
-v, --version <VERSION> Version of Kinode binary to run chain for (foundry version must match Kinode version) [default: latest] [possible values: latest, v0.9.9, v0.9.8, v0.9.7]
-v, --verbose If set, output stdout and stderr
-h, --help Print help
--port
Port to run anvil fakechain on.
Defaults to 8545.
--version
Kinode binary version to run chain for.
Different Kinode versions have different foundry compatibility due to breaking changes in chain state formatting.
kit will prompt you to install the proper version of foundry.
--verbose
short: -v
Always output stdout and stderr if set.
kit dev-ui
short: kit d
kit dev-ui starts a web development server with hot reloading for the indicated UI-enabled package (or the current working directory), e.g.,
kit dev-ui foo
or
kit dev-ui
Arguments
$ kit dev-ui --help
Start the web UI development server with hot reloading (same as `cd ui && npm i && npm run dev`)
Usage: kit dev-ui [OPTIONS] [DIR]
Arguments:
[DIR] The package directory to build (must contain a `ui` directory) [default: CWD]
Options:
-p, --port <NODE_PORT> localhost node port; for remote see https://book.kinode.org/hosted-nodes.html#using-kit-with-your-hosted-node [default: 8080]
--release If set, create a production build
-s, --skip-deps-check If set, do not check for dependencies
-h, --help Print help
Optional positional arg: DIR
The UI-enabled package directory to serve; defaults to current working directory.
--port
short: -p
For nodes running on localhost, the port of the node; defaults to 8080.
--port is overridden by --url if both are supplied.
--release
Create a production build. Defaults to dev build.
--skip-deps-check
short: -s
Don't check for dependencies.
kit inject-message
short: kit i
kit inject-message injects the given message to the node running at given port/URL, e.g.,
kit inject-message foo:foo:template.os '{"Send": {"target": "fake2.os", "message": "hello world"}}'
Discussion
kit inject-message injects the given message into the given node.
It is useful for:
- Testing processes from the outside world during development
- Injecting data into the node
- Combining the above with
bashor other scripting. For example, using the--blobflag you can directly inject the contents of a file. You can script in the outside world, dump the result to a file, and inject it withinject-message.
By default, inject-message expects a Response from the target process.
To instead "fire and forget" a message and exit immediately, use the --non-block flag.
Arguments
$ kit inject-message --help
Inject a message to a running Kinode
Usage: kit inject-message [OPTIONS] <PROCESS> <BODY_JSON>
Arguments:
<PROCESS> PROCESS to send message to
<BODY_JSON> Body in JSON format
Options:
-p, --port <NODE_PORT> localhost node port; for remote see https://book.kinode.org/hosted-nodes.html#using-kit-with-your-hosted-node [default: 8080]
-n, --node <NODE_NAME> Node ID (default: our)
-b, --blob <PATH> Send file at Unix path as bytes blob
-l, --non-block If set, don't block on the full node response
-h, --help Print help
First positional arg: PROCESS
The process to send the injected message to in the form of <process_name>:<package_name>:<publisher>.
Second positional arg: BODY_JSON
The message body.
--port
short: -p
For nodes running on localhost, the port of the node; defaults to 8080.
--port is overridden by --url if both are supplied.
--node
short: -n
Node to target (i.e. the node portion of the address).
E.g., the following, sent to the port running fake.os, will be forwarded from fake.os's HTTP server to fake2@foo:foo:template.os:
kit inject-message foo:foo:template.os '{"Send": {"target": "fake.os", "message": "wow, it works!"}}' --node fake2.os
--blob
short: -b
Path to file to include as lazy_load_blob.
--non-block
short: -l
Don't block waiting for a Response from target process. Instead, inject the message and immediately return.
kit run-tests
short: kit t
kit run-tests runs the tests specified by the given .toml file, or tests.toml, e.g.,
kit run-tests my_tests.toml
or
kit run-tests
to run the current working directory's tests.toml or the current package's test/.
Discussion
kit run-tests runs a series of tests specified by a .toml file.
Each test is run in a fresh environment of one or more fake nodes.
A test can setup one or more packages before running a series of test packages.
Each test package is a single-process package that accepts and responds with certain messages.
Tests are orchestrated from the outside of the node by kit run-tests and run on the inside of the node by the tester core package.
For a given test, the tester package runs the specified test packages in order.
Each test package must respond to the tester package with a Pass or Fail.
The tester package stops on the first Fail, or responds with a Pass if all tests Pass.
If a given test Passes, the next test in the series is run.
Examples of tests are the Kinode Book's code examples and kits templates.
Arguments
$ kit run-tests --help
Run Kinode tests
Usage: kit run-tests [PATH]
Arguments:
[PATH] Path to tests configuration file [default: tests.toml]
Options:
-h, --help Print help
Optional positional arg: PATH
Path to .toml file specifying tests to run; defaults to tests.toml in current working directory.
tests.toml
The testing protocol is specified by a .toml file.
tests.toml, from core tests, will be used as an example:
runtime = { FetchVersion = "latest" }
# runtime = { RepoPath = "~/git/kinode" }
persist_home = false
runtime_build_release = false
[[tests]]
dependency_package_paths = []
setup_packages = []
setup_scripts = []
test_package_paths = ["key_value_test", "sqlite_test"]
test_scripts = []
timeout_secs = 5
fakechain_router = 8545
[[tests.nodes]]
port = 8080
home = "home/first"
fake_node_name = "first.dev"
runtime_verbosity = 2
[[tests.nodes]]
port = 8081
home = "home/second"
fake_node_name = "second.dev"
runtime_verbosity = 2
[[tests]]
dependency_package_paths = []
setup_packages = []
test_package_paths = ["key_value_test"]
setup_scripts = []
test_scripts = []
timeout_secs = 5
fakechain_router = 8545
[[tests.nodes]]
port = 8080
home = "home/first"
fake_node_name = "first.dev"
runtime_verbosity = 2
The top-level of tests.toml consists of four fields:
| Key | Value Type |
|---|---|
runtime | { FetchVersion = "<version>" } or { RepoPath = "~/path/to/repo" } |
runtime_build_release | Boolean |
persist_home | Boolean |
tests | Array of Tables |
runtime
Specify the runtime to use for the tests.
Two option variants are supported.
An option variant is specified with the key (e.g. FetchVersion) of a toml Table (e.g. {FetchVersion = "0.7.2"}).
The first, and recommended is FetchVersion.
The value of the FetchVersion Table is the version number to fetch and use (or "latest").
That version of the runtime binary will be fetched from remote if not found locally.
The second is RepoPath.
The value of the RepoPath Table is the path to a local copy of the runtime repo.
Given a valid path, that repo will be compiled and used.
For example:
runtime = { FetchVersion = "latest" }
runtime_build_release
If given runtime = RepoPath, runtime_build_release decides whether to build the runtime as --release or not.
For example:
persist_home = false
persist_home
Whether or not to persist the node home directories after tests have been run.
It is recommended to have this set to false except when debugging a test.
tests
An Array of Tables. Each Table specifies one test to run. That test consists of:
| Key | Value Type | Value Description |
|---|---|---|
dependency_package_paths | Array of Strings (PathBufs) | Paths to packages to load onto dependency node so that setup or test packages can fetch them to fulfil dependencies |
setup_packages | Array of Tables (SetupPackages) | Each Table in the Array contains path (to the package) and run (whether or not to run the package or merely load it in) |
setup_scripts | Array of Strings (bash line) | Each Table in the Array contains path (to the script) and args (to be passed to the script); these scripts will run alongside the test nodes |
test_package_paths | Array of Strings (PathBufs) | Paths to test packages to run |
test_scripts | Array of Strings (bash line) | Each Table in the Array contains path (to the script) and args (to be passed to the script); these scripts will be run as tests and must return a 0 on success |
timeout_secs | Integer > 0 | Timeout for this entire series of test packages |
fakechain_router | Integer >= 0 | Port to be bound by anvil, where fakechain will be hosted |
nodes | Array of Tables | Each Table specifies configuration of one node to spin up for test |
Each test package is a single-process package that accepts and responds with certain messages.
For example:
...
[[tests]]
dependency_package_paths = []
setup_packages = []
setup_scripts = []
test_package_paths = ["key_value_test", "sqlite_test"]
test_scripts = []
timeout_secs = 5
fakechain_router = 8545
[[tests.nodes]]
...
nodes
Each test specifies one or more nodes: fake nodes that the tests will be run on. The first node is the "master" node that will orchestrate the test. Each node is specified by a Table. That Table consists of:
| Key | Value Type | Value Description |
|---|---|---|
port | Integer > 0 | Port to run node on (must not be already bound) |
home | Path | Where to place node's home directory |
fake_node_name | String | Name of fake node |
password | String or Null | Password of fake node (default: "secret") |
rpc | String or Null | wss:// URI of Ethereum RPC |
runtime_verbosity | Integer >= 0 | The verbosity level to start the runtime with; higher is more verbose (default: 0) |
For example:
[[tests.nodes]]
port = 8080
home = "home/first"
fake_node_name = "first.dev"
runtime_verbosity = 2
[[tests.nodes]]
port = 8081
home = "home/second"
fake_node_name = "second.dev"
Test Package Interface
A test package is a single-process package that accepts and responds with certain messages. The interface is defined as:
interface tester {
variant request {
/// lazy-load-blob: none.
run(run-request),
}
variant response {
/// lazy-load-blob: none.
run(result<_, fail-response>)
}
record run-request {
input-node-names: list<string>,
test-names: list<string>,
test-timeout: u64,
}
record fail-response {
test: string,
file: string,
line: u32,
column: u32,
}
}
world tester-sys-v0 {
import tester;
include process-v1;
}
A run request starts the test.
A run response marks the end of a test, and is either an Ok Result, indicating success, or a Err Result with information as to where the error occurred.
In the Rust language, a helper macro for failures can be found in tester_lib.rs.
The macro is fail!(): it automatically sends the Response as specified above, filing out the fields, and exits.
kit connect
kit connect is a thin wrapper over ssh to make creating SSH tunnels to remote nodes easy.
Example Usage
Without any configuration, get your SSH Address from Valet, as discussed here. Then use
kit connect --host <SSH Address>
and paste in the node's SSH password when prompted. You will be prompted for your password twice. This is to first determine the port to create the SSH tunnel to, and then to create the tunnel. You can also provide the port (Valet displays it as Local HTTP Port) and only be prompted for password once:
kit connect --host <SSH Address> --port <Valet Local HTTP Port>
It is recommended to set up your SSH configuration on your local machine and the remote host.
Then kit connect usage looks like:
kit connect --host <Host>
where <Host> here is defined in your ~/.ssh/config file.
To disconnect an SSH tunnel, use the --disconnect flag and the local port bound, by default, 9090:
kit connect 9090 --disconnect
Discussion
See discussion of why SSH tunnels are useful for development with kit here.
Briefly, creating an SSH tunnel allows you to use kit with a remote hosted node in the same way you do with a local one.
Setting up your SSH configuration will make kit connect work better.
You can find instructions for doing so here.
Arguments
$ kit connect --help
Connect (or disconnect) an SSH tunnel to a remote server
Usage: kit connect [OPTIONS] [LOCAL_PORT]
Arguments:
[LOCAL_PORT] Local port to bind [default: 9090]
Options:
-d, --disconnect If set, disconnect an existing tunnel (default: connect a new tunnel)
-o, --host <HOST> Host URL/IP Kinode is running on (not required for disconnect)
-p, --port <HOST_PORT> Remote (host) port Kinode is running on
-h, --help Print help
Optional positional arg: LOCAL_PORT
The local port to bind for the SSH tunnel.
This is the port to direct kit commands to in order to have them routed to the hosted node.
Defaults to 9090.
--disconnect
short: -d
If set, disconnect the tunnel with given LOCAL_PORT.
Else, connect a new tunnel.
--host
short: -o
Connect tunnel to this host. Required when connecting a new tunnel; not required when disconnecting.
--port
short: -p
The remote port to tunnel to.
If not given when creating a new tunnel, kit will first determine the remote port by creating a short-lived SSH connection to the remote host, then use that port.
kit reset-cache
The kit reset-cache command clears the cache where kit stores Kinode core binaries, logs, etc.
Discussion
In general, kit reset-cache should not need to be used.
There are occasionally cases where the kit cache gets corrupted.
If seeing confusing and difficult to explain behavior from kit, a kit reset-cache won't hurt.
Arguments
$ kit reset-cache --help
Reset kit cache (Kinode core binaries, logs, etc.)
Usage: kit reset-cache
Options:
-h, --help Print help
kit boot-real-node
short: kit e
kit boot-real-node starts a Kinode connected to the live network, e.g.,
kit boot-real-node
By default, boot-real-node fetches a prebuilt binary and launches the node using it.
Alternatively, boot-real-node can build a local Kinode core repo and use the resulting binary.
Example Usage
You can create a new node, creating a home directory at, e.g., ~/<my-new-node-name>.os, using
kit boot-real-node --home ~/<my-new-node-name>.os
or you can boot an existing node with home directory at, e.g., ~/<my-old-node-name>.os, using
kit boot-real-node --home ~/<my-old-node-name>.os
Discussion
kit boot-real-node makes it easier to run a node by reducing the number of steps to download the Kinode core binary and launch a node.
Be cautious using boot-real-node before Kinode core 1.0.0 launch without specifying the --version flag: the default --version latest may use a new major version of Kinode core!
Arguments
$ kit boot-real-node --help
Boot a real node
Usage: kit boot-real-node [OPTIONS] --home <HOME>
Options:
-r, --runtime-path <PATH> Path to Kinode core repo (overrides --version)
-v, --version <VERSION> Version of Kinode binary to use (overridden by --runtime-path) [default: latest] [possible values: latest, v0.8.7, v0.8.6, v0.8.5]
-p, --port <NODE_PORT> The port to run the real node on [default: 8080]
-o, --home <HOME> Path to home directory for real node
--rpc <RPC_ENDPOINT> Ethereum Optimism mainnet RPC endpoint (wss://)
--release If set and given --runtime-path, compile release build [default: debug build]
--verbosity <VERBOSITY> Verbosity of node: higher is more verbose [default: 0]
-h, --help Print help
--runtime-path
short: -r
Pass to build a local Kinode core repo and use the resulting binary to boot a real node, e.g.
kit boot-real-node --runtime-path ~/git/kinode
for a system with the Kinode core repo living at ~/git/kinode.
Overrides --version.
--version
short: -v
Fetch and run a specific version of the binary; defaults to most recent version.
Overridden by --runtime-path.
--port
short: -p
Run the real node on this port; defaults to 8080.
--home
short: -o
Required field. Path to home directory for real node.
--rpc
The Ethereum RPC endpoint to use, if desired.
--release
If --runtime-path is given, build the runtime for release; default is debug.
The tradeoffs between the release and default version are described here.
--verbosity
Set the verbosity of the node; higher is more verbose; default is 0, max is 3.
kit view-api
short: kit v
kit view-api fetches the list of APIs or a specific API for the given package.
view-api relies on a node to do so, e.g.
kit view-api --port 8080
lists all the APIs of packages downloaded by the Kinode running at port 8080.
Example Usage
# Fetch and display the API for the given package
kit view-api app-store:sys
Discussion
Packages have the option to expose their API using a WIT file. When a package is distributed, its API is posted by the distributor along with the package itself. Downloading the package also downloads the API.
Arguments
$ kit view-api --help
Fetch the list of APIs or a specific API
Usage: kit view-api [OPTIONS] [PACKAGE_ID]
Arguments:
[PACKAGE_ID] Get API of this package (default: list all APIs)
Options:
-p, --port <NODE_PORT> localhost node port; for remote see https://book.kinode.org/hosted-nodes.html#using-kit-with-your-hosted-node [default: 8080]
-d, --download-from <NODE> Download API from this node if not found
-h, --help Print help
Positional arg: PACKAGE_ID
Get the API of this package. By default, list the names of all APIs.
--port
short: -p
For nodes running on localhost, the port of the node; defaults to 8080.
--port is overridden by --url if both are supplied.
--download-from
short: -d
The mirror to download dependencies from (default: package publisher).
My First Kinode Application
In these tutorials, you'll setup your development environment and learn about the kit tools.
You'll learn about templates and also walk through writing an application from the ground up, backend and frontend.
And finally, you'll learn how to deploy applications through the Kinode App Store.
For the purposes of this documentation, terminal commands are provided as-is for ease of copying except when the output of the command is also shown.
In that case, the command is prepended with a $ to distinguish the command from the output.
The $ should not be copied into the terminal.
Environment Setup
In this section, you'll walk through setting up a Kinode development environment.
By the end, you will have created a Kinode application, or package, composed of one or more processes that run on a live Kinode.
The application will be a simple chat interface: my-chat-app.
The following assumes a Unix environment — macOS or Linux. If on Windows, get WSL first. In general, Kinode does not support Windows.
Acquiring Rust and the Kinode Development Tools (kit)
Install Rust and the Kinode Development Tools, or kit:
curl --proto '=https' --tlsv1.2 -sSf https://sh.rustup.rs | sh
cargo install --git https://github.com/kinode-dao/kit --locked
You can find a video guide that walks through setting up kit here.
Creating a New Kinode Package Template
The kit toolkit has a variety of features.
One of those tools is new, which creates a template for a Kinode package.
The new tool takes two arguments: a path to create the template directory and a name for the package:
$ kit new --help
Create a Kinode template package
Usage: kit new [OPTIONS] <DIR>
Arguments:
<DIR> Path to create template directory at (must contain only a-z, 0-9, `-`)
Options:
-a, --package <PACKAGE> Name of the package (must contain only a-z, 0-9, `-`) [default: DIR]
-u, --publisher <PUBLISHER> Name of the publisher (must contain only a-z, 0-9, `-`, `.`) [default: template.os]
-l, --language <LANGUAGE> Programming language of the template [default: rust] [possible values: rust]
-t, --template <TEMPLATE> Template to create [default: chat] [possible values: blank, chat, echo, fibonacci, file-transfer]
--ui If set, use the template with UI
-h, --help Print help
Create a package my-chat-app (you can name it anything "Kimap-safe", i.e. containing only a-z, 0-9, -; but we'll assume you're working with my-chat-app in this document):
kit new my-chat-app
Exploring the Package
Kinode packages are sets of one or more Kinode processes.
A Kinode package is represented in Unix as a directory that has a pkg/ directory within.
Each process within the package is its own directory.
By default, the kit new command creates a simple, one-process package, a chat app.
Other templates, including a Python template and a UI-enabled template can be used by passing different flags to kit new.
The default template looks like:
$ tree my-chat-app
my-chat-app
├── api
│ └── my-chat-app:template.os-v0.wit
├── Cargo.toml
├── metadata.json
├── my-chat-app
│ ├── Cargo.toml
│ └── src
│ └── lib.rs
├── pkg
│ ├── manifest.json
│ └── scripts.json
├── send
│ ├── Cargo.toml
│ └── src
│ └── lib.rs
└── test
├── my-chat-app-test
│ ├── api
│ │ └── my-chat-app-test:template.os-v0.wit
│ ├── Cargo.toml
│ ├── metadata.json
│ ├── my-chat-app-test
│ │ ├── Cargo.toml
│ │ └── src
│ │ ├── lib.rs
│ │ └── tester_lib.rs
│ └── pkg
│ └── manifest.json
└── tests.toml
The my-chat-app/ package here contains two processes, each represented by a directory:
my-chat-app/— containing the main application code, andsend/— containing a script.
Rust process directories, like the ones here, contain:
src/— source files where the code for the process lives, andCargo.toml— the standard Rust file specifying dependencies, etc., for that process.
Another standard Rust Cargo.toml file, a virtual manifest is also included in my-chat-app/ root.
Also within the package directory is a pkg/ directory.
The pkg/ dirctory contains two files:
manifest.json— required: specifes information Kinode needs to run the package, andscripts.json— optional: specifies details needed to run scripts.
The pkg/ directory is also where .wasm binaries (and, optionally, built UI files) will be deposited by kit build.
The files in the pkg/ directory are injected into the Kinode with kit start-package.
The metadata.json is a required file that contains app metadata which is used in the Kinode App Store.
The api/ directory contains the WIT API for the my-chat-app package, see more discussion below.
Lastly, the test/ directory contains tests for the my-chat-app package.
The tests.toml file specifies the configuration of the tests.
The my-chat-app-test/ direcotry is itself a package: the test for my-chat-app.
For more discussion of tests see kit run-tests, or see usage, below.
Though not included in this template, packages with a frontend have a ui/ directory as well.
For an example, look at the result of:
kit new my-chat-app-with-ui --ui
tree my-chat-app-with-ui
Note that not all templates have a UI-enabled version. More details about templates can be found here.
pkg/manifest.json
The manifest.json file contains information the Kinode needs in order to run the package:
$ cat my-chat-app/pkg/manifest.json
[
{
"process_name": "my-chat-app",
"process_wasm_path": "/my-chat-app.wasm",
"on_exit": "Restart",
"request_networking": true,
"request_capabilities": [
"http-server:distro:sys",
"vfs:distro:sys"
],
"grant_capabilities": [],
"public": true
}
]
This is a JSON array of JSON objects.
Each object represents one process that will be started when the package is installed.
A package with multiple processes need not start them all at install time.
A package may start more than one of the same process, as long as they each have a unique process_name.
Each object requires the following fields:
| Key | Value Type | Description |
|---|---|---|
"process_name" | String | The name of the process |
"process_wasm_path" | String | The path to the process |
"on_exit" | String ("None" or "Restart") or Object (covered elsewhere) | What to do in case the process exits |
"request_networking" | Boolean | Whether to ask for networking capabilities from kernel |
"request_capabilities" | Array of Strings or Objects | Strings are ProcessIds to request messaging capabilties from; Objects have a "process" field (ProcessId to request from) and a "params" field (capability to request) |
"grant_capabilities" | Array of Strings or Objects | Strings are ProcessIds to grant messaging capabilties to; Objects have a "process" field (ProcessId to grant to) and a "params" field (capability to grant) |
"public" | Boolean | Whether to allow any process to message us |
metadata.json
The metadata.json file contains ERC721 compatible metadata about the package.
The only required fields are package_name, current_version, and publisher, which are filled in with default values:
$ cat my-chat-app/metadata.json
{
"name": "my-chat-app",
"description": "",
"image": "",
"properties": {
"package_name": "my-chat-app",
"current_version": "0.1.0",
"publisher": "template.os",
"mirrors": [],
"code_hashes": {
"0.1.0": ""
},
"wit_version": 1,
"dependencies": []
},
"external_url": "",
"animation_url": ""
}
Here, the publisher is the default value ("template.os"), but for a real package, this field should contain the KNS ID of the publishing node.
The publisher can also be set with a kit new --publisher flag.
The wit_version is an optional field:
wit_version value | Resulting kinode.wit version |
|---|---|
| elided | kinode.wit 0.7.0 |
0 | kinode.wit 0.8.0 |
1 | kinode.wit 1.0.0 |
The dependencies field is also optional; see discussion in WIT APIs.
The rest of these fields are not required for development, but become important when publishing a package with the app-store.
As an aside: each process has a unique ProcessId, used to address messages to that process, that looks like
<process-name>:<package-name>:<publisher-node>
Each field separated by :s must be "Kimap safe", i.e. can only contain a-z, 0-9, - (and, for publisher node, .).
You can read more about ProcessIds here.
api/
The api/ directory is an optional directory where packages can declare their public API.
Other packages can then mark a package as a dependency in their metadata.json to include those types and functions defined therein.
The API is useful for composability and for LLM agents as definitions of "tools" for programatic access.
For further reading, see discussion in WIT APIs, the package APIs recipe, the package APIs (with workers) recipe, and kit view-api.
Building the Package
To build the package, use the kit build tool.
This tool accepts an optional directory path as the first argument, or, if none is provided, attempts to build the current working directory. As such, either of the following will work:
kit build my-chat-app
or
cd my-chat-app
kit build
Booting a Fake Kinode
Often, it is optimal to develop on a fake node.
Fake nodes are simple to set up, easy to restart if broken, and mocked networking makes development testing very straightforward.
To boot a fake Kinode for development purposes, use the kit boot-fake-node tool.
kit boot-fake-node downloads the OS- and architecture-appropriate Kinode core binary and runs it without connecting to the live network.
Instead, it connects to a mocked local network, allowing different fake nodes on the same machine to communicate with each other.
kit boot-fake-node has many optional configuration flags, but the defaults should work fine:
kit boot-fake-node
The fake node, just like a real node, will accept inputs from the terminal.
To exit from the fake node, press Ctrl + C.
By default, the fake node will bind to port 8080.
Note the port number in the output for later; it will look something like:
Serving Kinode at http://localhost:8080
kit boot-fake-node also accepts a --runtime-path argument.
When supplied, if it is a path to the Kinode core repo, it will compile and use that binary to start the node.
Or, if it is a path to a Kinode binary, it will use that binary to start the node.
For example:
kit boot-fake-node --runtime-path ~/path/to/kinode
where ~/path/to/kinode must be replaced with a path to the Kinode core repo.
Note that your node will be named fake.dev, as opposed to fake.os.
The .dev suffix is used for development nodes.
Optional: Starting a Real Kinode
Alternatively, development sometimes calls for a real node, which has access to the actual Kinode network and its providers.
To develop on a real Kinode, connect to the network and follow the instructions to setup a Kinode.
Starting the Package
Now it is time to load and initiate the my-chat-app package. For this, you will use the kit start-package tool.
Like kit build, the kit start-package tool takes an optional directory argument — the package — defaulting to the current working directory.
It also accepts a URL: the address of the node on which to initiate the package.
The node's URL can be input in one of two ways:
- If running on localhost, the port can be supplied with
-por--port, - More generally, the node's entire URL can be supplied with a
-uor--urlflag.
If neither the --port nor the --url is given, kit start-package defaults to http://localhost:8080.
You can start the package from either within or outside my-chat-app directory.
After completing the previous step, you should be one directory above the my-chat-app directory and can use the following:
kit start-package my-chat-app -p 8080
or, if you are already in the correct package directory:
kit start-package -p 8080
where here the port provided following -p must match the port bound by the node or fake node (see discussion above).
The node's terminal should display something like
Thu 22:51 app-store:sys: successfully installed my-chat-app:template.os
Congratulations: you've now built and installed your first application on Kinode!
Using the Package
To test out the functionality of my-chat-app, spin up another fake node to chat with in a new terminal:
kit boot-fake-node -o /tmp/kinode-fake-node-2 -p 8081 -f fake2.dev
The fake nodes communicate over a mocked local network.
To start the same my-chat-app on the second fake node, again note the port, and supply it with a start-package:
kit start-package my-chat-app -p 8081
or, if already in the my-chat-app/ package directory:
kit start-package -p 8081
To send a chat message from the first node, run the following in its terminal:
m our@my-chat-app:my-chat-app:template.os '{"Send": {"target": "fake2.dev", "message": "hello world"}}'
and replying, from the other terminal:
m our@my-chat-app:my-chat-app:template.os '{"Send": {"target": "fake.dev", "message": "wow, it works!"}}'
Messages can also be injected from the outside.
From a bash terminal, use kit inject-message, like so:
kit inject-message my-chat-app:my-chat-app:template.os '{"Send": {"target": "fake2.dev", "message": "hello from the outside world"}}'
kit inject-message my-chat-app:my-chat-app:template.os '{"Send": {"target": "fake.dev", "message": "replying from fake2.dev using first method..."}}' --node fake2.dev
kit inject-message my-chat-app:my-chat-app:template.os '{"Send": {"target": "fake.dev", "message": "and second!"}}' -p 8081
Testing the Package
To run the my-chat-app/ tests, first close all fake nodes and then run
kit run-tests my-chat-app
or, if already in the my-chat-app/ package directory:
kit run-tests
For more details, see kit run-tests.
Sending and Responding to a Message
In this section you will learn how to use different parts of a process, how Request-Response handling works, and other implementation details with regards to messaging.
The process you will build will be simple — it messages itself and responds to itself, printing whenever it gets messages.
Note — the app you will build in Sections 2 through 5 is not my-chat-app; it is simply a series of examples designed to demonstrate how to use the system's features.
Requirements
This section assumes you've completed the steps outlined in Environment Setup to setup your development environment or otherwise have a basic Kinode app open in your code editor of choice. You should also be actively running a Kinode (live or fake) such that you can quickly compile and test your code! Tight feedback loops when building: very important.
Starting from Scratch
If you want to hit the ground running by yourself, you can take the template code or the chess tutorial and start hacking away.
Here, you'll start from scratch and learn about every line of boilerplate.
Open src/lib.rs, clear its contents so it's empty, and code along!
The last section explained packages, the package manifest, and metadata. Every package contains one or more processes, which are the actual Wasm programs that will run on a node.
The Generating WIT Bindings and init() Function subsections explain the boilerplate code in detail, so if you just want to run some code, you can skip to Running First Bits of Code.
Generating WIT Bindings
For the purposes of this tutorial, crucial information from this Wasm documentation has been abridged in this small subsection.
A Wasm component is a wrapper around a core module that specifies its imports and exports. E.g. a Go component can communicate directly and safely with a C or Rust component. It need not even know what language another component was written in — it needs only the component interface, expressed in WIT.
The external interface of a component — its imports and exports — is described by a world.
Exports are provided by the component, and define what consumers of the component may call; imports are things the component may call.
The component, however, internally defines how that world is implemented.
This interface is defined via WIT.
WIT bindings are the glue code that is necessary for the interaction between Wasm modules and their host environment.
They may be written in any Wasm-compatible language — Kinode offers the most support for Rust with kit and process_lib.
The world, types, imports, and exports are all declared in a WIT file, and using that file, wit_bindgen generates the code for the bindings.
So, to bring it all together...
Every process must generate WIT bindings based on a WIT file for either the default process-v0 world or a package-specific world in order to interface with the Kinode kernel:
#![allow(unused)] fn main() { wit_bindgen::generate!({ path: "target/wit", world: "process-v1", }); }
init() Function
The entrypoint of a process is the init() function.
You can use the call_init!() macro as shown below.
Skip to the code to see how to do so.
The following prose is an explanation of what is happening under-the-hood in the call_init() macro.
After generating the bindings, every process must define a Component struct which implements the Guest trait (i.e. a wrapper around the process which defines the export interface, as discussed above).
The Guest trait should define a single function — init().
This is the entry point for the process, and the init() function is the first function called by the Kinode runtime when the process is started.
The definition of the Component struct can be done manually, but it's easier to import the kinode_process_lib crate (a sort of standard library for Kinode processes written in Rust) and use the call_init! macro.
#![allow(unused)] fn main() { use kinode_process_lib::{await_message, call_init, println, Address, Request, Response}; wit_bindgen::generate!({ path: "target/wit", world: "process-v1", }); call_init!(init); fn init(our: Address) { ... }
Every Kinode process written in Rust will need code that does the same thing as the code above (i.e. use the wit_bindgen::generate!() and call_init!() macros).
See kinode.wit for more details on what is imported by the WIT bindgen macro.
These imports are the necessary "system calls" for talking to other processes and runtime components on Kinode.
Note that there are a variety of imports from the process_lib including a println! macro that replaces the standard Rust one.
The our parameter tells the process what its globally-unique name is.
The init() function can either do one task and then return, or it can loop, waiting for a new message and then acting based on the nature of the message.
The first pattern is more usual for scripts that do one task and then exit.
The second pattern is more usual for long-lived state machine processes that, e.g., serve data over the network or over HTTP.
Sending a Message
The Request type from the process_lib provides all the necessary functionality to send a Message.
Request is a builder struct that abstracts over the raw interface presented in the WIT bindings.
It's very simple to use:
#![allow(unused)] fn main() { Request::to(my_target_address) .body(my_body_bytes) .send(); }
Because this process might not have capabilities to message any other (local or remote) processes, for the purposes of this tutorial, just send the message to itself.
#![allow(unused)] fn main() { Request::to(&our) .body(b"hello world") .send(); }
Note that send() returns a Result.
If you know that a target and body was set, you can safely unwrap this: send will only fail if one of those two fields are missing.
You can modify your Request to expect a Response, and your message-handling to send one back, as well as parse the received Request into a string.
#![allow(unused)] fn main() { Request::to(&our) .body(b"hello world") .expects_response(5) .send() .unwrap(); }
The expects_response method takes a timeout in seconds.
If the timeout is reached, the Request will be returned to the process that sent it as an error.
If you add that to the code above, you'll see the error after 5 seconds in your node's terminal.
Responding to a Message
Now, consider how to handle the Request.
The await_message() function returns a Result that looks like this:
#![allow(unused)] fn main() { Result<Message, SendError> }
The SendError is returned when a Request times out or, if the Request passes over the network, in case of a networking issue.
Use a match statement to check whether the incoming value is a message or an error, then branch on whether the message is a Request or a Response.
To send a Response back, import the Response type from process_lib and send one from the Request branch.
#![allow(unused)] fn main() { loop { match await_message() { Err(send_error) => println!("got SendError: {send_error}"), Ok(message) => { let body = String::from_utf8_lossy(message.body()); if message.is_request() { println!("got a request: {body}"); Response::new() .body(b"hello world to you too!") .send() .unwrap(); } else { println!("got a response: {body}"); } } } } }
Putting it all together:
#![allow(unused)] fn main() { use kinode_process_lib::{await_message, call_init, println, Address, Request, Response}; wit_bindgen::generate!({ path: "target/wit", world: "process-v1", }); call_init!(init); fn init(our: Address) { println!("begin"); Request::to(&our) .body(b"hello world") .expects_response(5) .send() .unwrap(); loop { match await_message() { Err(send_error) => println!("got SendError: {send_error}"), Ok(message) => { let body = String::from_utf8_lossy(message.body()); if message.is_request() { println!("got a request: {body}"); Response::new() .body(b"hello world to you too!") .send() .unwrap(); } else { println!("got a response: {body}"); } } } } } }
Run
kit build your_pkg_directory
kit start-package your_pkg_directory -p 8080
to see the messages being sent by your process.
You can find the full code here.
The basic structure of this process — an infinite loop of await_message() and then handling logic — can be found in the majority of Kinode processes.
The other common structure is a script-like process, that handles and sends a fixed series of messages and then exits.
In the next section, you will learn how to turn this very basic Request-Response` pattern into something that can be extensible and composable.
Messaging with More Complex Data Types
In this section, you will upgrade your app so that it can handle messages with more elaborate data types such as enums and structs.
Additionally, you will learn how to handle processes completing or crashing.
(De)Serialization With Serde
In the last section, you created a simple request-response pattern that uses strings as a body field type.
This is fine for certain limited cases, but in practice, most Kinode processes written in Rust use a body type that is serialized and deserialized to bytes using Serde.
There are a multitude of libraries that implement Serde's Serialize and Deserialize traits, and the process developer is responsible for selecting a strategy that is appropriate for their use case.
Some popular options are bincode, rmp_serde (MessagePack), and serde_json.
In this section, you will use serde_json to serialize your Rust structs to a byte vector of JSON.
Defining the body Type
Our old request looked like this:
#![allow(unused)] fn main() { Request::to(&our) .body(b"hello world") .expects_response(5) .send() .unwrap(); }
What if you want to have two kinds of messages, which your process can handle differently?
You need a type that implements the serde::Serialize and serde::Deserialize traits, and use that as your body type.
You can define your types in Rust, but then:
- Processes in other languages will then have to rewrite your types.
- Importing types is haphazard and on a per-package basis.
- Every package might place the types in a different place.
Instead, use the WIT language to define your API, discussed further here. Briefly, WIT is a language-independent way to define types and functions for Wasm components like Kinode processes. Kinode packages can define their API using a WIT file. That WIT file is used to generate code in the given language during compile-time. Kinode also defines a conventional place for these WIT APIs and provides infrastructure for viewing and importing the APIs of other packages.
interface mfa-data-demo {
variant request {
hello(string),
goodbye,
}
variant response {
hello(string),
goodbye,
}
}
world mfa-data-demo-template-dot-os-v0 {
import mfa-data-demo;
include process-v1;
}
The wit_bindgen::generate!() macro changes slightly, since the world is now as defined in the API:
#![allow(unused)] fn main() { wit_bindgen::generate!({ path: "target/wit", world: "mfa-data-demo-template-dot-os-v0", generate_unused_types: true, additional_derives: [serde::Deserialize, serde::Serialize, process_macros::SerdeJsonInto], }); }
which generates the types defined in the WIT API:
#![allow(unused)] fn main() { use crate::kinode::process::mfa_data_demo::{Request as MfaRequest, Response as MfaResponse}; }
It further adds the derives for serde so that these types can be used smoothly.
Now, when you form Requests and Responses, instead of putting a bytes-string in the body field, you can use the MfaRequest/MfaResponse type.
This comes with a number of benefits:
- You can now use the
bodyfield to send arbitrary data, not just strings. - Other programmers can look at your code and see what kinds of messages this process might send to their code.
- Other programmers can see what kinds of messages you expect to receive.
- By using an
enum(WITvariants become Rustenums), you can exhaustively handle all possible message types, and handle unexpected messages with a default case or an error.
Defining body types is just one step towards writing interoperable code.
It's also critical to document the overall structure of the program along with message blobs and metadata used, if any.
Writing interoperable code is necessary for enabling permissionless composability, and Kinode aims to make this the default kind of program, unlike the centralized web.
Handling Messages
In this example, you will learn how to handle a Request.
So, create a request that uses the new body type:
#![allow(unused)] fn main() { Request::to(&our) .body(MfaRequest::Hello("hello world".to_string())) .expects_response(5) .send() .unwrap(); }
Next, change the way you handle a message in your process to use your new body type.
Break out the logic to handle a message into its own function, handle_message().
handle_message() should branch on whether the message is a Request or Response.
Then, attempt to parse every message into the MfaRequest/MfaResponse, enum as appropriate, handle the two cases, and handle any message that doesn't comport to the type.
#![allow(unused)] fn main() { fn handle_message(message: &Message) -> anyhow::Result<bool> { if message.is_request() { match message.body().try_into()? { MfaRequest::Hello(text) => { println!("got a Hello: {text}"); Response::new() .body(MfaResponse::Hello("hello to you too!".to_string())) .send()? } MfaRequest::Goodbye => { println!("goodbye!"); Response::new().body(MfaResponse::Goodbye).send()?; return Ok(true); } } } else { match message.body().try_into()? { MfaResponse::Hello(text) => println!("got a Hello response: {text}"), MfaResponse::Goodbye => println!("got a Goodbye response"), } } Ok(false) } }
Granting Capabilities
Finally, edit your pkg/manifest.json to grant the terminal process permission to send messages to this process.
That way, you can use the terminal to send Hello and Goodbye messages.
Go into the manifest, and under the process name, edit (or add) the grant_capabilities field like so:
...
"grant_capabilities": [
"terminal:terminal:sys",
"tester:tester:sys"
],
...
Build and Run the Code!
After all this, your code should look like:
#![allow(unused)] fn main() { use crate::kinode::process::mfa_data_demo::{Request as MfaRequest, Response as MfaResponse}; use kinode_process_lib::{await_message, call_init, println, Address, Message, Request, Response}; wit_bindgen::generate!({ path: "target/wit", world: "mfa-data-demo-template-dot-os-v0", generate_unused_types: true, additional_derives: [serde::Deserialize, serde::Serialize, process_macros::SerdeJsonInto], }); fn handle_message(message: &Message) -> anyhow::Result<bool> { if message.is_request() { match message.body().try_into()? { MfaRequest::Hello(text) => { println!("got a Hello: {text}"); Response::new() .body(MfaResponse::Hello("hello to you too!".to_string())) .send()? } MfaRequest::Goodbye => { println!("goodbye!"); Response::new().body(MfaResponse::Goodbye).send()?; return Ok(true); } } } else { match message.body().try_into()? { MfaResponse::Hello(text) => println!("got a Hello response: {text}"), MfaResponse::Goodbye => println!("got a Goodbye response"), } } Ok(false) } call_init!(init); fn init(our: Address) { println!("begin"); Request::to(&our) .body(MfaRequest::Hello("hello world".to_string())) .expects_response(5) .send() .unwrap(); loop { match await_message() { Err(send_error) => println!("got SendError: {send_error}"), Ok(ref message) => match handle_message(message) { Err(e) => println!("got error while handling message: {e:?}"), Ok(should_exit) => { if should_exit { return; } } }, } } } }
You should be able to build and start your package, then see that initial Hello message.
At this point, you can use the terminal to test your message types!
You can find the full code here.
First, try sending a Hello using the m terminal script.
Get the address of your process by looking at the "started" printout that came from it in the terminal.
As a reminder, these values (<your_process>, <your_package>, <your_publisher>) can be found in the metadata.json and manifest.json package files.
m our@<your-process>:<your-package>:<your-publisher> '{"Hello": "hey there"}'
You should see the message text printed.
To grab and print the Response, append a -a 5 to the terminal command:
m our@<your-process>:<your-package>:<your-publisher> '{"Hello": "hey there"}' -a 5
Next, try a goodbye. This will cause the process to exit.
m our@<your-process>:<your-package>:<your-publisher> '"Goodbye"'
If you try to send another Hello now, nothing will happen, because the process has exited (assuming you have set on_exit: "None"; with on_exit: "Restart" it will immediately start up again).
Nice!
You can use kit start-package to try again.
Aside: on_exit
As mentioned in the previous section, one of the fields in the manifest.json is on_exit.
When the process exits, it does one of:
on_exit Setting | Behavior When Process Exits |
|---|---|
"None" | Do nothing |
"Restart" | Restart the process |
| JSON object | Send the requests described by the JSON object |
A process intended to do something once and exit should have "None" or a JSON object on_exit.
If it has "Restart", it will repeat in an infinite loop.
A process intended to run over a period of time and serve requests and responses will often have "Restart" on_exit so that, in case of crash, it will start again.
Alternatively, a JSON object on_exit can be used to inform another process of its untimely demise.
In this way, Kinode processes become quite similar to Erlang processes in that crashing can be designed into your process to increase reliability.
Frontend Time
After the last section, you should have a simple process that responds to two commands from the terminal. In this section, you'll add some basic HTTP logic to serve a frontend and accept an HTTP PUT request that contains a command.
If you're the type of person that prefers to learn by looking at a complete example, check out the chess frontend section for a real example application and a link to some frontend code.
Adding HTTP request handling
Using the built-in HTTP server will require handling a new type of Request in our main loop, and serving a Response to it.
The process_lib contains types and functions for doing so.
At the top of your process, import get_blob, homepage, and http from kinode_process_lib along with the rest of the imports.
You'll use get_blob() to grab the body bytes of an incoming HTTP request.
#![allow(unused)] fn main() { use kinode_process_lib::{ await_message, call_init, get_blob, homepage, http, println, Address, Message, Request, Response, }; }
Keep the custom WIT-defined MfaRequest the same, and keep using that for terminal input.
At the beginning of the init() function, in order to receive HTTP requests, use the kinode_process_lib::http library to bind a new path.
Binding a path will cause the process to receive all HTTP requests that match that path.
You can also bind static content to a path using another function in the library.
#![allow(unused)] fn main() { ... fn init(our: Address) { println!("begin"); let server_config = http::server::HttpBindingConfig::default().authenticated(false); let mut server = http::server::HttpServer::new(5); server.bind_http_path("/", server_config.authenticated(false)).unwrap(); ... }
http::HttpServer::bind_http_path("/", server_config) arguments mean the following:
- The first argument is the path to bind.
Note that requests will be namespaced under the process name, so this will be accessible at e.g.
/my-process-name/. - The second argument configures the binding.
A default setting here serves the page only to the owner of the node, suitable for private app access.
Here, setting
authenticated(false)serves the page to anyone with the URL.
To handle different kinds of Requests (or Responses), wrap them in a meta Req or Res:
#![allow(unused)] fn main() { #[derive(Debug, serde::Deserialize, serde::Serialize, process_macros::SerdeJsonInto)] #[serde(untagged)] // untagged as a meta-type for all incoming responses enum Req { MfaRequest(MfaRequest), HttpRequest(http::server::HttpServerRequest), } }
and match on it in the top-level handle_message():
#![allow(unused)] fn main() { fn handle_message(our: &Address, message: &Message) -> Result<bool> { if message.is_request() { match message.body().try_into()? { Req::MfaRequest(ref mfa_request) => { return Ok(handle_mfa_request(mfa_request)?); } Req::HttpRequest(http_request) => { handle_http_request(our, http_request)?; } } } else { handle_mfa_response(message.body().try_into()?)?; } Ok(false) } }
Here, the logic that was previously in handle_message() is now factored out into handle_mfa_request() and handle_mfa_response():
#![allow(unused)] fn main() { fn handle_mfa_request(request: &MfaRequest) -> Result<bool> { match request { MfaRequest::Hello(text) => { println!("got a Hello: {text}"); Response::new() .body(MfaResponse::Hello("hello to you too!".to_string())) .send()? } MfaRequest::Goodbye => { println!("goodbye!"); Response::new().body(MfaResponse::Goodbye).send()?; return Ok(true); } } Ok(false) } ... fn handle_mfa_response(response: MfaResponse) -> Result<()> { match response { MfaResponse::Hello(text) => println!("got a Hello response: {text}"), MfaResponse::Goodbye => println!("got a Goodbye response"), } Ok(()) } }
As a side-note, different apps will want to discriminate between incoming messages differently.
For example, to restrict what senders are accepted (say to your own node or to some set of allowed nodes), your process can branch on the source().node.
Handling an HTTP Message
Finally, define handle_http_message().
#![allow(unused)] fn main() { fn handle_http_request(our: &Address, request: http::server::HttpServerRequest) -> Result<()> { let Some(http_request) = request.request() else { return Err(anyhow!("received a WebSocket message, skipping")); }; if http_request.method().unwrap() != http::Method::PUT { return Err(anyhow!("received a non-PUT HTTP request, skipping")); } let Some(body) = get_blob() else { return Err(anyhow!( "received a PUT HTTP request with no body, skipping" )); }; http::server::send_response(http::StatusCode::OK, None, vec![]); Request::to(our).body(body.bytes).send().unwrap(); Ok(()) } }
Walking through the code, first, you must parse out the HTTP request from the HttpServerRequest.
This is necessary because the HttpServerRequest enum contains both HTTP protocol requests and requests related to WebSockets.
If your application only needs to handle one type of request (e.g., only HTTP requests), you could simplify the code by directly handling that type without having to check for a specific request type from the HttpServerRequest enum each time.
This example is overly thorough for demonstration purposes.
#![allow(unused)] fn main() { let Some(http_request) = request.request() else { return Err(anyhow!("received a WebSocket message, skipping")); }; }
Next, check the HTTP method in order to only handle PUT requests:
#![allow(unused)] fn main() { if http_request.method().unwrap() != http::Method::PUT { return Err(anyhow!("received a non-PUT HTTP request, skipping")); } }
Finally, grab the blob from the request, send a 200 OK response to the client, and handle the blob by sending a Request to ourselves with the blob as the body.
#![allow(unused)] fn main() { let Some(body) = get_blob() else { return Err(anyhow!( "received a PUT HTTP request with no body, skipping" )); }; http::server::send_response(http::StatusCode::OK, None, vec![]); Request::to(our).body(body.bytes).send().unwrap(); }
This could be done in a different way, but this simple pattern is useful for letting HTTP requests masquerade as in-Kinode requests.
Putting it all together, you get a process that you can build and start, then use cURL to send Hello and Goodbye requests via HTTP PUTs!
Requesting Capabilities
Also, remember to request the capability to message http-server in manifest.json:
...
"request_capabilities": [
"http-server:distro:sys"
],
...
The Full Code
#![allow(unused)] fn main() { use anyhow::{anyhow, Result}; use crate::kinode::process::mfa_data_demo::{Request as MfaRequest, Response as MfaResponse}; use kinode_process_lib::{ await_message, call_init, get_blob, homepage, http, println, Address, Message, Request, Response, }; wit_bindgen::generate!({ path: "target/wit", world: "mfa-data-demo-template-dot-os-v0", generate_unused_types: true, additional_derives: [serde::Deserialize, serde::Serialize, process_macros::SerdeJsonInto], }); // base64-encoded bytes prepended with image type like `data:image/png;base64,`, e.g. // echo "data:image/png;base64,$(base64 < gosling.png)" | tr -d '\n' > icon const ICON: &str = include_str!("./icon"); // you can embed an external URL // const WIDGET: &str = "<iframe src='https://example.com'></iframe>"; // or you can embed your own HTML const WIDGET: &str = "<html><body><h1>Hello, Kinode!</h1></body></html>"; #[derive(Debug, serde::Deserialize, serde::Serialize, process_macros::SerdeJsonInto)] #[serde(untagged)] // untagged as a meta-type for all incoming responses enum Req { MfaRequest(MfaRequest), HttpRequest(http::server::HttpServerRequest), } fn handle_mfa_request(request: &MfaRequest) -> Result<bool> { match request { MfaRequest::Hello(text) => { println!("got a Hello: {text}"); Response::new() .body(MfaResponse::Hello("hello to you too!".to_string())) .send()? } MfaRequest::Goodbye => { println!("goodbye!"); Response::new().body(MfaResponse::Goodbye).send()?; return Ok(true); } } Ok(false) } fn handle_http_request(our: &Address, request: http::server::HttpServerRequest) -> Result<()> { let Some(http_request) = request.request() else { return Err(anyhow!("received a WebSocket message, skipping")); }; if http_request.method().unwrap() != http::Method::PUT { return Err(anyhow!("received a non-PUT HTTP request, skipping")); } let Some(body) = get_blob() else { return Err(anyhow!( "received a PUT HTTP request with no body, skipping" )); }; http::server::send_response(http::StatusCode::OK, None, vec![]); Request::to(our).body(body.bytes).send().unwrap(); Ok(()) } fn handle_mfa_response(response: MfaResponse) -> Result<()> { match response { MfaResponse::Hello(text) => println!("got a Hello response: {text}"), MfaResponse::Goodbye => println!("got a Goodbye response"), } Ok(()) } fn handle_message(our: &Address, message: &Message) -> Result<bool> { if message.is_request() { match message.body().try_into()? { Req::MfaRequest(ref mfa_request) => { return Ok(handle_mfa_request(mfa_request)?); } Req::HttpRequest(http_request) => { handle_http_request(our, http_request)?; } } } else { handle_mfa_response(message.body().try_into()?)?; } Ok(false) } call_init!(init); fn init(our: Address) { println!("begin"); let server_config = http::server::HttpBindingConfig::default().authenticated(false); let mut server = http::server::HttpServer::new(5); server.bind_http_path("/api", server_config).unwrap(); server .serve_file( &our, "ui/index.html", vec!["/"], http::server::HttpBindingConfig::default(), ) .unwrap(); homepage::add_to_homepage("My First App", Some(ICON), Some("/"), Some(WIDGET)); Request::to(&our) .body(MfaRequest::Hello("hello world".to_string())) .expects_response(5) .send() .unwrap(); loop { match await_message() { Err(send_error) => println!("got SendError: {send_error}"), Ok(ref message) => match handle_message(&our, message) { Err(e) => println!("got error while handling message: {e:?}"), Ok(should_exit) => { if should_exit { return; } } }, } } } }
Use the following cURL command to send a Hello Request
Make sure to replace the URL with your node's local port and the correct process name.
Note: if you had set authenticated to true in bind_http_path(), you would need to add an Authorization header to this request with the JWT cookie of your node.
This is saved in your browser automatically on login.
curl -X PUT -d '{"Hello": "greetings"}' http://localhost:8080/mfa_fe_demo:mfa_fe_demo:template.os/api
You can find the full code here.
There are a few lines we haven't covered yet: learn more about serving a static frontend and adding a homepage icon and widget below.
Serving a static frontend
If you just want to serve an API, you've seen enough now to handle PUTs and GETs to your heart's content. But the classic personal node app also serves a webpage that provides a user interface for your program.
You could add handling to root / path to dynamically serve some HTML on every GET.
But for maximum ease and efficiency, use the static bind command on / and move the PUT handling to /api.
To do this, edit the bind commands in my_init_fn to look like this:
#![allow(unused)] fn main() { let mut server = http::server::HttpServer::new(5); server.bind_http_path("/api", server_config).unwrap(); server .serve_file( &our, "ui/index.html", vec!["/"], http::server::HttpBindingConfig::default(), ) .unwrap(); }
Here you are setting authenticated to false in the bind_http_path() call, but to true in the serve_file call.
This means the API is public; if instead you want the webpage to be served exclusively by the browser, change authenticated to true in bind_http_path() as well.
You must also add a static index.html file to the package.
UI files are stored in the ui/ directory and built into the application by kit build automatically.
Create a ui/ directory in the package root, and then a new file in ui/index.html with the following contents.
Make sure to replace the fetch URL with your process ID!
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
</head>
<body>
<main>
<h1>This is a website!</h1>
<p>Enter a message to send to the process:</p>
<form id="hello-form" class="col">
<input id="hello" required="" name="hello" placeholder="hello world" value="">
<button> PUT </button>
</form>
</main>
<script>
async function say_hello(text) {
const result = await fetch("/mfa-fe-demo:mfa-fe-demo:template.os/api", {
method: "PUT",
headers: { "Content-Type": "application/json" },
body: JSON.stringify({ "Hello": text }),
});
console.log(result);
}
document.addEventListener("DOMContentLoaded", () => {
const form = document.getElementById("hello-form");
form.addEventListener("submit", (e) => {
e.preventDefault();
e.stopPropagation();
const text = document.getElementById("hello").value;
say_hello(text);
});
});
</script>
</body>
</html>
This is a super barebones index.html that provides a form to make requests to the /api endpoint.
Additional UI dev info can be found here.
Next, add two more entries to manifest.json: messaging capabilities to the VFS which is required to store and access the UI index.html, and the homepage capability which is required to add our app to the user's homepage (next section):
...
"request_capabilities": [
"homepage:homepage:sys",
"http-server:distro:sys",
"vfs:distro:sys"
],
...
After saving ui/index.html, rebuilding the program, and starting the package again with kit bs, you should be able to navigate to your http://localhost:8080/mfa_fe_demo:mfa_fe_demo:template.os and see the form page.
Because you now set authenticated to true in the /api binding, the webpage will still work, but cURL will not.
The user will navigate to / to see the webpage, and when they make a PUT request, it will automatically happen on /api to send a message to the process.
This frontend is now fully packaged with the process — there are no more steps! Of course, this can be made arbitrarily complex with various frontend frameworks that produce a static build.
In the next and final section, learn about the package metadata and how to share this app across the Kinode network.
Adding a Homepage Icon and Widget
In this section, you will learn how to customize your app icon with a clickable link to your frontend, and how to create a widget to display on the homepage.
Adding the App to the Home Page
Encoding an Icon
Choosing an emblem is a difficult task. You may elect to use your own, or use this one:

On the command line, encode your image as base64, and prepend data:image/png;base64,:
echo "data:image/png;base64,$(base64 < gosling.png)" | tr -d '\n' > icon
Then, move icon next to lib.rs in your app's src/ directory.
Finally, include the icon data in your lib.rs file just after the imports:
#![allow(unused)] fn main() { const ICON: &str = include_str!("./icon"); }
Clicking the Button
The Kinode process lib exposes an add_to_homepage() function that you can use to add your app to the homepage.
In your init(), add the following line:
This line in the init() function adds your process, with the given icon, to the homepage:
#![allow(unused)] fn main() { server.bind_http_path("/api", server_config).unwrap(); }
Writing a Widget
A widget is an HTML iframe.
Kinode apps can send widgets to the homepage process, which will display them on the user's homepage.
They are quite simple to configure.
In add_to_homepage(), the final field optionally sets the widget:
#![allow(unused)] fn main() { server.bind_http_path("/api", server_config).unwrap(); }
which uses the WIDGET constant, here:
#![allow(unused)] fn main() { // you can embed an external URL // const WIDGET: &str = "<iframe src='https://example.com'></iframe>"; // or you can embed your own HTML const WIDGET: &str = "<html><body><h1>Hello, Kinode!</h1></body></html>"; }
After another kit bs, you should be able to reload your homepage and see your app icon under "All Apps", as well as your new widget.
To dock your app, click the heart icon on it.
Click the icon itself to go to the UI served by your app.
For an example of a more complex widget, see the source code of our app store widget, below.
Widget Case Study: App Store
The app store's widget makes a single request to the node, to determine the apps that are listed in the app store. It then creates some HTML to display the apps in a nice little list.
<html>
{{#webinclude https://raw.githubusercontent.com/kinode-dao/kinode/3719ab38e19143a7bcd501fd245c7a10b2239ee7/kinode/packages/app-store/app-store/src/http_api.rs 62:130}}
</html>
Sharing with the World
So, you've made a new process. You've tested your code and are ready to share with friends, or perhaps just install across multiple nodes in order to do more testing.
First, it's a good idea to publish the code to a public repository.
This can be added to your package metadata.json like so:
...
"website": "https://github.com/your_package_repo",
...
At a minimum you will need to publish the metadata.json.
An easy option is to publish it on GitHub.
If you use GitHub, make sure to use the static link to the specific commit, not a branch-specific URL (e.g. main) that wil change with new commits.
For example, https://raw.githubusercontent.com/nick1udwig/chat/master/metadata.json is not the correct link to use, because it will change when new commits are added.
You want to use a link like https://raw.githubusercontent.com/nick1udwig/chat/191dce595ad00a956de04b9728f479dee04863c7/metadata.json which will not change when new commits are added.
You'll need to populate the code_hashes field of metadata.json.
The hash can be found by running kit build on your package: it will be output after a successful build.
Next, review all the data in pkg/manifest.json and metadata.json.
The package_name field in metadata.json determines the name of the package.
The publisher field determines the name of the publisher (you!).
Once you're ready to share, it's quite easy.
If you are developing on a fake node, you'll have to boot a real one, then install this package locally in order to publish on the network, e.g.
kit s my-package
Using the App Store GUI
Navigate to the App Store and follow the Publish flow, which will guide you through publishing your application.
Using kit publish
Alternatively, you can publish your application from the command-line using kit publish.
To do so, you'll either need to
- Create a keystore.
- Use a Ledger.
- Use a Trezor.
The keystore is an encrypted wallet private key: the key that owns your publishing node.
See below for discussion of how to create the keystore.
To use a hardware wallet, simply input the appropriate flag to kit publish (-l for Ledger or -t for Trezor).
In addition, you'll need an ETH RPC endpoint.
See the OPTIONAL: Acquiring an RPC API Key section for a walkthrough of how to get an Alchemy API key.
Making a Keystore
Keystores, also known as Web3 Secret Storage, can be created in many ways; here, use foundrys cast.
First, get foundry, and then run:
cast wallet import -i my-wallet
following the prompts to create your keystore named my-wallet.
Running kit publish
To publish your package, run:
kit publish --metadata-uri https://raw.githubusercontent.com/path/to/metadata.json --keystore-path ~/.foundry/keystores/my-wallet --rpc wss://opt-mainnet.g.alchemy.com/v2/<ALCHEMY_API_KEY> --real
and enter the password you created when making the keystore, here my-wallet.
Congratulations, your app is now live on the network!
In-Depth Guide: Chess App
This guide will walk you through building a very simple chess app on Kinode. The final result will look like this: chess is in the basic runtime distribution so you can try it yourself.
Environment Setup
To prepare for this tutorial, follow the environment setup guide here, i.e. start a fake node and then, in another terminal, run:
kit new my-chess --template blank
cd my-chess
kit b
kit start-package
Once you have the template app installed and can see it running on your testing node, continue to the next chapter...
Chess Engine
Chess is a good example for a Kinode application walk-through because:
- The basic game logic is already readily available. There are dozens of high-quality chess libraries across many languages that can be imported into a Wasm app that runs on Kinode. We'll be using pleco.
- It's a multiplayer game, showing Kinode's p2p communications and ability to serve frontends
- It's fun!
In my-chess/Cargo.toml, which should be in the my-chess/ process directory inside the my-chess/ package directory, add pleco = "0.5" to your dependencies.
In your my-chess/src/lib.rs, replace the existing code with:
#![allow(unused)] fn main() { use pleco::Board; use kinode_process_lib::{await_message, call_init, println, Address}; wit_bindgen::generate!({ path: "target/wit", world: "process-v0", }); call_init!(init); fn init(our: Address) { println!("started"); let my-chess_board = Board::start_pos().fen(); println!("my-chess_board: {my-chess_board}"); loop { // Call await_message() to receive any incoming messages. await_message().map(|message| { if !message.is_request() { continue }; println!( "{our}: got request from {}: {}", message.source(), String::from_utf8_lossy(message.body()) ); }); } } }
Now, you have access to a chess board and can manipulate it easily.
The pleco docs show everything you can do using the pleco library.
But this isn't very interesting by itself!
Chess is a multiplayer game.
To make your app multiplayer, start by creating a persisted state for the chess app and a body format for sending messages to other nodes.
The first step to creating a multiplayer or otherwise networked project is adjusting your manifest.json to specify what capabilities your process will grant.
Go to my-chess/manifest.json and make sure your chess process is public and gets network access:
[
{
"process_name": "my-chess",
"process_wasm_path": "/my-chess.wasm",
"on_exit": "Restart",
"request_networking": true,
"request_capabilities": [],
"grant_capabilities": [],
"public": true
}
]
Now, in my-chess/src/lib.rs add the following simple Request/Response interface and persistable game state:
#![allow(unused)] fn main() { use serde::{Deserialize, Serialize}; use std::collections::{HashMap, HashSet}; #[derive(Debug, Serialize, Deserialize)] enum ChessRequest { NewGame { white: String, black: String }, Move { game_id: String, move_str: String }, Resign(String), } #[derive(Debug, Eq, PartialEq, Serialize, Deserialize)] enum ChessResponse { NewGameAccepted, NewGameRejected, MoveAccepted, MoveRejected, } /// /// Our serializable state format. /// #[derive(Debug, Serialize, Deserialize)] struct ChessState { pub games: HashMap<String, Game>, } #[derive(Clone, Debug, Serialize, Deserialize)] struct Game { /// the node with whom we are playing pub id: String, pub turns: u64, /// a string representation of the board using FEN pub board: String, /// the white player's node id pub white: String, /// the black player's node id pub black: String, pub ended: bool, } }
Creating explicit ChessRequest and ChessResponse types is the easiest way to reliably communicate between two processes.
It makes message-passing very simple.
If you get a request, you can deserialize it to ChessRequest and ignore or throw an error if that fails.
If you get a response, you can do the same but with ChessResponse.
And every request and response that you send can be serialized in kind.
More advanced apps can take on different structures, but a top-level enum to serialize/deserialize and match on is usually a good idea.
The ChessState struct shown above can also be persisted using the set_state and get_state commands exposed by Kinode's runtime.
Note that the Game struct here has board as a String.
This is because the Board type from pleco doesn't implement Serialize or Deserialize.
We'll have to convert it to a string using fen() before persisting it.
Then, you will convert it back to a Board with Board::from_fen() when you load it from state.
The code below will contain a version of the init() function that creates an event loop and handles ChessRequests.
First, however, it's important to note that these types already bake in some assumptions about our "chess protocol".
Remember, requests can either expect a response, or be fired and forgotten.
Unless a response is expected, there's no way to know if a request was received or not.
In a game like chess, most actions have a logical response.
Otherwise, there's no way to easily alert the user that their counterparty has gone offline, or started to otherwise ignore our moves.
For the sake of the tutorial, there are three kinds of requests and only two expect a response.
In our code, the NewGame and Move requests will always await a response, blocking until they receive one (or the request times out).
Resign, however, will be fire-and-forget.
While a "real" game may prefer to wait for a response, it is important to let one player resign and thus clear their state without that resignation being "accepted" by a non-responsive player, so production-grade resignation logic is non-trivial.
An aside: when building consumer-grade peer-to-peer apps, you'll find that there are in fact very few "trivial" interaction patterns. Something as simple as resigning from a one-on-one game, which would be a single POST request in a client-frontend <> server-backend architecture, requires well-thought-out negotiations to ensure that both players can walk away with a clean state machine, regardless of whether the counterparty is cooperating. Adding more "players" to the mix makes this even more complex. To keep things clean, leverage the request/response pattern and the
contextfield to store information about how to handle a given response, if you're not awaiting it in a blocking fashion.
Below, you'll find the full code for the CLI version of the app.
You can build it and install it on a node using kit.
You can interact with it in the terminal, primitively, like so (assuming your first node is fake.os and second is fake2.os):
m our@my-chess:my-chess:template.os '{"NewGame": {"white": "fake.os", "black": "fake2.os"}}'
m our@my-chess:my-chess:template.os '{"Move": {"game_id": "fake2.os", "move_str": "e2e4"}}'
(If you want to make a more ergonomic CLI app, consider parsing body as a string, or better yet, writing terminal scripts for various game actions.)
As you read through the code, you might notice a problem with this app: there's no way to see your games!
A fun project would be to add a CLI command that shows you, in-terminal, the board for a given game_id.
But in the next chapter, we'll add a frontend to this app so you can see your games in a browser.
my-chess/Cargo.toml:
[package]
name = "my-chess"
version = "0.1.0"
edition = "2021"
[profile.release]
panic = "abort"
opt-level = "s"
lto = true
[dependencies]
anyhow = "1.0"
bincode = "1.3.3"
kinode_process_lib = "0.9.0"
pleco = "0.5"
serde = { version = "1.0", features = ["derive"] }
serde_json = "1.0"
wit-bindgen = "0.24.0"
[lib]
crate-type = ["cdylib"]
[package.metadata.component]
package = "kinode:process"
my-chess/src/lib.rs:
use kinode_process_lib::{ await_message, call_init, get_typed_state, println, set_state, Address, Message, NodeId, Request, Response, }; use pleco::Board; use serde::{Deserialize, Serialize}; use std::collections::HashMap; // Boilerplate: generate the Wasm bindings for a Kinode app wit_bindgen::generate!({ path: "target/wit", world: "process-v0", }); // // Our "chess protocol" request/response format. We'll always serialize these // to a byte vector and send them over `body`. // #[derive(Debug, Serialize, Deserialize)] enum ChessRequest { NewGame { white: String, black: String }, Move { game_id: String, move_str: String }, Resign(String), } #[derive(Debug, Eq, PartialEq, Serialize, Deserialize)] enum ChessResponse { NewGameAccepted, NewGameRejected, MoveAccepted, MoveRejected, } /// /// Our serializable state format. /// #[derive(Debug, Serialize, Deserialize)] struct ChessState { pub games: HashMap<String, Game>, } #[derive(Clone, Debug, Serialize, Deserialize)] struct Game { /// the node with whom we are playing pub id: String, pub turns: u64, /// a string representation of the board using FEN pub board: String, /// the white player's node id pub white: String, /// the black player's node id pub black: String, pub ended: bool, } /// Helper function to serialize and save the process state. fn save_chess_state(state: &ChessState) { set_state(&bincode::serialize(&state.games).unwrap()); } /// Helper function to deserialize the process state. Note that we use a helper function /// from process_lib to fetch a typed state, which will return None if the state does /// not exist OR fails to deserialize. In either case, we'll make an empty new state. fn load_chess_state() -> ChessState { match get_typed_state(|bytes| bincode::deserialize::<HashMap<String, Game>>(bytes)) { Some(games) => ChessState { games }, None => ChessState { games: HashMap::new(), }, } } call_init!(init); fn init(our: Address) { // A little printout to show in terminal that the process has started. println!("started"); // Grab our state, then enter the main event loop. let mut state: ChessState = load_chess_state(); main_loop(&our, &mut state); } fn main_loop(our: &Address, state: &mut ChessState) { loop { // Call await_message() to receive any incoming messages. // If we get a network error, make a print and throw it away. // In a high-quality consumer-grade app, we'd want to explicitly handle // this and surface it to the user. match await_message() { Err(send_error) => { println!("got network error: {send_error:?}"); continue; } Ok(message) => { if let Err(e) = handle_request(&our, &message, state) { println!("error while handling request: {e:?}"); } } } } } /// Handle chess protocol messages from ourself *or* other nodes. fn handle_request(our: &Address, message: &Message, state: &mut ChessState) -> anyhow::Result<()> { // Throw away responses. We never expect any responses *here*, because for every // chess protocol request, we *await* its response in-place. This is appropriate // for direct node<>node comms, less appropriate for other circumstances... if !message.is_request() { return Err(anyhow::anyhow!("message was response")); } // If the request is from another node, handle it as an incoming request. // Note that we can enforce the ProcessId as well, but it shouldn't be a trusted // piece of information, since another node can easily spoof any ProcessId on a request. // It can still be useful simply as a protocol-level switch to handle different kinds of // requests from the same node, with the knowledge that the remote node can finagle with // which ProcessId a given message can be from. It's their code, after all. if message.source().node != our.node { // Deserialize the request `body` to our format, and throw it away if it // doesn't fit. let Ok(chess_request) = serde_json::from_slice::<ChessRequest>(message.body()) else { return Err(anyhow::anyhow!("invalid chess request")); }; handle_chess_request(&message.source().node, state, &chess_request) } // ...and if the request is from ourselves, handle it as our own! // Note that since this is a local request, we *can* trust the ProcessId. else { // Here, we accept messages *from any local process that can message this one*. // Since the manifest.json specifies that this process is *public*, any local process // can "play chess" for us. // // If you wanted to restrict this privilege, you could check for a specific process, // package, and/or publisher here, *or* change the manifest to only grant messaging // capabilities to specific processes. let Ok(chess_request) = serde_json::from_slice::<ChessRequest>(message.body()) else { return Err(anyhow::anyhow!("invalid chess request")); }; handle_local_request(our, state, &chess_request) } } /// handle chess protocol messages from other nodes fn handle_chess_request( source_node: &NodeId, state: &mut ChessState, action: &ChessRequest, ) -> anyhow::Result<()> { println!("handling action from {source_node}: {action:?}"); // For simplicity's sake, we'll just use the node we're playing with as the game id. // This limits us to one active game per partner. let game_id = source_node; match action { ChessRequest::NewGame { white, black } => { // Make a new game with source.node // This will replace any existing game with source.node! if state.games.contains_key(game_id) { println!("resetting game with {game_id} on their request!"); } let game = Game { id: game_id.to_string(), turns: 0, board: Board::start_pos().fen(), white: white.to_string(), black: black.to_string(), ended: false, }; // Use our helper function to persist state after every action. // The simplest and most trivial way to keep state. You'll want to // use a database or something in a real app, and consider performance // when doing intensive data-based operations. state.games.insert(game_id.to_string(), game); save_chess_state(&state); // Send a response to tell them we've accepted the game. // Remember, the other player is waiting for this. Response::new() .body(serde_json::to_vec(&ChessResponse::NewGameAccepted)?) .send()?; Ok(()) } ChessRequest::Move { move_str, .. } => { // note: ignore their game_id, just use their node ID so they can't spoof it // Get the associated game and respond with an error if // we don't have it in our state. let Some(game) = state.games.get_mut(game_id) else { // If we don't have a game with them, reject the move. Response::new() .body(serde_json::to_vec(&ChessResponse::MoveRejected)?) .send()?; return Ok(()); }; // Convert the saved board to one we can manipulate. let mut board = Board::from_fen(&game.board).unwrap(); if !board.apply_uci_move(move_str) { // Reject invalid moves! Response::new() .body(serde_json::to_vec(&ChessResponse::MoveRejected)?) .send()?; return Ok(()); } game.turns += 1; if board.checkmate() || board.stalemate() { game.ended = true; } // Persist state. game.board = board.fen(); save_chess_state(&state); // Send a response to tell them we've accepted the move. Response::new() .body(serde_json::to_vec(&ChessResponse::MoveAccepted)?) .send()?; Ok(()) } ChessRequest::Resign(_) => { // They've resigned. The sender isn't waiting for a response to this, // so we don't need to send one. if let Some(game) = state.games.get_mut(game_id) { game.ended = true; save_chess_state(&state); } Ok(()) } } } /// Handle actions we are performing. Here's where we'll send_and_await various requests. /// /// Each send_and_await here just uses a 5-second timeout. Note that this isn't waiting /// for the other *human* player to respond, but for the other *process* to respond. /// Carefully consider your timeout strategy -- sometimes it makes sense to automatically /// retry, but other times you'll want to surface the error to the user. fn handle_local_request( our: &Address, state: &mut ChessState, action: &ChessRequest, ) -> anyhow::Result<()> { match action { ChessRequest::NewGame { white, black } => { // Create a new game. We'll enforce that one of the two players is us. if white != &our.node && black != &our.node { return Err(anyhow::anyhow!("cannot start a game without us!")); } let game_id = if white == &our.node { black } else { white }; // If we already have a game with this player, throw an error. if let Some(game) = state.games.get(game_id) { if !game.ended { return Err(anyhow::anyhow!("already have a game with {game_id}")); } } // Send the other player a NewGame request // The request is exactly the same as what we got from terminal. // We'll give them 5 seconds to respond... let Ok(Message::Response { ref body, .. }) = Request::to((game_id, our.process.clone())) .body(serde_json::to_vec(&action)?) .send_and_await_response(5)? else { return Err(anyhow::anyhow!( "other player did not respond properly to new game request" )); }; // If they accept, create a new game — otherwise, error out. if serde_json::from_slice::<ChessResponse>(body)? != ChessResponse::NewGameAccepted { return Err(anyhow::anyhow!("other player rejected new game request!")); } // New game with default board. let game = Game { id: game_id.to_string(), turns: 0, board: Board::start_pos().fen(), white: white.to_string(), black: black.to_string(), ended: false, }; state.games.insert(game_id.to_string(), game); save_chess_state(&state); Ok(()) } ChessRequest::Move { game_id, move_str } => { // Make a move. We'll enforce that it's our turn. The game_id is the // person we're playing with. let Some(game) = state.games.get_mut(game_id) else { return Err(anyhow::anyhow!("no game with {game_id}")); }; if (game.turns % 2 == 0 && game.white != our.node) || (game.turns % 2 == 1 && game.black != our.node) { return Err(anyhow::anyhow!("not our turn!")); } else if game.ended { return Err(anyhow::anyhow!("that game is over!")); } let mut board = Board::from_fen(&game.board).unwrap(); if !board.apply_uci_move(move_str) { return Err(anyhow::anyhow!("illegal move!")); } // Send the move to the other player, then check if the game is over. // The request is exactly the same as what we got from terminal. // We'll give them 5 seconds to respond... let Ok(Message::Response { ref body, .. }) = Request::to((game_id, our.process.clone())) .body(serde_json::to_vec(&action)?) .send_and_await_response(5)? else { return Err(anyhow::anyhow!( "other player did not respond properly to our move" )); }; if serde_json::from_slice::<ChessResponse>(body)? != ChessResponse::MoveAccepted { return Err(anyhow::anyhow!("other player rejected our move")); } game.turns += 1; if board.checkmate() || board.stalemate() { game.ended = true; } game.board = board.fen(); save_chess_state(&state); Ok(()) } ChessRequest::Resign(ref with_who) => { // Resign from a game with a given player. let Some(game) = state.games.get_mut(with_who) else { return Err(anyhow::anyhow!("no game with {with_who}")); }; // send the other player an end game request — no response expected Request::to((with_who, our.process.clone())) .body(serde_json::to_vec(&action)?) .send()?; game.ended = true; save_chess_state(&state); Ok(()) } } }
That's it! You now have a fully peer-to-peer chess game that can be played (awkwardly) through your Kinode terminal.
In the next chapter, we'll add a frontend to this app so you can play it more easily.
Adding a Frontend
Here, you'll add a web frontend to the code from the previous section.
Creating a web frontend has two parts:
- Altering the process code to serve and handle HTTP requests
- Writing a webpage to interact with the process. Here, you'll use React to make a single-page app that displays your current games and allows us to: create new games, resign from games, and make moves on the chess board.
JavaScript and React development aren't in the scope of this tutorial, so you can find that code here.
The important part of the frontend for the purpose of this tutorial is how to set up those pre-existing files to be built and installed by kit.
When files found in the ui/ directory, if a package.json file is found with a build:copy field in scripts, kit will run that to build the UI (see here).
The build:copy in that file builds the UI and then places the resulting files into the pkg/ui/ directory where they will be installed by kit start-package.
This allows your process to fetch them from the virtual filesystem, as all files in pkg/ are mounted.
See the VFS API overview to see how to use files mounted in pkg/.
Additional UI dev info can be found here.
Get the chess UI files and place them in the proper place (next to pkg/):
# run in the top-level directory of your my-chess package
git clone https://github.com/kinode-dao/chess-ui ui
Chess will use the built-in HTTP server runtime module to serve a static frontend and receive HTTP requests from it. You'll also use a WebSocket connection to send updates to the frontend when the game state changes.
In my-chess/src/lib.rs, inside init():
#![allow(unused)] fn main() { use kinode_process_lib::{http::server, homepage}; // add ourselves to the homepage homepage::add_to_homepage("My Chess App", None, Some("/"), None); // create an HTTP server struct with which to manipulate `http-server:distro:sys` let mut http-server = server::HttpServer::new(5); let http_config = server::HttpBindingConfig::default(); // Serve the index.html and other UI files found in pkg/ui at the root path. http-server .serve_ui(&our, "ui", vec!["/"], http_config.clone()) .expect("failed to serve ui"); // Allow HTTP requests to be made to /games; they will be handled dynamically. http-server .bind_http_path("/games", http_config.clone()) .expect("failed to bind /games"); // Allow websockets to be opened at / (our process ID will be prepended). http-server .bind_ws_path("/", server::WsBindingConfig::default()) .expect("failed to bind ws"); }
The above code should be inserted into the init() function such that the frontend is served when the process starts.
The http library in process_lib provides a simple interface for serving static files and handling HTTP requests.
Use serve_ui to serve the static files included in the process binary, and bind_http_path to handle requests to /games.
serve_ui takes five arguments: the process Address, the name of the folder inside pkg that contains the index.html and other associated UI files, the path(s) on which to serve the UI (usually just ["/"]), and the HttpBindingConfig to use.
See process_lib docs for more functions and documentation on their parameters.
These requests all serve HTTP that can only be accessed by a logged-in node user (the true parameter for authenticated in HttpBindingConfig) and can be accessed remotely (the false parameter for local_only).
Requests on the /games path will arrive as requests to your process, and you'll have to handle them and respond.
To do this, add a branch to the main request-handling function that takes requests from our http-server:distro:sys.
In my-chess/src/lib.rs, inside the part of handle_request() that handles local requests:
#![allow(unused)] fn main() { ... // if the message is from the HTTP server runtime module, we should handle it // as an HTTP request and not a chess request if message.source().process == "http-server:distro:sys" { return handle_http_request(state, http-server, message); } ... }
Now, write the handle_http_request function to take incoming HTTP requests and return HTTP responses.
This will serve the same purpose as the handle_local_request function from the previous chapter, meaning that the frontend will produce actions and the backend will execute them.
An aside: As a process dev, you should be aware that HTTP resources served in this way can be accessed by other processes running on the same node, regardless of whether the paths are authenticated or not. This can be a security risk: if your app is handling sensitive actions from the frontend, a malicious app could make those API requests instead. You should never expect users to "only install non-malicious apps" — instead, use a secure subdomain to isolate your app's HTTP resources from other processes. See the HTTP Server API for more details.
In my-chess/src/lib.rs:
#![allow(unused)] fn main() { /// Handle HTTP requests from our own frontend. fn handle_http_request( state: &mut ChessState, http-server: &mut server::HttpServer, message: &Message, ) -> anyhow::Result<()> { let request = http-server.parse_request(message.body())?; // the HTTP server helper struct allows us to pass functions that // handle the various types of requests we get from the frontend http-server.handle_request( request, |incoming| { // client frontend sent an HTTP request, process it and // return an HTTP response // these functions can reuse the logic from handle_local_request // after converting the request into the appropriate format! match incoming.method().unwrap_or_default() { http::Method::GET => handle_get(state), http::Method::POST => handle_post(state), http::Method::PUT => handle_put(state), http::Method::DELETE => handle_delete(state, &incoming), _ => ( server::HttpResponse::new(http::StatusCode::METHOD_NOT_ALLOWED), None, ), } }, |_channel_id, _message_type, _message| { // client frontend sent a websocket message // we don't expect this! we only use websockets to push updates }, ); Ok(()) } }
Of course, we must now implement the handle_get, handle_post, handle_put, and handle_delete functions.
These will parse the incoming requests, convert them to our ChessRequest format, use the function defined in the last chapter to apply them to our state machine, and return the appropriate HTTP responses.
#![allow(unused)] fn main() { /// On GET: return all active games fn handle_get(state: &mut ChessState) -> (server::HttpResponse, Option<LazyLoadBlob>) { ( server::HttpResponse::new(http::StatusCode::OK), Some(LazyLoadBlob { mime: Some("application/json".to_string()), bytes: serde_json::to_vec(&state.games).expect("failed to serialize games!"), }), ) } /// On POST: create a new game fn handle_post(state: &mut ChessState) -> (server::HttpResponse, Option<LazyLoadBlob>) { let Some(blob) = get_blob() else { return ( server::HttpResponse::new(http::StatusCode::BAD_REQUEST), None, ); }; let Ok(blob_json) = serde_json::from_slice::<serde_json::Value>(&blob.bytes) else { return ( server::HttpResponse::new(http::StatusCode::BAD_REQUEST), None, ); }; let Some(game_id) = blob_json["id"].as_str() else { return ( server::HttpResponse::new(http::StatusCode::BAD_REQUEST), None, ); }; let player_white = blob_json["white"] .as_str() .unwrap_or(state.our.node.as_str()) .to_string(); let player_black = blob_json["black"].as_str().unwrap_or(game_id).to_string(); match handle_local_request( state, &ChessRequest::NewGame(NewGameRequest { white: player_white, black: player_black, }), ) { Ok(game) => ( server::HttpResponse::new(http::StatusCode::OK) .header("Content-Type", "application/json"), Some(LazyLoadBlob { mime: Some("application/json".to_string()), bytes: serde_json::to_vec(&game).expect("failed to serialize game!"), }), ), Err(e) => ( server::HttpResponse::new(http::StatusCode::BAD_REQUEST), Some(LazyLoadBlob { mime: Some("application/text".to_string()), bytes: e.to_string().into_bytes(), }), ), } } /// On PUT: make a move fn handle_put(state: &mut ChessState) -> (server::HttpResponse, Option<LazyLoadBlob>) { let Some(blob) = get_blob() else { return ( server::HttpResponse::new(http::StatusCode::BAD_REQUEST), None, ); }; let Ok(blob_json) = serde_json::from_slice::<serde_json::Value>(&blob.bytes) else { return ( server::HttpResponse::new(http::StatusCode::BAD_REQUEST), None, ); }; let Some(game_id) = blob_json["id"].as_str() else { return ( server::HttpResponse::new(http::StatusCode::BAD_REQUEST), None, ); }; let Some(move_str) = blob_json["move"].as_str() else { return ( server::HttpResponse::new(http::StatusCode::BAD_REQUEST), None, ); }; match handle_local_request( state, &ChessRequest::Move(MoveRequest { game_id: game_id.to_string(), move_str: move_str.to_string(), }), ) { Ok(game) => ( server::HttpResponse::new(http::StatusCode::OK) .header("Content-Type", "application/json"), Some(LazyLoadBlob { mime: Some("application/json".to_string()), bytes: serde_json::to_vec(&game).expect("failed to serialize game!"), }), ), Err(e) => ( server::HttpResponse::new(http::StatusCode::BAD_REQUEST), Some(LazyLoadBlob { mime: Some("application/text".to_string()), bytes: e.to_string().into_bytes(), }), ), } } /// On DELETE: end the game fn handle_delete( state: &mut ChessState, request: &server::IncomingHttpRequest, ) -> (server::HttpResponse, Option<LazyLoadBlob>) { let Some(game_id) = request.query_params().get("id") else { return ( server::HttpResponse::new(http::StatusCode::BAD_REQUEST), None, ); }; match handle_local_request(state, &ChessRequest::Resign(game_id.to_string())) { Ok(game) => ( server::HttpResponse::new(http::StatusCode::OK) .header("Content-Type", "application/json"), Some(LazyLoadBlob { mime: Some("application/json".to_string()), bytes: serde_json::to_vec(&game).expect("failed to serialize game!"), }), ), Err(e) => ( server::HttpResponse::new(http::StatusCode::BAD_REQUEST), Some(LazyLoadBlob { mime: Some("application/text".to_string()), bytes: e.to_string().into_bytes(), }), ), } } }
Are you ready to play chess?
Almost there!
One more missing piece: the backend needs to send WebSocket updates to the frontend after each move in order to update the board without a refresh.
Since open channels are already tracked in HttpServer, you just need to send a push to each open channel when a move occurs.
In my-chess/src/lib.rs, add a helper function:
#![allow(unused)] fn main() { fn send_ws_update(http-server: &mut server::HttpServer, game: &Game) { http-server.ws_push_all_channels( "/", server::WsMessageType::Binary, LazyLoadBlob { mime: Some("application/json".to_string()), bytes: serde_json::json!({ "kind": "game_update", "data": game, }) .to_string() .into_bytes(), }, ) } }
Now, anywhere you receive an action from another node (in handle_chess_request(), for example), call send_ws_update(&our, &game, &state.clients)? to send an update to all connected clients.
A good place to do this is right after saving the updated state.
Local moves from the frontend will update on their own.
Finally, add requests for http-server and vfs messaging capabilities to the manifest.json:
...
"request_capabilities": [
"http-server:distro:sys",
"vfs:distro:sys"
],
...
Continue to Putting Everything Together to see the full code and screenshots of the app in action.
Putting Everything Together
After adding a frontend in the previous chapter, your chess game is ready to play.
Hopefully, you've been using kit build <your_chess_app_name> to test the code as the tutorial has progressed.
If not, do so now in order to get a compiled package you can install onto a node.
Next, use kit start-package <your_chess_app_name> -p <your_test_node_port> to install the package.
You should see the printout you added to init() in your terminal: my-chess:my-chess:template.os: start.
Remember that you determine the process names via the manifest.json file inside /pkg, and the package & publisher name from metadata.json located at the top level of the project.
Open your chess frontend by navigating to your node's URL (probably something like http://localhost:8080), and use the names you chose as the path.
For example, if your chess process name is my-chess, and your package is named my-chess, and your publisher name is template.os (the default value), you would navigate to http://localhost:8080/my-chess:my-chess:template.os.
You should see something like this:
To try it out, boot up another node, execute the kit start-package command, and invite your new node to a game.
Presto!
This concludes the main Chess tutorial. If you're interested in learning more about how to write Kinode processes, there are several great options to extend the app:
- Consider how to handle network errors and surface those to the user
- Add game tracking to the processes state, such that players can see their history
- Consider what another app might look like that uses the chess engine as a library. Alter the process to serve this use case, or add another process that can be spawned to do such a thing.
There are also extensions to this tutorial which dive into specific use cases which make the most of Kinode:
The full code is available here.
Extension 1: Chat
So, at this point you've got a working chess game with a frontend. There are a number of obvious improvements to the program to be made, as listed at the end of the last chapter. The best way to understand those improvements is to start exploring other areas of the docs, such as the chapters on capabilities-based security and the networking protocol, for error handling.
This chapter will instead focus on how to extend an existing program with new functionality. Chat is a basic feature for a chess program, but will touch the existing code in many places. This will give you a good idea of how to extend your own programs.
You need to alter at least 4 things about the program:
- The request-response types it can handle (i.e. the protocol itself)
- The incoming request handler for HTTP requests, to receive chats sent by
ournode - The outgoing websocket update, to send received chats to the frontend
- The frontend, to display the chat
Handling them in that order, first, look at the types used for request-response now:
#![allow(unused)] fn main() { #[derive(Debug, Serialize, Deserialize)] enum ChessRequest { NewGame { white: String, black: String }, Move { game_id: String, move_str: String }, Resign(String), } #[derive(Debug, Eq, PartialEq, Serialize, Deserialize)] enum ChessResponse { NewGameAccepted, NewGameRejected, MoveAccepted, MoveRejected, } }
These types need to be exhaustive, since incoming messages will be fed into a match statement that uses ChessRequest and ChessResponse.
For more complex apps, one could introduce a new type that serves as an umbrella over multiple "kinds" of message, but since a simple chat will only be a few extra entries into the existing types, it's unnecessary for this example.
In order to add chat, the request type above will need a new variant, something like Message(String).
It doesn't need a from field, since that's just the source of the message!
A new response type will make the chat more robust, by acknowledging received messages.
Something like MessageAck will do, with no fields — since this will be sent in response to a Message request, the sender will know which message it's acknowledging.
The new types will look like this:
#![allow(unused)] fn main() { #[derive(Debug, Serialize, Deserialize)] enum ChessRequest { NewGame { white: String, black: String }, Move { game_id: String, move_str: String }, Resign(String), Message(String), } #[derive(Debug, Eq, PartialEq, Serialize, Deserialize)] enum ChessResponse { NewGameAccepted, NewGameRejected, MoveAccepted, MoveRejected, MessageAck, } }
If you are modifying these types inside the finished chess app from this tutorial, your IDE should indicate that there are a few errors now: these new message types are not handled in their respective match statements.
Those errors, in handle_chess_request and handle_local_request, are where you'll need logic to handle messages other nodes send to this node, and messages this node sends to others, respectively.
In handle_chess_request, the app receives requests from other nodes.
A reasonable way to handle incoming messages is to add them to a vector of messages that's saved for each active game.
The frontend could reflect this by adding a chat box next to each game, and displaying all messages sent over that game's duration.
To do that, the Game struct must be altered to hold such a vector.
#![allow(unused)] fn main() { struct Game { pub id: String, // the node with whom we are playing pub turns: u64, pub board: String, pub white: String, pub black: String, pub ended: bool, /// messages stored in order as (sender, content) pub messages: Vec<(String, String)>, } }
Then in the main switch statement in handle_chess_request:
#![allow(unused)] fn main() { ... ChessRequest::Message(content) => { // Earlier in this code, we define game_id as the source node. let Some(game) = state.games.get_mut(game_id) else { return Err(anyhow::anyhow!("no game with {game_id}")); }; game.messages.push((game_id.to_string(), content.to_string())); Ok(()) } ... }
In handle_local_request, the app sends requests to other nodes.
Note, however, that requests to message ourself don't really make sense — what should really happen is that the chess frontend performs a PUT request, or sends a message over a websocket, and the chess backend process turns that into a message request to the other player.
So instead of handling Message requests in handle_local_request, the process should reject or ignore them:
#![allow(unused)] fn main() { ChessRequest::Message(_) => { Ok(()) } }
Instead, the chess backend will handle a new kind of PUT request in handle_http_request, such that the local frontend can be used to send messages in games being played.
This is the current (super gross!!) code for handling PUT requests in handle_http_request:
#![allow(unused)] fn main() { // on PUT: make a move "PUT" => { let Some(blob) = get_blob() else { return http::send_response(http::StatusCode::BAD_REQUEST, None, vec![]); }; let blob_json = serde_json::from_slice::<serde_json::Value>(&blob.bytes)?; let Some(game_id) = blob_json["id"].as_str() else { return http::send_response(http::StatusCode::BAD_REQUEST, None, vec![]); }; let Some(game) = state.games.get_mut(game_id) else { return http::send_response(http::StatusCode::NOT_FOUND, None, vec![]); }; if (game.turns % 2 == 0 && game.white != our.node) || (game.turns % 2 == 1 && game.black != our.node) { return http::send_response(http::StatusCode::FORBIDDEN, None, vec![]); } else if game.ended { return http::send_response(http::StatusCode::CONFLICT, None, vec![]); } let Some(move_str) = blob_json["move"].as_str() else { return http::send_response(http::StatusCode::BAD_REQUEST, None, vec![]); }; let mut board = Board::from_fen(&game.board).unwrap(); if !board.apply_uci_move(move_str) { // reader note: can surface illegal move to player or something here return http::send_response(http::StatusCode::BAD_REQUEST, None, vec![]); } // send the move to the other player // check if the game is over // if so, update the records let Ok(msg) = Request::new() .target((game_id, our.process.clone())) .body(serde_json::to_vec(&ChessRequest::Move { game_id: game_id.to_string(), move_str: move_str.to_string(), })?) .send_and_await_response(5)? else { return Err(anyhow::anyhow!( "other player did not respond properly to our move" )); }; if serde_json::from_slice::<ChessResponse>(msg.body())? != ChessResponse::MoveAccepted { return Err(anyhow::anyhow!("other player rejected our move")); } // update the game game.turns += 1; if board.checkmate() || board.stalemate() { game.ended = true; } game.board = board.fen(); // update state and return to FE let body = serde_json::to_vec(&game)?; save_chess_state(&state); // return the game http::send_response( http::StatusCode::OK, Some(HashMap::from([( String::from("Content-Type"), String::from("application/json"), )])), body, ) } }
Let's modify this to handle more than just making moves. Note that there's an implicit JSON structure enforced by the code above, where PUT requests from your frontend look like this:
{
"id": "game_id",
"move": "e2e4"
}
An easy way to allow messages is to match on whether the key "move" is present, and if not, look for the key "message".
This could also easily be codified as a Rust type and deserialized.
Now, instead of assuming "move" exists, let's add a branch that handles the "message" case.
This is a modification of the code above:
#![allow(unused)] fn main() { // on PUT: make a move OR send a message "PUT" => { // ... same as the previous snippet ... let Some(move_str) = blob_json["move"].as_str() else { let Some(message) = blob_json["message"].as_str() else { return http::send_response(http::StatusCode::BAD_REQUEST, None, vec![]); }; // handle sending message to another player let Ok(_ack) = Request::new() .target((game_id, our.process.clone())) .body(serde_json::to_vec(&ChessRequest::Message(message.to_string()))?) .send_and_await_response(5)? else { // Reader Note: handle a failed message send! return Err(anyhow::anyhow!( "other player did not respond properly to our message" )); }; game.messages.push((our.node.clone(), message.to_string())); let body = serde_json::to_vec(&game)?; save_chess_state(&state); // return the game return http::send_response( http::StatusCode::OK, Some(HashMap::from([( String::from("Content-Type"), String::from("application/json"), )])), body, ); }; // // ... the rest of the move-handling code, same as previous snippet ... // } }
That's it. A simple demonstration of how to extend the functionality of a given process. There are a few key things to keep in mind when doing this, if you want to build stable, maintainable, upgradable applications:
-
By adding chat, you changed the format of the "chess protocol" implicitly declared by this program. If a user is running the old code, their version won't know how to handle the new
Messagerequest type you added. Depending on the serialization/deserialization strategy used, this might even create incompatibilities with the other types of requests. This is a good reason to use a serialization strategy that allows for "unknown" fields, such as JSON. If you're using a binary format, you'll need to be more careful about how you add new fields to existing types. -
It's okay to break backwards compatibility with old versions of an app, but once a protocol is established, it's best to stick to it or start a new project. Backwards compatibility can always be achieved by adding a version number to the request/response type(s) directly. That's a simple way to know which version of the protocol is being used and handle it accordingly.
-
By adding a
messagesfield to theGamestruct, you changed the format of the state that gets persisted. If a user was running the previous version of this process, and upgrades to this version, the old state will fail to properly deserialize. If you are building an upgrade to an existing app, you should always test that the new version can appropriately handle old state. If you have many versions, you might need to make sure that state types from any old version can be handled. Again, inserting a version number that can be deserialized from persisted state is a useful strategy. The best way to do this depends on the serialization strategy used.
Cookbook Overview
The Cookbook is a collection of how-tos for common programming techniques that may be useful for the Kinode developer. The entries include a basic explanation as well as some bare bones sample code to illustrate how you might use the technique. Think of them as individual recipes that can be combined to form the outline for any variety of useful, interesting applications.
Saving State
Every Kinode process has access to two system calls that save and load persistent state: set_state and get_state.
set_state takes a byte-vector and saves it in the kernel's disk storage.
get_state takes no arguments and returns an optional byte-vector.
If the byte-vector is present, it was previously saved by set_state.
If the byte-vector is not present, it was not previously saved.
The byte-vector itself is opaque to the kernel, though not encrypted.
It can be retrieved later only by get_state, and only the original process that called set_state can retrieve it.
Processes frequently use this feature to maintain key state between restarts, which can happen at any time as a result of crashes, package updates, or node reboots. It is considered good practice to save state any time the process mutates it.
Keep in mind that every state set/get incurs an asynchronous disk read/write for the entire state object.
If storing large amounts of data, consider using the vfs, sqlite, and/or kv modules!
Here's an example of a process that saves and loads state:
#![allow(unused)] fn main() { /// Simple example of saving and loading state. /// Usage: /// ``` /// # Start node. /// kit f /// /// # Start package from a new terminal. /// kit bs save_state /// /// # Watch as process continually restarts, incrementing the counter in state. /// ``` use kinode_process_lib::{call_init, get_state, println, set_state, Address}; wit_bindgen::generate!({ path: "target/wit", world: "process-v1", }); call_init!(init); fn init(_our: Address) { println!("init"); match get_state() { None => { println!("no state found"); let counter: u64 = 0; set_state(&counter.to_le_bytes()); } Some(state) => { let mut counter = u64::from_le_bytes(state.try_into().unwrap()); println!("counter: {}", counter); counter += 1; set_state(&counter.to_le_bytes()); } } std::thread::sleep(std::time::Duration::from_secs(2)); } }
This process has a simple u64 counter that is incremented on each initialization.
It then exits and is restarted (because of its designated behavior in manifest.json), and the counter is loaded from state and incremented again.
State serialization and deserialization can be done in a variety of ways, and usually uses serde::Serialize and serde::Deserialize derived on a particular struct.
When using process state, make sure to handle the case where the state is not present, and if updating an existing process, always handle older state formats if you change the format being stored.
Spawning and Managing Child Processes
A "parent" process can create additional processes, known as "children" (also discussed here). These child processes are particularly useful for handling intensive tasks (referred to as "workers") that require long computation times without hindering the performance of the main application. They are also beneficial for segregating distinct logical components. Each process is its own subdirectory within the package. E.g., for Kinode processes written in Rust, each is its own Rust project, complete with a separate Cargo.toml file.
Your package's file structure might resemble the following:
spawn
├── Cargo.toml
├── metadata.json
├── child
│ ├── Cargo.toml
│ └── src
├── parent
│ ├── Cargo.toml
│ └── src
├── pkg
...
To start a child process, use the spawn() function from kinode_process_lib.
The following example demonstrates a basic parent process whose sole function is to spawn a child process and grant it the ability to send messages using http-client:
#![allow(unused)] fn main() { // imports use kinode_process_lib::{call_init, println, spawn, Address, Capability, OnExit, ProcessId}; // boilerplate to generate types wit_bindgen::generate!({ path: "target/wit", world: "process-v1", }); // parent app component boilerplate call_init!(init); fn init(our: Address) { println!("{our}: start"); // this function actually spawns the child process let _spawned_process_id = match spawn( // name of the child process (None -> random number) Some("spawned-child-process"), // path to find the compiled Wasm file for the child process &format!("{}/pkg/child.wasm", our.package_id()), // what to do when child crashes/panics/finishes OnExit::None, // capabilities to pass onto the child vec![ // the parent process already has the capability to message // http-client here so we are just passing it onto the child Capability { issuer: Address::new( &our.node, "http-client:distro:sys".parse::<ProcessId>().unwrap(), ), params: "\"messaging\"".into(), }, ], // allow tester to message child in case this is being run as a test vec![( "tester:tester:sys".parse::<ProcessId>().unwrap(), "\"messaging\"".to_string(), )], // this process will not be public: only processes with proper caps can message it false, ) { Ok(spawned_process_id) => spawned_process_id, Err(e) => { panic!("couldn't spawn: {e:?}"); } }; } }
The child process can be anything, for simplicity's sake, here is a degenerate process that does nothing but print its name and die:
#![allow(unused)] fn main() { // same boilerplate as above #[cfg(feature = "test")] use kinode_process_lib::{await_message, Response}; use kinode_process_lib::{call_init, println, Address}; wit_bindgen::generate!({ path: "target/wit", world: "process-v1", }); call_init!(init); fn init(our: Address) { println!("{our}: start"); // print something else out println!("this is the child process, wow!"); #[cfg(feature = "test")] { println!("child awaiting message from test..."); let _message = await_message().unwrap(); Response::new() .body(serde_json::to_vec(&Ok::<(), ()>(())).unwrap()) .send() .unwrap(); } } }
The spawn function in Kinode comprises several parameters, each serving a specific purpose in the process creation:
-
name: Option<String>: This parameter specifies the name of the process. If set to None, the process is automatically assigned a numerical identifier, resulting in a ProcessId formatted like123456789:my-package:john.os. -
wasm_path: String: Indicates the location of the compiled WebAssembly (Wasm) bytecode for the process. -
on_exit: OnExit: Determines the behavior of the process upon termination, whether due to completion, a crash, or a panic. OnExit is an enum with three potential values:None: The process will take no action upon exiting.Restart: The process will automatically restart after termination.Requests: Vec<(Address, Request, Option<LazyLoadBlob>)>: Upon process termination, a series of predefined requests will be dispatched.
-
request_capabilities: Vec<Capability>: This argument is for passing immediate capabilities to the child process. As illustrated in the provided example, the parent'shttp-clientmessaging capability was shared with the child. -
grant_capabilities: Vec<ProcessId>: This argument is for granting capabilities to other processes on start. However, for security reasons, you limit it just to the"messaging"cap for messaging this process back, hence why it is aVec<ProcessId>instead of vector of arbitrary capabilities. -
public: bool: This boolean value determines whether the process can receive messages from other processes by default.
The fields within the spawn function closely mirror those found in the pkg/manifest.json file of your project, providing a consistent and intuitive setup for process management.
Publishing a Website or Web App
Publishing a website or web app is quite simple.
There are helper functions to make this a one-line call if you have properly uploaded the relevant files from your development /pkg directory.
All of these functions expect you to place your index.html within a directory in /pkg.
In the following examples, that directory would be /pkg/ui.
All other files should be in a directory called assets inside of ui, so /pkg/ui/assets.
The structure should look like this:
my-package
└── pkg
└── ui
├── assets
└── index.html
Serving Static Assets
The simplest way to serve a UI is using the http::HttpServer::serve_ui() method from process_lib:
let mut server = http::server::HttpServer::new(5);
server
.serve_ui(
&our,
"ui",
vec!["/"],
http::server::HttpBindingConfig::new(true, false, false, None),
)
.unwrap();
This will serve the index.html in the specified folder at the home path of your process.
If your process is called main:my-package:myusername.os and your Kinode is running locally on port 8080, then the UI will be served at http://localhost:8080/main:my-package:myusername.os.
serve_ui takes four arguments:
- The process'
&Address - The name of the folder inside
pkgthat contains theindex.htmland other associated UI files. By convention, this is theuidirectory inside of thepkgdirectory that will be uploaded when you install the process. There must be anindex.htmlin the"ui"directory (or whatever your top-level directory is called). - The path(s) on which to serve the UI (usually
["/"]) - The configuration for the binding:
- Whether the UI requires authentication
- Whether the UI is local-only
- Whether the content is static (not relevant here)
- Whether to serve as a secure subdomain
Under the hood, serve_ui uses bind_http_static_path which caches files in memory with http-server to respond to HTTP requests more quickly.
The two additional parameters are the content_type (an optional String) and the content (bytes).
The content will be served at the named route with the Content-Type header set appropriately.
Note that serve_ui caches all files in http-server, so if your website or web app has hundreds of MBs of asset files (like high-res images), then you will want to use a different method to serve content.
For example, see the docs:docs:nick.kino application.
File Transfer
This recipe looks at the file-transfer package, a template included with kit and also copied here.
To create the template use
kit n file-transfer -t file-transfer
The file-transfer package shows off a few parts of Kinode userspace:
- It makes use of the VFS to store files on disk.
- It uses a manager-worker pattern (see conceptual discussion here and here) to enable multiple concurrent uploads/downloads without sacrificing code readability.
- It exports its WIT API so that other packages can easily build in file transfer functionality in a library-like manner, as demonstrated in another recipe.
Protocol
The main file-transfer process is a thin wrapper over the file-transfer-worker-api.
The main process manages transfers and exposes a ListFiles Request variant that, when requested, returns the files that are available for download.
The file-transfer-worker-api makes calling the file-transfer-worker ergonomic.
Specifically, it provides a function, start_download(), which spins up a worker to download a file from a given node.
When called on the node serving the file, it spins up a worker to upload the requested file to the requestor.
Downloading a file proceeds as follows:
- Requestor calls
start_download(), which:spawn()s afile-transfer-worker.- Passes
file-transfer-workeraDownloadRequest variant. file-transfer-workerforwards a modifiedDownloadRequest variant to thetarget.
- Provider receives
DownloadRequest variant, callsstart_download(), which:spawn()s afile-transfer-worker.- Passes
file-transfer-workertheDownloadRequest variant. - Sends chunks of file to the requestor's
file-transfer-worker.
Thus, a worker is responsible for downloading/uploading a single file, and then exits.
All longer-term state and functionality is the responsibility of the main process, here, file-transfer.
Files are transferred from and to the file-transfer:template.os/files drive.
If you use the file-transfer-worker or file-transfer-worker-api in your own package, replace that first part of the path with your package's package id.
WIT API
#![allow(unused)] fn main() { interface file-transfer { variant request { list-files, } variant response { list-files(list<file-info>), } record file-info { name: string, size: u64, } } interface file-transfer-worker { use standard.{address}; /// external-facing requests variant request { /// download starts a download. /// * used by requestor to start whole process /// * used by provider to spin up worker to serve request download(download-request), /// progress is from worker to parent /// * acks not required, but provided for completeness progress(progress-request), } variant response { download(result<_, string>), /// ack: not required, but provided for completeness progress, } /// requests used between workers to transfer the file /// parent will not receive these, so need not handle them variant internal-request { chunk(chunk-request), size(u64), } record download-request { name: string, target: address, is-requestor: bool, } record progress-request { name: string, progress: u64, } record chunk-request { name: string, offset: u64, length: u64, } /// easiest way to use file-transfer-worker /// handle file-transfer-worker::request by calling this helper function start-download: func( our: address, source: address, name: string, target: address, is-requestor: bool, ) -> result<_, string>; } world file-transfer-worker-api-v0 { export file-transfer-worker; } world file-transfer-template-dot-os-v0 { import file-transfer; import file-transfer-worker; include process-v1; } }
Main Process
#![allow(unused)] fn main() { use crate::kinode::process::file_transfer::{ FileInfo, Request as TransferRequest, Response as TransferResponse, }; use crate::kinode::process::file_transfer_worker::{ start_download, DownloadRequest, ProgressRequest, Request as WorkerRequest, Response as WorkerResponse, }; use crate::kinode::process::standard::{Address as WitAddress, ProcessId as WitProcessId}; use kinode_process_lib::logging::{error, info, init_logging, Level}; use kinode_process_lib::{ await_message, call_init, println, vfs::{create_drive, metadata, open_dir, Directory, FileType}, Address, Message, ProcessId, Response, }; wit_bindgen::generate!({ path: "target/wit", world: "file-transfer-template-dot-os-v0", generate_unused_types: true, additional_derives: [serde::Deserialize, serde::Serialize, process_macros::SerdeJsonInto], }); #[derive(Debug, serde::Deserialize, serde::Serialize, process_macros::SerdeJsonInto)] #[serde(untagged)] // untagged as a meta-type for all incoming messages enum Msg { // requests TransferRequest(TransferRequest), WorkerRequest(WorkerRequest), // responses TransferResponse(TransferResponse), WorkerResponse(WorkerResponse), } impl From<Address> for WitAddress { fn from(address: Address) -> Self { WitAddress { node: address.node, process: address.process.into(), } } } impl From<ProcessId> for WitProcessId { fn from(process: ProcessId) -> Self { WitProcessId { process_name: process.process_name, package_name: process.package_name, publisher_node: process.publisher_node, } } } fn ls_files(files_dir: &Directory) -> anyhow::Result<Vec<FileInfo>> { let entries = files_dir.read()?; let files: Vec<FileInfo> = entries .iter() .filter_map(|file| match file.file_type { FileType::File => match metadata(&file.path, None) { Ok(metadata) => Some(FileInfo { name: file.path.clone(), size: metadata.len, }), Err(_) => None, }, _ => None, }) .collect(); Ok(files) } fn handle_transfer_request(request: &TransferRequest, files_dir: &Directory) -> anyhow::Result<()> { match request { TransferRequest::ListFiles => { let files = ls_files(files_dir)?; Response::new() .body(TransferResponse::ListFiles(files)) .send()?; } } Ok(()) } fn handle_worker_request( our: &Address, source: &Address, request: &WorkerRequest, ) -> anyhow::Result<()> { match request { WorkerRequest::Download(DownloadRequest { ref name, ref target, is_requestor, }) => { match start_download( &our.clone().into(), &source.clone().into(), name, target, *is_requestor, ) { Ok(_) => {} Err(e) => return Err(anyhow::anyhow!("{e}")), } } WorkerRequest::Progress(ProgressRequest { name, progress }) => { info!("{} progress: {}%", name, progress); Response::new().body(WorkerResponse::Progress).send()?; } } Ok(()) } fn handle_transfer_response(source: &Address, response: &TransferResponse) -> anyhow::Result<()> { match response { TransferResponse::ListFiles(ref files) => { println!( "{}", files.iter().fold( format!("{source} available files:\nFile\t\tSize (bytes)\n"), |mut msg, file| { msg.push_str(&format!( "{}\t\t{}", file.name.split('/').last().unwrap(), file.size, )); msg } ) ); } } Ok(()) } fn handle_worker_response(response: &WorkerResponse) -> anyhow::Result<()> { match response { WorkerResponse::Download(ref result) => { if let Err(e) = result { return Err(anyhow::anyhow!("{e}")); } } WorkerResponse::Progress => {} } Ok(()) } fn handle_message(our: &Address, message: &Message, files_dir: &Directory) -> anyhow::Result<()> { match message.body().try_into()? { // requests Msg::TransferRequest(ref tr) => handle_transfer_request(tr, files_dir), Msg::WorkerRequest(ref wr) => handle_worker_request(our, message.source(), wr), // responses Msg::TransferResponse(ref tr) => handle_transfer_response(message.source(), tr), Msg::WorkerResponse(ref wr) => handle_worker_response(wr), } } call_init!(init); fn init(our: Address) { init_logging(&our, Level::DEBUG, Level::INFO, None, None).unwrap(); info!("begin"); let drive_path = create_drive(our.package_id(), "files", None).unwrap(); let files_dir = open_dir(&drive_path, false, None).unwrap(); loop { match await_message() { Err(send_error) => error!("got SendError: {send_error}"), Ok(ref message) => match handle_message(&our, message, &files_dir) { Ok(_) => {} Err(e) => error!("got error while handling message: {e:?}"), }, } } } }
Worker
#![allow(unused)] fn main() { use crate::kinode::process::file_transfer_worker::{ ChunkRequest, DownloadRequest, InternalRequest, ProgressRequest, Request as WorkerRequest, Response as WorkerResponse, }; use crate::kinode::process::standard::{Address as WitAddress, ProcessId as WitProcessId}; use kinode_process_lib::logging::{error, info, init_logging, Level}; use kinode_process_lib::{ await_message, call_init, get_blob, vfs::{open_dir, open_file, Directory, File, SeekFrom}, Address, Message, ProcessId, Request, Response, }; wit_bindgen::generate!({ path: "target/wit", world: "file-transfer-template-dot-os-v0", generate_unused_types: true, additional_derives: [serde::Deserialize, serde::Serialize, process_macros::SerdeJsonInto], }); #[derive(Debug, serde::Deserialize, serde::Serialize, process_macros::SerdeJsonInto)] #[serde(untagged)] // untagged as a meta-type for all incoming messages enum Msg { // requests WorkerRequest(WorkerRequest), InternalRequest(InternalRequest), // responses WorkerResponse(WorkerResponse), } impl From<WitAddress> for Address { fn from(address: WitAddress) -> Self { Address { node: address.node, process: address.process.into(), } } } impl From<WitProcessId> for ProcessId { fn from(process: WitProcessId) -> Self { ProcessId { process_name: process.process_name, package_name: process.package_name, publisher_node: process.publisher_node, } } } const CHUNK_SIZE: u64 = 1048576; // 1MB fn handle_worker_request( request: &WorkerRequest, file: &mut Option<File>, files_dir: &Directory, ) -> anyhow::Result<bool> { match request { WorkerRequest::Download(DownloadRequest { name, target, is_requestor, }) => { Response::new() .body(WorkerResponse::Download(Ok(()))) .send()?; // open/create empty file in both cases. let mut active_file = open_file(&format!("{}/{}", files_dir.path, &name), true, None)?; if *is_requestor { *file = Some(active_file); Request::new() .expects_response(5) .body(WorkerRequest::Download(DownloadRequest { name: name.to_string(), target: target.clone(), is_requestor: false, })) .target::<Address>(target.clone().into()) .send()?; } else { // we are sender: chunk the data, and send it. let size = active_file.metadata()?.len; let num_chunks = (size as f64 / CHUNK_SIZE as f64).ceil() as u64; // give receiving worker file size so it can track download progress Request::new() .body(InternalRequest::Size(size)) .target(target.clone()) .send()?; active_file.seek(SeekFrom::Start(0))?; for i in 0..num_chunks { let offset = i * CHUNK_SIZE; let length = CHUNK_SIZE.min(size - offset); let mut buffer = vec![0; length as usize]; active_file.read_at(&mut buffer)?; Request::new() .body(InternalRequest::Chunk(ChunkRequest { name: name.clone(), offset, length, })) .target(target.clone()) .blob_bytes(buffer) .send()?; } return Ok(true); } } WorkerRequest::Progress(_) => { return Err(anyhow::anyhow!( "worker: got unexpected WorkerRequest::Progress", )); } } Ok(false) } fn handle_internal_request( request: &InternalRequest, file: &mut Option<File>, size: &mut Option<u64>, parent: &Option<Address>, ) -> anyhow::Result<bool> { match request { InternalRequest::Chunk(ChunkRequest { name, offset, length, }) => { // someone sending a chunk to us let file = match file { Some(file) => file, None => { return Err(anyhow::anyhow!( "worker: receive error: no file initialized" )); } }; let bytes = match get_blob() { Some(blob) => blob.bytes, None => { return Err(anyhow::anyhow!("worker: receive error: no blob")); } }; file.write_all(&bytes)?; // if sender has sent us a size, give a progress update to main transfer let Some(ref parent) = parent else { return Ok(false); }; if let Some(size) = size { let progress = ((offset + length) as f64 / *size as f64 * 100.0) as u64; Request::new() .expects_response(5) .body(WorkerRequest::Progress(ProgressRequest { name: name.to_string(), progress, })) .target(parent) .send()?; if progress >= 100 { return Ok(true); } } } InternalRequest::Size(incoming_size) => { *size = Some(*incoming_size); } } Ok(false) } fn handle_worker_response(response: &WorkerResponse) -> anyhow::Result<bool> { match response { WorkerResponse::Download(ref result) => { if let Err(e) = result { return Err(anyhow::anyhow!("{e}")); } } WorkerResponse::Progress => {} } Ok(false) } fn handle_message( message: &Message, file: &mut Option<File>, files_dir: &Directory, size: &mut Option<u64>, parent: &mut Option<Address>, ) -> anyhow::Result<bool> { return Ok(match message.body().try_into()? { // requests Msg::WorkerRequest(ref wr) => { *parent = Some(message.source().clone()); handle_worker_request(wr, file, files_dir)? } Msg::InternalRequest(ref ir) => handle_internal_request(ir, file, size, parent)?, // responses Msg::WorkerResponse(ref wr) => handle_worker_response(wr)?, }); } call_init!(init); fn init(our: Address) { init_logging(&our, Level::DEBUG, Level::INFO, None, None).unwrap(); info!("worker: begin"); let start = std::time::Instant::now(); let drive_path = format!("{}/files", our.package_id()); let files_dir = open_dir(&drive_path, false, None).unwrap(); let mut file: Option<File> = None; let mut size: Option<u64> = None; let mut parent: Option<Address> = None; loop { match await_message() { Err(send_error) => error!("worker: got SendError: {send_error}"), Ok(ref message) => { match handle_message(message, &mut file, &files_dir, &mut size, &mut parent) { Ok(exit) => { if exit { info!("worker: done: exiting, took {:?}", start.elapsed()); break; } } Err(e) => error!("worker: got error while handling message: {e:?}"), } } } } } }
API
#![allow(unused)] fn main() { use crate::exports::kinode::process::file_transfer_worker::{ DownloadRequest, Guest, Request as WorkerRequest, Response as WorkerResponse, }; use crate::kinode::process::standard::Address as WitAddress; use kinode_process_lib::{our_capabilities, spawn, Address, OnExit, Request, Response}; wit_bindgen::generate!({ path: "target/wit", world: "file-transfer-worker-api-v0", generate_unused_types: true, additional_derives: [serde::Deserialize, serde::Serialize, process_macros::SerdeJsonInto], }); fn start_download( our: &WitAddress, source: &WitAddress, name: &str, target: &WitAddress, is_requestor: bool, ) -> anyhow::Result<()> { // spin up a worker, initialize based on whether it's a downloader or a sender. let our_worker = spawn( None, &format!( "{}:{}/pkg/file-transfer-worker.wasm", our.process.package_name, our.process.publisher_node, ), OnExit::None, our_capabilities(), vec![], false, )?; let target = if is_requestor { target } else { source }; let our_worker_address = Address { node: our.node.clone(), process: our_worker, }; Response::new() .body(WorkerResponse::Download(Ok(()))) .send()?; Request::new() .expects_response(5) .body(WorkerRequest::Download(DownloadRequest { name: name.to_string(), target: target.clone(), is_requestor, })) .target(&our_worker_address) .send()?; Ok(()) } struct Api; impl Guest for Api { fn start_download( our: WitAddress, source: WitAddress, name: String, target: WitAddress, is_requestor: bool, ) -> Result<(), String> { match start_download(&our, &source, &name, &target, is_requestor) { Ok(result) => Ok(result), Err(e) => Err(format!("{e:?}")), } } } export!(Api); }
Example Usage
Build
# Start fake nodes.
kit f
kit f -o /tmp/kinode-fake-node-2 -p 8081 -f fake2.dev
# Create & build file-transfer.
## The `-a` adds the worker Wasm file to the API so it can be exported properly.
kit n file-transfer -t file-transfer
kit b file-transfer -a file-transfer/pkg/file-transfer-worker.wasm
# Start file-transfer on fake nodes.
kit s file-transfer
kit s file-transfer -p 8081
Usage
# First, put a file into `/tmp/kinode-fake-node-2/vfs/file-transfer:template.os/files/`, e.g.:
echo 'hello world' > /tmp/kinode-fake-node-2/vfs/file-transfer:template.os/files/my_file.txt
# In fake.dev terminal, check if file exists.
list-files:file-transfer:template.os fake2.dev
# In fake.dev terminal, download the file.
download:file-transfer:template.os my_file.txt fake2.dev
# Confirm file was downloaded:
cat /tmp/kinode-fake-node/vfs/file-transfer:template.os/files/my_file.txt
Kino Files (File Transfer + UI)
Warning: This document is known to be out-of-date as of November 14, 2024. Proceed with caution.
This entry will teach you to add a simple UI to the file transfer app, using kit's built-in UI template.
This guide assumes a basic understanding of Kinode process building, some familiarity with kit, requests and responses, and some knowledge of Rust syntax.
It's also strongly recommended that you read and understand the file transfer app before continuing.
Contents
Start
Create a new project with kit, passing the --ui flag:
kit new file-transfer --ui
This will create a new project with a ui directory for the Vite/React UI code, in addition to the file-transfer directory where the usual Rust code will be located.
File Transfer
The file transfer app is a simple app that allows users to upload and download files to and from their node. It's a good example of a simple app that can be built on Kinode.
Existing Features
The file transfer app already has the following features:
- upload files to your node's VFS
- list the files on your node
- search for and list the files on other nodes
- download files from other nodes to yours
- display download progress
You just need to build a UI to take advantage of these capabilities.
UI
kit has a built-in UI template that you can use to build your UI.
The UI template is a simple React app that uses Vite as a build tool.
Our objective is a UI that looks something like this:
Needed Features
Our UI will need to enable all of the above features.
Vite
You will develop your UI on Vite, a fast, opinionated frontend build tool. It's like Webpack, but faster and with less configuration. If you've never used Vite before, check out the docs.
Build it!
To build the UI, run kit build (or just kit b).
This will build the UI and copy the files into the pkg/ui directory, then build file-transfer as usual.
The UI will be served from http://localhost:8080 (or your custom node URL/port) at /file-transfer:file-transfer:template.os.
However, you will need to configure Vite to allow your UI to communicate seamlessly with the file-transfer app on your node.
Configure Vite
You will be configuring your Vite environment in order to enable development on Kinode.
This step is necessary to allow your development UI (which will change often, and rebuild quickly) to communicate with the file-transfer app on your node (which will change rarely, and rebuild slowly).
Example vite.config.ts
import { defineConfig } from 'vite'
import react from '@vitejs/plugin-react'
// BASE_URL is process_name:package_name:publisher_node.
// It represents the URL where the UI will be served from.
// If your node is running on localhost, you will access the UI at http://localhost:3000/process_name:package_name:publisher_node.
import manifest from '../pkg/manifest.json'
import metadata from '../pkg/metadata.json'
const BASE_URL = `${manifest.process_name}:${manifest.package}:${metadata.publisher}`
// This is the proxy URL, it must match the node you are developing against
const PROXY_URL = (process.env.VITE_NODE_URL || 'http://127.0.0.1:8080').replace('localhost', '127.0.0.1');
export default defineConfig({
plugins: [react()],
base: BASE_URL,
build: {
rollupOptions: {
external: ['/our.js']
}
},
server: {
open: true,
proxy: {
// '/our' is an endpoint that simply serves your node's name via GET.
'/our': {
target: PROXY_URL,
changeOrigin: true,
},
// 'our.js' is a js file containing information about your node, which will be used by your UI.
[`${BASE_URL}/our.js`]: {
target: PROXY_URL,
changeOrigin: true,
rewrite: (path) => path.replace(BASE_URL, ''),
},
// This route will match all other HTTP requests to the backend: when your ui makes a request to BASE_URL, it will be proxied to your node.
[`^${BASE_URL}/(?!(@vite/client|src/.*|node_modules/.*|@react-refresh|$))`]: {
target: PROXY_URL,
changeOrigin: true,
},
}
}
});
Example index.html
You only need to change one line in the default index.html file: Add <script type="module" src="/our.js"></script> to the <head>.
<!doctype html>
<html lang="en">
<head>
<meta charset="UTF-8" />
<link rel="icon" type="image/svg+xml" href="/vite.svg" />
<meta name="viewport" content="width=device-width, initial-scale=1.0" />
<title>Vite + React + TS</title>
<!-- Add this line -->
<script src="/our.js"></script>
</head>
<body>
<div id="root"></div>
<script type="module" src="/src/main.tsx"></script>
</body>
</html>
So much for the Vite configuration. Now let's look at the UI code.
Example UI Code
The UI is built on React, a popular frontend framework. If you've never used React before, check out the docs.
Types and Stores
You will use Zustand to manage your state. Zustand is a simple state management library that uses React hooks. If you've never used Zustand before, check out the docs.
ui/src/types/KinoFile.ts
This interface represents a file in your UI. It doesn't need much, because most of the information about the file is stored on your node.
interface KinoFile {
name: string,
size: number,
}
export default KinoFile;
ui/src/store/fileTransferStore.ts
The fileTransferStore is a Zustand store that will manage your state.
import { create } from 'zustand'
import { persist, createJSONStorage } from 'zustand/middleware'
import KinoFile from '../types/KinoFile'
import KinodeEncryptorApi from '@uqbar/client-encryptor-api'
export interface FileTransferStore {
// handleWsMessage is a function that will be called when the websocket receives a message.
handleWsMessage: (message: string) => void
// the list of files in your node's VFS
files: KinoFile[]
setFiles: (files: KinoFile[]) => void
// filesInProgress is a map of file names to their upload progress
filesInProgress: { [key: string]: number }
setFilesInProgress: (filesInProgress: { [key: string]: number }) => void
// the initialized Kinode api which you will communicate with
api: KinodeEncryptorApi | null
setApi: (api: KinodeEncryptorApi) => void
// zustand's generic set function
set: (partial: FileTransferStore | Partial<FileTransferStore>) => void
}
// ProgressMessage is the type of message you will receive from your node's websocket connection. It indicates the progress of a file upload, 0-100.
// If you wanted more complex messages, you could define a union type here.
interface ProgressMessage { name: string, progress: number }
type WsMessage = { kind: string, data: ProgressMessage }
const useFileTransferStore = create<FileTransferStore>()(
persist(
(set, get) => ({
files: [],
filesInProgress: {},
api: null,
setApi: (api) => set({ api }),
setFilesInProgress: (filesInProgress) => set({ filesInProgress }),
setFiles: (files) => set({ files }),
handleWsMessage: (json: string | Blob) => {
// This function will be called when the websocket receives a message.
// Right now you only care about progress messages, but you could add more types of messages here.
const { filesInProgress, setFilesInProgress } = get()
if (typeof json === 'string') {
try {
console.log('WS: GOT MESSAGE', json)
const { kind, data } = JSON.parse(json) as WsMessage;
if (kind === 'progress') {
// If you receive a progress message, update the progress of the file in filesInProgress.
// This will show up in the UI as a percentage.
const { name, progress } = data
const fip = { ...filesInProgress, [name]: progress }
console.log({ fip })
setFilesInProgress(fip)
}
} catch (error) {
console.error("Error parsing WebSocket message", error);
}
} else {
console.log('WS: GOT BLOB', json)
}
},
set,
get,
}),
{
name: 'file_transfer', // unique name
storage: createJSONStorage(() => localStorage), // (optional) by default, 'localStorage' is used. You could use 'sessionStorage' or any other storage.
}
)
)
export default useFileTransferStore
Style
We'll use Tailwind CSS for styling. This is a popular CSS framework that allows you to style your app using only CSS classes. If you've never used Tailwind before, check out the docs!
Installing Tailwind
First, install Tailwind and its dependencies:
# npm:
npm install -D tailwindcss@latest postcss@latest autoprefixer@latest classnames
# yarn:
yarn add -D tailwindcss@latest postcss@latest autoprefixer@latest classnames
Next, create a Tailwind config file:
npx tailwindcss init -p
This will create a tailwind.config.js file in your project's root directory.
Configuring Tailwind
Next, you need to configure Tailwind to purge unused styles in production. This will reduce the size of your CSS bundle.
Open tailwind.config.js and add the following:
module.exports = {
purge: ['./index.html', './src/**/*.{js,jsx,ts,tsx,vue}'],
darkMode: false, // or 'media' or 'class'
theme: {
extend: {},
},
variants: {
extend: {},
},
plugins: [],
}
Importing Tailwind
Finally, you need to import Tailwind in your index.css file:
@tailwind base;
@tailwind components;
@tailwind utilities;
UI Code
ui/src/App.tsx
This is the main UI component. We'll want to show the files on your node, the files on other nodes, and a way to upload files to your node.
import { useEffect, useState } from 'react'
import './App.css'
import MyFiles from './components/MyFiles'
import KinodeEncryptorApi from '@uqbar/client-encryptor-api'
import useFileTransferStore from './store/fileTransferStore';
import SearchFiles from './components/SearchFiles';
// This global declaration allows us to access the name of your node and process in a type-safe way.
// These fields are populated by `/our.js`, which is served by your node, and fetched automatically by index.html.
declare global {
var window: Window & typeof globalThis;
var our: { node: string, process: string };
}
// Don't init the websocket connection more than once.
let inited = false
function App() {
// filesToUpload is a list of files that the user has selected to upload.
const [filesToUpload, setFilesToUpload] = useState<File[]>([])
const { files, setFiles, handleWsMessage, setApi } = useFileTransferStore();
// BASE_URL is the endpoint on which your node is serving the UI.
const BASE_URL = import.meta.env.BASE_URL;
// PROXY_TARGET is the URL where your node is running.
const PROXY_TARGET = `${(import.meta.env.VITE_NODE_URL || "http://localhost:8080")}${BASE_URL}`;
// WEBSOCKET_URL is the URL where your node's websocket is running, e.g. ws://localhost:8080.
const WEBSOCKET_URL = import.meta.env.DEV
? `${PROXY_TARGET.replace('http', 'ws')}`
: undefined;
// Set your node and process names in the global window object.
if (window.our) window.our.process = BASE_URL?.replace("/", "");
// This effect will run once, when the component is mounted.
useEffect(() => {
if (!inited) {
inited = true
// Connect to your node's websocket for this process.
const api = new KinodeEncryptorApi({
uri: WEBSOCKET_URL,
nodeId: window.our.node,
processId: window.our.process,
onMessage: handleWsMessage
});
setApi(api);
}
}, [])
// This function is called when the user selects files to upload.
const onAddFiles = (event: React.ChangeEvent<HTMLInputElement>) => {
if (event.target.files) {
setFilesToUpload(Array.from(event.target.files))
}
}
// This function refreshes the files on your node's VFS.
const refreshFiles = () => {
fetch(`${BASE_URL}/files`)
.then((response) => response.json())
.then((data) => {
try {
setFiles(data.ListFiles)
} catch {
console.log("Failed to parse JSON files", data);
}
})
}
useEffect(() => {
refreshFiles()
}, [])
// When you click the upload button, POST the queued files to your node.
const onUploadFiles = () => {
const formData = new FormData()
filesToUpload.forEach((file) => {
formData.append('files', file)
})
fetch(`${BASE_URL}/files`, {
method: 'POST',
body: formData,
})
.then(() => {
refreshFiles()
})
}
return (
<div className='flex text-white'>
<div className='flex flex-col w-1/4 bg-gray-800 h-screen sidebar'>
<h2 className='text-2xl font-bold px-2 py-1'>Kino Files</h2>
{/*
This is the sidebar.
*/}
<div className='flex flex-col mt-4'>
<h3 className='text-xl font-bold px-2 py-1'>Upload</h3>
<div className='flex flex-col px-2 py-1'>
{/*
This button opens a file selection dialog.
When the user selects files to upload to their node, you stage them here.
*/}
<label htmlFor='files' className='bg-blue-500 hover:bg-blue-700 font-bold py-2 px-4 rounded cursor-pointer text-center'>
Choose Files
<input id='files' type='file' hidden multiple onChange={onAddFiles} />
</label>
{/*
If you have selected files to upload, show them here.
When you click the upload button, you POST the files to the node.
*/}
{filesToUpload.length > 0 && (
<div className='flex flex-col px-2 py-1'>
<div className='flex flex-row justify-between px-2 py-1'>
<span>{filesToUpload.length} files selected</span>
<span>{filesToUpload.reduce((acc, file) => acc + file.size, 0)}</span>
</div>
<button className='bg-blue-500 hover:bg-blue-700 font-bold py-2 px-4 rounded' onClick={onUploadFiles}>
Upload
</button>
</div>
)}
</div>
{/*
Show the files on your node.
This component is defined below.
*/}
<MyFiles node={window.our.node} files={files} />
</div>
</div>
{/*
This is the main content area.
*/}
<div className='flex flex-col w-3/4 bg-gray-900 h-screen content px-2 py-1'>
{/*
Show the files on other nodes.
This component is defined below.
*/}
<SearchFiles />
</div>
</div>
)
}
export default App
ui/src/components/MyFiles.tsx
This is just a list of files.
Each file is rendered by the FileEntry component, which is below.
import FileEntry from './FileEntry';
import KinoFile from '../types/KinoFile';
interface Props {
files: KinoFile[];
node: string;
}
const MyFiles = ({ files, node }: Props) => {
return (
<div className='flex flex-col'>
<h3 className='font-bold text-white px-2 py-1 font-mono'>{node}</h3>
<div className='text-xs flex flex-col'>
{files.length === 0
? <span className='text-white'>No files... yet.</span>
: files.map((file, index) => <FileEntry node={node} key={index} file={file} />)}
</div>
</div>
);
};
export default MyFiles;
ui/src/components/FileEntry.tsx
The FileEntry component renders a single file.
It shows the file name, size, and a button to download the file to your node's VFS.
It requires a node prop, which is the name of the node where the file is located.
Also, if the file is downloading, it shows the download progress.
Once finished, the file will be saved to your node's VFS, and you will see "Saved".
import { useEffect, useState } from "react";
import KinoFile from "../types/KinoFile";
import useFileTransferStore from "../store/fileTransferStore";
import classNames from "classnames";
interface Props {
file: KinoFile
node: string
}
function FileEntry({ file, node }: Props) {
const { files: ourFiles, filesInProgress, api } = useFileTransferStore();
const [actualFilename, setActualFilename] = useState<string>('')
const [actualFileSize, setActualFileSize] = useState<string>('')
const [isOurFile, setIsOurFile] = useState<boolean>(false)
const showDownload = node !== window.our.node;
useEffect(() => {
// To display the filename ergonomically,
// you strip the `file-transfer:file-transfer:template.os/files/`
// prefix from the file name.
const filename = file.name.split('/files/').pop() || '';
setActualFilename(filename);
}, [file.name])
useEffect(() => {
const fileSize = file.size > 1000000000000
? `${(file.size / 1000000000000).toFixed(2)} TB`
: file.size > 1000000000
? `${(file.size / 1000000000).toFixed(2)} GB`
: file.size > 1000000
? `${(file.size / 1000000).toFixed(2)} MB`
: `${(file.size / 1000).toFixed(2)} KB`;
setActualFileSize(fileSize);
}, [file.size])
const onDownload = () => {
if (!file.name) return alert('No file name');
if (!api) return alert('No api');
api.send({
data: {
Download: {
name: actualFilename,
target: `${node}@${window.our.process}`
}
}
})
}
useEffect(() => {
if (!ourFiles) return;
const foundFile = ourFiles.find((f) => f.name.match(file.name));
if (foundFile) {
setIsOurFile(true);
}
}, [ourFiles])
const downloadInfo = Object.entries(filesInProgress).find(([key, _]) => file.name.match(key));
const downloadInProgress = (downloadInfo?.[1] || 100) < 100;
const downloadComplete = (downloadInfo?.[1] || 0) === 100;
return (
<div className='flex flex-row px-2 py-1 justify-between place-items-center'>
<span className='break-all grow mr-1'>{actualFilename}</span>
<span>{actualFileSize}</span>
{showDownload && <button
disabled={isOurFile || downloadInProgress || downloadComplete}
className={classNames('font-bold py-2 px-4 rounded ml-2', {
isOurFile, downloadInProgress, downloadComplete,
'bg-gray-800': isOurFile || downloadInProgress || downloadComplete,
'bg-blue-500 hover:bg-blue-700': !isOurFile && !downloadInProgress && !downloadComplete, })}
onClick={onDownload}
>
{isOurFile
? 'Saved'
: downloadComplete
? 'Saved'
: downloadInProgress
? <span>{downloadInfo?.[1]}%</span>
:'Save to node'}
</button>}
</div>
);
}
export default FileEntry;
ui/src/components/SearchFiles.tsx
This component shows the files on other nodes. It allows you to search for files on other nodes, and download them to your node.
import { useState } from 'react';
import KinoFile from '../types/KinoFile';
import FileEntry from './FileEntry';
const SearchFiles = function() {
const [searchTerm, setSearchTerm] = useState('');
const [foundFiles, setFoundFiles] = useState<KinoFile[]>([]);
const handleSearch = () => {
if (!searchTerm) return alert('Please enter a node name.');
if (!searchTerm.match(/^[a-z0-9-]+\.os$/)) return alert('Invalid node name.');
try {
fetch(`${import.meta.env.BASE_URL}/files?node=${searchTerm}`, {
method: 'GET',
headers: {
'Content-Type': 'application/json',
},
}).then((response) => response.json())
.then((data) => {
try {
setFoundFiles(data.ListFiles)
} catch {
console.log("Failed to parse JSON files", data);
}
});
} catch (error) {
console.error('Error:', error);
}
};
return (
<div className='flex flex-col px-2 py-1'>
<h2 className='text-xl mb-2 font-bold'>Search files on the network</h2>
<div className='flex place-items-center mb-2'>
<span className='mr-2'>Node:</span>
<input
className='bg-gray-800 appearance-none border-2 border-gray-800 rounded w-full py-2 px-4 text-white leading-tight focus:outline-none focus:bg-gray-800 focus:border-blue-500'
type="text"
value={searchTerm}
placeholder='somenode.os'
onChange={(e) => setSearchTerm(e.target.value)}
/>
<button className='bg-blue-500 hover:bg-blue-700 text-white font-bold py-2 px-4 rounded' onClick={handleSearch}>Search</button>
</div>
{foundFiles && foundFiles.length === 0 && <span className='text-white'>No files found.</span>}
{foundFiles && foundFiles.length > 0 && <div className='flex flex-col px-2 py-1'>
<h2><span className='text-xl font-bold font-mono'>{searchTerm}:</span> <span className='text-xs'>{foundFiles.length} files</span></h2>
{foundFiles.map((file) => (
<FileEntry node={searchTerm} key={file.name} file={file} />
))}
</div>}
</div>
);
};
export default SearchFiles;
Build it!
Now that you've written your UI code, you can build it.
- Run
kit build(or justkit b) to build the UI andfile-transferprocess. - Run
kit start-package -p 8080(or justkit s) to install the package to your node running on port 8080.
In the future, you can run both of these steps in a single command, with kit bs.
The UI will be served from http://localhost:8080/file-transfer:file-transfer:template.os.
Next Steps
Now that you've built a simple UI, you can try building your own app! Check out the APIs to see what's possible.
GitHub Repo
You can find the full code for this example here.
Scripts
Scripts are just processes. They are written almost exactly like applications, with a few key differences:
- Scripts always terminate, while apps may run indefinitely.
- When writing a script, you cannot control the
OnExitbehavior like you can with an application - Scripts are called with an initial set of arguments (passed in via the terminal)
- Scripts are registered in the
scripts.jsonfile instead of themanifest.jsonfile
Writing a Script
Consider the simplest possible script: echo (found in the runtime here), which takes in an argument and prints it out again:
#![allow(unused)] fn main() { use kinode_process_lib::{script, Address}; wit_bindgen::generate!({ path: "target/wit", world: "process-v0", }); script!(init); fn init(_our: Address, args: String) -> String { args } }
From writing applications, this should look very familiar - the imports, wit_bindgen::generate!, etc.
Note the use of a macro script! instead of the usual call_init!.
This macro handles the boilerplate associated with script processes:
- Creating an init function, just like all processes
- Awaiting an initial request from the terminal, which provides the script with its arguments
- Parsing the body of that request into a string
- Returning a string to be either printed or sent as a response, depending on how the script was called
If you want to create an advanced script, consider looking at the source code of the script! macro in process_lib.
Publishing a Script
Unlike processes associated with a long-running application, which will be put into the manifest.json, scripts must be registered in a separate scripts.json file.
While very similar, there are a few important differences; here's an example that could live in your packages pkg/scripts.json file:
{
"echo.wasm": {
"root": false,
"public": false,
"request_networking": false,
"request_capabilities": [],
"grant_capabilities": [],
"wit_version": 0
},
}
This scripts.json file corresponds to a package which publishes a single script, echo, which doesn't request root capabilities, or any capabilities for that matter.
The keys of this object are the process paths inside of the pkg/ folder.
The name of the script will be the file path, with .wasm taken off.
The object that echo.wasm points to is very similar to manifest.json, with a few things removed, and root has been added:
rootmeans that all the capabilities held byterminal:terminal:sysare passed to this script (this is powerful, and rarely needed)public: same asmanifest.json- corresponds to whether or not other processes can messageecho.wasmwithout the messsaging caprequest_networking: same asmanifest.json- corresponds to whether or not this script will need to send messaages over the networkrequest_capabilities: same asmanifest.json- a list of capabilities that will be granted to this script on startup (NOTE if you haveroot, there is no reason to populaterequest_capabilitiesas well)grant_capabilities: same asmanifest.json- a list of messaging caps toecho.wasmto be given to other processes on startup As long as you have ascripts.jsonfile, your scripts will be callable from the terminal when someone else downloads your package.
Calling a Script
After having called kit bs, simply type my-script:my-package:publisher <ARGS> in the terminal.
For instance, the echo script is published as part of terminal:sys, so you can call
echo:terminal:sys Hello World!
Aliasing a Script
If you are going to be calling your script very often, you can alias it to something shorter like so:
alias echo echo:terminal:sys
so now you can call echo like echo Hello World!.
To remove the alias, simply run:
alias echo
Reading Data from ETH
For the purposes of this cookbook entry, all reads will be done from Ethereum Mainnet, but the same methods can easily be used on other networks by changing the chain_id parameter.
Using the provider system starts in a process by importing the eth library from kinode_process_lib:
#![allow(unused)] fn main() { use kinode_process_lib::eth; }
Then, create a new Provider object with the desired chain ID and timeout:
#![allow(unused)] fn main() { let provider = eth::Provider::new(chain_id, 30); }
The timeout set here will apply to all requests sent through the provider. If a request takes longer than the timeout, the request will fail with a timeout error. Generally, ETH calls can take longer than other requests in Kinode, because the call must be sent to an external RPC that may or may not be fast. Note also that an RPC endpoint will generally take longer to respond to larger calls. If you need to adjust the timeout or chain ID, simply create another provider object with the new desired parameters.
Calling various functions on the Provider allows the process to execute RPC calls like get_balance, get_logs, and send_raw_transaction.
Here's an example of reading the current block number from Ethereum:
#![allow(unused)] fn main() { let provider = eth::Provider::new(1, 5); match provider.get_block_number() { Ok(block_number) => { println!("latest block number: {block_number}"); } Err(e) => { println!("failed to get block number: {e:?}"); } } }
Here's an example of using a Filter to first fetch logs, then create a subscription to a contract's events:
#![allow(unused)] fn main() { const EVENTS: [&str; 3] = [ "AppRegistered(uint256,string,bytes,string,bytes32)", "AppMetadataUpdated(uint256,string,bytes32)", "Transfer(address,address,uint256)", ]; let provider = eth::Provider::new(1, 30); let filter = eth::Filter::new() .address(eth::Address::from_str("0x18c39eB547A0060C6034f8bEaFB947D1C16eADF1").unwrap()) .from_block(0) .to_block(eth::BlockNumberOrTag::Latest) .events(EVENTS); match eth_provider.get_logs(&filter) { Ok(logs) => { // do something with the logs, perhaps save them somewhere? }, Err(_) => { println!("failed to fetch logs!"); } } match eth_provider.subscribe(1, filter) { Ok(()) => { println!("subscribed to events!"); }, Err(e) => { println!("failed to subscribe to events! we should try again.."); } } }
There are a few important things to note when subscribing to contract events and fetching event logs:
-
Subscription updates will come in the form of
Requests frometh:distro:sys. The body of these requests will be JSON that deserializes toResult<eth::EthSub, eth::EthSubError>. See the ETH API documentation for more information on these types. -
The
get_logscall is usually limited by RPC providers to a certain amount of data. For example, Alchemy limits a request to either 10,000 total log items OR a 2,000-block range. For this reason, your app should be prepared to break calls up into multiple chunks. -
A good strategy for efficiently fetching logs is to save them in a data structure inside your app, and then only fetch logs that are newer than the last log you saved.
-
If a subscription fails, it makes sense to try resubscribing, but keep in mind that events might occur between the failure and the resubscribe. A good strategy is to fetch logs for this time period.
For a full example of an app that uses the ETH Provider in a critical use-case, check out the kns-indexer in the Kinode repo.
Writing Data to ETH
For this cookbook entry, you'll create and deploy a simple Counter contract onto a fake local chain, and write a kinode app to interact with it.
Using kit, create a new project with the echo template:
kit new counter --template echo
cd counter
Now you can create a contracts directory within counter using forge init contracts.
If foundry is not installed, it can be installed with:
curl -L https://foundry.paradigm.xyz | bash
You can see the simple Counter.sol contract in contracts/src/Counter.sol:
// SPDX-License-Identifier: UNLICENSED
pragma solidity ^0.8.13;
contract Counter {
uint256 public number;
function setNumber(uint256 newNumber) public {
number = newNumber;
}
function increment() public {
number++;
}
}
You can write a simple script to deploy it at a predictable address, create the file scripts/Deploy.s.sol:
// SPDX-License-Identifier: UNLICENSED
pragma solidity ^0.8.13;
import {Script, console, VmSafe} from "forge-std/Script.sol";
import {Counter} from "../src/Counter.sol";
contract DeployScript is Script {
function setUp() public {}
function run() public {
VmSafe.Wallet memory wallet = vm.createWallet(
0xac0974bec39a17e36ba4a6b4d238ff944bacb478cbed5efcae784d7bf4f2ff80
);
vm.startBroadcast(wallet.privateKey);
Counter counter = new Counter();
console.log("Counter deployed at address: ", address(counter));
vm.stopBroadcast();
}
}
Now boot a fakechain, either with kit f which boots one at port 8545 in the background, or with kit c.
Then you can run:
forge script --rpc-url http://localhost:8545 script/Deploy.s.sol --broadcast
You'll see a printout that looks something like this:
== Logs ==
Counter deployed at address: 0x0DCd1Bf9A1b36cE34237eEaFef220932846BCD82
Great! Now you'll write the kinode app to interact with it.
You're going to use some functions from the eth library in kinode_process_lib:
#![allow(unused)] fn main() { use kinode_process_lib::eth; }
Also you'll need to request the capability to message eth:distro:sys, so you can add it to the request_capabilities field in pkg/manifest.json.
Next, you'll need some sort of ABI in order to interact with the contracts.
The crate alloy-sol-types gives us a solidity macro to either define contracts from JSON, or directly in the rust code.
You'll add it to counter/Cargo.toml:
alloy-sol-types = "0.7.6"
Now, importing the following types from the crate:
#![allow(unused)] fn main() { use alloy_sol_types::{sol, SolCall, SolValue}; }
You can do the following:
#![allow(unused)] fn main() { sol! { contract Counter { uint256 public number; function setNumber(uint256 newNumber) public { number = newNumber; } function increment() public { number++; } } } }
Pretty cool, you can now do things like define a setNumber() call just like this:
#![allow(unused)] fn main() { let contract_call = setNumberCall { newNumber: U256::from(58)}; }
Start with a simple setup to read the current count, and print it out!
#![allow(unused)] fn main() { use kinode_process_lib::{await_message, call_init, eth::{Address as EthAddress, Provider, TransactionInput, TransactionRequest, U256}, println, Address, Response}; use alloy_sol_types::{sol, SolCall, SolValue}; use std::str::FromStr; wit_bindgen::generate!({ path: "target/wit", world: "process-v0", }); sol! { contract Counter { uint256 public number; function setNumber(uint256 newNumber) public { number = newNumber; } function increment() public { number++; } } } pub const COUNTER_ADDRESS: &str = "0x0DCd1Bf9A1b36cE34237eEaFef220932846BCD82"; fn read(provider: &Provider) -> anyhow::Result<U256> { let counter_address = EthAddress::from_str(COUNTER_ADDRESS).unwrap(); let count = Counter::numberCall {}.abi_encode(); let tx = TransactionRequest::default() .to(counter_address) .input(count.into()); let x = provider.call(tx, None); match x { Ok(b) => { let number = U256::abi_decode(&b, false)?; println!("current count: {:?}", number.to::<u64>()); Ok(number) } Err(e) => { println!("error getting current count: {:?}", e); Err(anyhow::anyhow!("error getting current count: {:?}", e)) } } } call_init!(init); fn init(our: Address) { println!("begin"); let provider = Provider::new(31337, 5); let _count = read(&provider); loop { match handle_message(&our, &provider) { Ok(()) => {} Err(e) => { println!("error: {:?}", e); } }; } } }
Now add the 2 writes that are possible: increment() and setNumber(newNumber). To do this, you'll need to define a wallet, and import a few new crates:
alloy-primitives = "0.7.6"
alloy-rlp = "0.3.5"
alloy = { version = "0.1.2", features = [
"network",
"signers",
"signer-local",
"consensus",
"rpc-types"
]}
You'll also define a simple enum so you can call the program with each of the 3 actions:
#![allow(unused)] fn main() { #[derive(Debug, Deserialize, Serialize)] pub enum CounterAction { Increment, Read, SetNumber(u64), } }
When creating a wallet, you can use one of the funded addresses on the anvil fakechain, like so:
#![allow(unused)] fn main() { use alloy::{ consensus::{SignableTransaction, TxEip1559, TxEnvelope}, network::{eip2718::Encodable2718, TxSignerSync}, primitives::TxKind, rpc::types::eth::TransactionRequest, signers::local::PrivateKeySigner, }; use alloy_rlp::Encodable; use alloy_sol_types::{sol, SolCall, SolValue}; use kinode_process_lib::{ await_message, call_init, eth::{Address as EthAddress, Provider, U256}, println, Address, Response, }; use serde::{Deserialize, Serialize}; use std::str::FromStr; let wallet = PrivateKeySigner::from_str("0xac0974bec39a17e36ba4a6b4d238ff944bacb478cbed5efcae784d7bf4f2ff80") .unwrap(); }
First, branching on the enum type Increment, call the increment() function with no arguments:
#![allow(unused)] fn main() { CounterAction::Increment => { let increment = Counter::incrementCall {}.abi_encode(); let nonce = provider .get_transaction_count(wallet.address(), None) .unwrap() .to::<u64>(); let mut tx = TxEip1559 { chain_id: 31337, nonce: nonce, to: TxKind::Call(EthAddress::from_str(COUNTER_ADDRESS).unwrap()), gas_limit: 15000000, max_fee_per_gas: 10000000000, max_priority_fee_per_gas: 300000000, input: increment.into(), ..Default::default() }; let sig = wallet.sign_transaction_sync(&mut tx)?; let signed = TxEnvelope::from(tx.into_signed(sig)); let mut buf = vec![]; signed.encode_2718(&mut buf); let tx_hash = provider.send_raw_transaction(buf.into()); println!("tx_hash: {:?}", tx_hash); } }
Note how you can do provider.get_transaction_count() to get the current nonce of the account!
Next, do the same for setNumber!
#![allow(unused)] fn main() { CounterAction::SetNumber(n) => { let set_number = Counter::setNumberCall { newNumber: U256::from(n), } .abi_encode(); let nonce = provider .get_transaction_count(wallet.address(), None) .unwrap() .to::<u64>(); let mut tx = TxEip1559 { chain_id: 31337, nonce: nonce, to: TxKind::Call(EthAddress::from_str(COUNTER_ADDRESS).unwrap()), gas_limit: 15000000, max_fee_per_gas: 10000000000, max_priority_fee_per_gas: 300000000, input: set_number.into(), ..Default::default() }; let sig = wallet.sign_transaction_sync(&mut tx)?; let signed = TxEnvelope::from(tx.into_signed(sig)); let mut buf = vec![]; signed.encode(&mut buf); let tx_hash = provider.send_raw_transaction(buf.into()); println!("tx_hash: {:?}", tx_hash); } }
Nice!
Putting it all together, you can build and start the package on a fake node (kit f if you don't have one running), kit bs.
fake.dev > m our@counter:counter:template.os '{"SetNumber": 55}'
counter:template.os: tx_hash: Ok(0x5dba574f2a9a2c095cee960868433e23c64b685966fba57568c4d6a0fd99ef6c)
fake.dev > m our@counter:counter:template.os "Read"
counter:template.os: current count: 55
fake.dev > m our@counter:counter:template.os "Increment"
counter:template.os: tx_hash: Ok(0xc38ee230c2605c294a37794244334c0d20a5b5e090704b34f4a7998021418d7b)
fake.dev > m our@counter:counter:template.os "Read"
counter:template.os: current count: 56
You can find these steps outlined by commit in the counter example repo!
Creating and Using Capabilities
Previous examples have shown how to acquire capabilities in a manifest file. Here, we'll show how a package that does not come "built in" to Kinode can create its own capabilities and how other processes can use them.
Recall that capabilities are tokens of authority that processes can use to authorize behaviors and are managed by the kernel. In userspace, there are two common patterns for using capabilities: requesting/granting them in the package manifest, or attaching them to a message. The first pattern is more common, and generally matches the intuition of the program's end-user: when they install an app, they are presented with a list of actions that the app will be able to perform, such as messaging the "eth" process to read blockchain data or access the files of a specific other package.
There is no need to register capabilities that can be granted. When another process requests them, the package manager / app store, which has kernel-messaging authority, can spawn them if a user approves. This allows capabilities to be granted before they are needed, even if the relevant package is not installed yet.
To require that a capability exist in order to fulfill a message, one can check for its existence in the capabilities field of the message.
// each request requires one of read-name-only, read, add, or remove
if let Some(capabilities) = capabilities {
let required_capability = Capability::new(
&state.our,
serde_json::to_string(&match request {
contacts::Request::GetNames => contacts::Capability::ReadNameOnly,
contacts::Request::GetAllContacts | contacts::Request::GetContact(_) => {
contacts::Capability::Read
}
contacts::Request::AddContact(_) | contacts::Request::AddField(_) => {
contacts::Capability::Add
}
contacts::Request::RemoveContact(_) | contacts::Request::RemoveField(_) => {
contacts::Capability::Remove
}
})
.unwrap(),
);
if !capabilities.contains(&required_capability) {
return (
contacts::Response::Err("Missing capability".to_string()),
None,
);
}
}This code is run on each incoming request to the contacts process.
Depending on the kind of request, the code generates one of four different required capabilities and checks whether the necessary one is present in the capabilities field of the message.
If not, the process responds with an error message.
This example uses a similar API as the contacts app included in the default Kinode distribution: for a guide to use the actual contacts system primitive, see Managing Contacts.
Note that the format of the capability is presented in a WIT API file alongside the request and response types. This allows other processes to easily produce the correct capability when requesting it.
Now, take a look at the manifest for the contacts-test process.
{
"process_name": "contacts-test",
"process_wasm_path": "/contacts_test.wasm",
"on_exit": "None",
"request_networking": false,
"request_capabilities": [
"contacts:capabilities-test:doria.kino",
{
"process": "contacts:capabilities-test:doria.kino",
"params": "ReadNameOnly"
},
{
"process": "contacts:capabilities-test:doria.kino",
"params": "Read"
},
{
"process": "contacts:capabilities-test:doria.kino",
"params": "Add"
},
{
"process": "contacts:capabilities-test:doria.kino",
"params": "Remove"
}
],
"grant_capabilities": [
"contacts:capabilities-test:doria.kino"
],
"public": false
}
This manifest requests all four capabilities from the contacts process.
Naturally, the correct package name and publisher must be used here.
The "params" field must match the JSON serialization of the capability type that lives in the WIT API:
enum capability {
read-name-only,
read,
add,
remove,
}Let's see contacts-test using these capabilities in action.
let contacts_process =
Address::from((our.node(), "contacts", "capabilities-test", "doria.kino"));
// All of these capabilities were requested in the manifest,
// so we can create them here and attach them to our requests.
// If they were not in the manifest or otherwise acquired,
// we could still create the objects, but they would not be
// attached to our requests and therefore the requests would fail.
let read_names_cap = Capability::new(
&contacts_process,
serde_json::to_string(&contacts::Capability::ReadNameOnly).unwrap(),
);
let read_cap = Capability::new(
&contacts_process,
serde_json::to_string(&contacts::Capability::Read).unwrap(),
);
let add_cap = Capability::new(
&contacts_process,
serde_json::to_string(&contacts::Capability::Add).unwrap(),
);
let remove_cap = Capability::new(
&contacts_process,
serde_json::to_string(&contacts::Capability::Remove).unwrap(),
);
kiprintln!("requesting all names from contacts");
let response = Request::to(&contacts_process)
.body(serde_json::to_vec(&contacts::Request::GetNames).unwrap())
.capabilities(vec![read_names_cap])
.send_and_await_response(5)
.unwrap()
.unwrap();
kiprintln!(
"response: {:?}",
serde_json::from_slice::<contacts::Response>(&response.body()).unwrap()
);
kiprintln!("requesting all names from contacts (without capability attached!)");
let response = Request::to(&contacts_process)
.body(serde_json::to_vec(&contacts::Request::GetNames).unwrap())
// no cap
.send_and_await_response(5)
.unwrap()
.unwrap();
kiprintln!(
"response: {:?}",
serde_json::from_slice::<contacts::Response>(&response.body()).unwrap()
);
kiprintln!("adding contact to contacts");
let response = Request::to(&contacts_process)
.body(
serde_json::to_vec(&contacts::Request::AddContact(
"mothu-et-doria.os".to_string(),
))
.unwrap(),
)
.capabilities(vec![add_cap])
.send_and_await_response(5)
.unwrap()
.unwrap();
kiprintln!(
"response: {:?}",
serde_json::from_slice::<contacts::Response>(&response.body()).unwrap()
);
kiprintln!("reading all contacts from contacts");
let response = Request::to(&contacts_process)
.body(serde_json::to_vec(&contacts::Request::GetAllContacts).unwrap())
.capabilities(vec![read_cap])
.send_and_await_response(5)
.unwrap()
.unwrap();
kiprintln!(
"response: {:?}",
serde_json::from_slice::<contacts::Response>(&response.body()).unwrap()
);
kiprintln!("removing contact from contacts");
let response = Request::to(&contacts_process)
.body(
serde_json::to_vec(&contacts::Request::RemoveContact(
"mothu-et-doria.os".to_string(),
))
.unwrap(),
)
.capabilities(vec![remove_cap])
.send_and_await_response(5)
.unwrap()
.unwrap();
kiprintln!(
"response: {:?}",
serde_json::from_slice::<contacts::Response>(&response.body()).unwrap()
);
When building each request (except for the one that specifically does not attach a capability, and fails as a result), a capability is attached in the request's builder pattern. Because the capabilities were requested in the manifest, they can be created here and used. If a capability did not exist in the manifest, and was not otherwise acquired during runtime, the capability would not show up for the message receiver, because the kernel validates each capability attached to a message and filters out invalid ones.
Go ahead and use kit to install this package, available here, and see how contacts-test uses capabilities to interact with contacts.
Managing Contacts
Like iOS and Android, Kinode OS includes a handy contacts system primitive, called contacts:contacts:sys.
Using it is optional, but as a peer-to-peer application developer, importing existing contacts is a great way to bootstrap your protocol.
Given the proper capabilities, an app can get the list of existing contacts, get information about a specific contact or all contacts, add new contacts, edit information about contacts, and remove contacts.
Each contact is a valid node identity that's been registered in kimap. Each contact has a map of fields which are labeled by a string key and contain a JSON value.
Here is the full WIT API for contacts:contacts:sys:
interface contacts {
enum capability {
read-name-only,
read,
add,
remove,
}
variant request {
get-names, // requires read-names-only
get-all-contacts, // requires read
get-contact(string), // requires read
add-contact(string), // requires add
// tuple<node, field, value>
add-field(tuple<string, string, string>), // requires add
remove-contact(string), // requires remove
// tuple<node, field>
remove-field(tuple<string, string>), // requires remove
}
variant response {
get-names(list<string>),
get-all-contacts, // JSON all-contacts dict in blob
get-contact, // JSON contact dict in blob
add-contact,
add-field,
remove-contact,
remove-field,
err(string), // any failed request will receive this response
}
}
world contacts-sys-v0 {
import contacts;
include process-v0;
}
As described in the comments, each request requires a specific capability.
Acquiring these capabilities is as simple as including them along with the messaging capability for contacts:contacts:sys in the manifest for your package, like so:
"request_capabilities": [
"contacts:contacts:sys",
{
"process": "contacts:contacts:sys",
"params": "ReadNameOnly"
},
{
"process": "contacts:contacts:sys",
"params": "Read"
},
{
"process": "contacts:contacts:sys",
"params": "Add"
},
{
"process": "contacts:contacts:sys",
"params": "Remove"
}
],
Only request capabilities that your package actually needs.
Users may reject installing an app that requests add or remove that they would otherwise feel comfortable allowing to read from contacts.
ReadNameOnly is a good capability to request if the main purpose of using contacts:contacts:sys is simply to grab a list of node identities that the user might want to see content in your protocol from or play a game with.
To use the contacts primitive to get a list of existing contacts, follow these steps:
-
Download or copy the WIT API file into your package
/apifolder -
Generate your WIT bindings to include this API (note that you can compose this with additional APIs if desired)
#![allow(unused)] fn main() { wit_bindgen::generate!({ path: "target/wit", world: "contacts-sys-v0", generate_unused_types: true, additional_derives: [PartialEq, serde::Deserialize, serde::Serialize], }); }
- Request the proper capability in your
manifest.json
"request_capabilities": [
"contacts:contacts:sys",
{
"process": "contacts:contacts:sys",
"params": "ReadNameOnly"
}
],
- In your process, create the capability and use it to make a request
#![allow(unused)] fn main() { use crate::kinode::process::contacts; use kinode_process_lib::{kiprintln, Address, Capability, Request}; let contacts_process = Address::from((our.node(), "contacts", "contacts", "sys")); let read_names_cap = Capability::new( &contacts_process, serde_json::to_string(&contacts::Capability::ReadNameOnly).unwrap(), ); let response = Request::to(&contacts_process) .body(serde_json::to_vec(&contacts::Request::GetNames).unwrap()) .capabilities(vec![read_names_cap]) .send_and_await_response(5) .unwrap() .unwrap(); // the response will be returned as a list of node identities, represented as strings if let Ok(contacts::Response::GetNames(names)) = serde_json::from_slice(&response.body()) { kiprintln!("contacts: {:?}", names); } }
ZK proofs with SP1
Warning: This document is known to be out-of-date as of November 14, 2024. Proceed with caution.
Zero-knowledge proofs are an exciting new tool for decentralize applications. Thanks to SP1, you can prove a Rust program with an extremely easy to use open-source library. There are a number of other ZK proving systems both in production and under development, which can also be used inside the Kinode environment, but this tutorial will focus on SP1.
Start
In a terminal window, start a fake node to use for development of this app.
kit boot-fake-node
In another terminal, create a new app using kit. Use the fibonacci template, which can then be modified to calculate fibonacci numbers in a provably correct way.
kit new my-zk-app -t fibonacci
cd my-zk-app
kit bs
Take note of the basic fibonacci program in the template. The program presents a request/response pattern where a requester asks for the nth fibonacci number, and the process calculates and returns it. This can be seen in action by running the following command in the fake node's terminal:
m our@my-zk-app:my-zk-app:template.os -a 5 '{"Number": 10}'
(Change the package name to whatever you named your app + the publisher node as assigned in metadata.json.)
You should see a print from the process that looks like this, and a returned JSON response that the terminal prints:
my-zk-app: fibonacci(10) = 55; 375ns
{"Number":55}
Cross-network computation
From the template, you have a program that can be used across the Kinode network to perform a certain computation. If the template app here has the correct capabilities, other nodes will be able to message it and receive a response. This can be seen in action by booting another fake node (while keeping the first one open) and sending the fibonacci program a message:
# need to set a custom name and port so as not to overlap with first node
kit boot-fake-node -p 8081 --fake-node-name fake2.os
# wait for the node to boot
m fake.os@my-zk-app:my-zk-app:template.os -a 5 '{"Number": 10}'
(Replace the target node ID with the first fake node, which by default is fake.os)
You should see {"Number":55} in the terminal of fake2.os!
This reveals a fascinating possibility: with Kinode, one can build p2p services accessible to any node on the network.
However, the current implementation of the fibonacci program is not provably correct.
The node running the program could make up a number -- without doing the work locally, there's no way to verify the result.
ZK proofs can solve this problem.
Introducing the proof
To add ZK proofs to this simple fibonacci program, you can use the SP1 library to write a program in Rust, then produce proofs against it.
First, add the SP1 dependency to the Cargo.toml file for my-zk-app:
[dependencies]
...
sp1-core = { git = "https://github.com/succinctlabs/sp1.git" }
...
Now follow the SP1 install steps to get the tooling for constructing a provable program. After installing you should be able to run
cargo prove new fibonacci
and navigate to a project, which conveniently contains a fibonacci function example.
Modify it slightly to match what our fibonacci program does.
You can more or less copy-and-paste the fibonacci function from your Kinode app to the program/src/main.rs file in the SP1 project.
It'll look like this:
#![no_main] sp1_zkvm::entrypoint!(main); pub fn main() { let n = sp1_zkvm::io::read::<u32>(); if n == 0 { sp1_zkvm::io::write(&0); return; } let mut a: u128 = 0; let mut b: u128 = 1; let mut sum: u128; for _ in 1..n { sum = a + b; a = b; b = sum; } sp1_zkvm::io::write(&b); }
Now, use SP1's prove tool to build the ELF that will actually be executed when the process get a fibonacci request.
Run this inside the program dir of the SP1 project you created:
cargo prove build
Next, take the generated ELF file from program/elf/riscv32im-succinct-zkvm-elf and copy it into the pkg dir of your Kinode app.
Go back to your Kinode app code and include this file as bytes so the process can execute it in the SP1 zkVM:
#![allow(unused)] fn main() { const FIB_ELF: &[u8] = include_bytes!("../../pkg/riscv32im-succinct-zkvm-elf"); }
Building the app
Now, this app can use this circuit to not only calculate fibonacci numbers, but include a proof that the calculation was performed correctly! The subsequent proof can be serialized and shared across the network with the result. Take a moment to imagine the possibilities, then take a look at the full code example below:
Some of the code from the original fibonacci program is omitted for clarity, and functionality for verifying proofs our program receives from others has been added.
#![allow(unused)] fn main() { use kinode_process_lib::{println, *}; use serde::{Deserialize, Serialize}; use sp1_core::{utils::BabyBearBlake3, SP1ProofWithIO, SP1Prover, SP1Stdin, SP1Verifier}; /// our circuit! const FIB_ELF: &[u8] = include_bytes!("../../pkg/riscv32im-succinct-zkvm-elf"); wit_bindgen::generate!({ path: "wit", world: "process", }); #[derive(Debug, Serialize, Deserialize)] enum FibonacciRequest { /// Send this locally to ask a peer for a proof ProveIt { target: NodeId, n: u32 }, /// Send this to a peer's fibonacci program Number(u32), } #[derive(Debug, Serialize, Deserialize)] enum FibonacciResponse { /// What we return to the local request Proven(u128), /// What we get from a remote peer Proof, // bytes in message blob } /// PROVE the nth Fibonacci number /// since we are using u128, the maximum number /// we can calculate is the 186th Fibonacci number /// return the serialized proof fn fibonacci_proof(n: u32) -> Vec<u8> { let mut stdin = SP1Stdin::new(); stdin.write(&n); let proof = SP1Prover::prove(FIB_ELF, stdin).expect("proving failed"); println!("succesfully generated and verified proof for fib({n})!"); serde_json::to_vec(&proof).unwrap() } fn handle_message(our: &Address) -> anyhow::Result<()> { let message = await_message()?; // we only handle requests directly -- responses are awaited in place. // you can change this by using send() instead of send_and_await_response() // in order to make this program more fluid and less blocking. match serde_json::from_slice(message.body())? { FibonacciRequest::ProveIt { target, n } => { // we only accept this from our local node if message.source().node() != our.node() { return Err(anyhow::anyhow!("got a request from a non-local node!")); } // ask the target to do it for us let res = Request::to(Address::new( target, (our.process(), our.package(), our.publisher()), )) .body(serde_json::to_vec(&FibonacciRequest::Number(n))?) .send_and_await_response(30)??; let Ok(FibonacciResponse::Proof) = serde_json::from_slice(res.body()) else { return Err(anyhow::anyhow!("got a bad response!")); }; let proof = res .blob() .ok_or_else(|| anyhow::anyhow!("no proof in response"))? .bytes; // verify the proof let mut proof: SP1ProofWithIO<BabyBearBlake3> = serde_json::from_slice(&proof)?; SP1Verifier::verify(FIB_ELF, &proof).map_err(|e| anyhow::anyhow!("{e:?}"))?; // read result from proof let output = proof.stdout.read::<u128>(); // send response containing number Response::new() .body(serde_json::to_vec(&FibonacciResponse::Proven(output))?) .send()?; } FibonacciRequest::Number(n) => { // handle a remote request to prove a number let proof = fibonacci_proof(n); // send the proof back to the requester Response::new() .body(serde_json::to_vec(&FibonacciResponse::Proof)?) .blob_bytes(proof) .send()?; } } Ok(()) } call_init!(init); fn init(our: Address) { println!("fibonacci: begin"); loop { match handle_message(&our) { Ok(()) => {} Err(e) => { println!("fibonacci: error: {:?}", e); } }; } } }
Test it out
Install this app on two nodes -- they can be the fake kit nodes from before, or real ones on the network.
Next, send a message from one to the other, asking it to generate a fibonacci proof!
m our@my-zk-app:my-zk-app:template.os -a 30 '{"ProveIt": {"target": "fake.os", "n": 10}}'
As usual, set the process ID to what you used, and set the target JSON value to the other node's name.
Try a few different numbers -- see if you can generate a timeout (it's set at 30 seconds now, both in the terminal command and inside the app code).
If so, the power of this proof system is demonstrated: a user with little compute can ask a peer to do some work for them and quickly verify it!
In just over 100 lines of code, you have written a program that can create, share across the network, and verify ZK proofs. Use this as a blueprint for similar programs to get started using ZK proofs in a brand new p2p environment!
Talking to the Outside World
Kinode communicates with the Kinode network using the Kinode Networking Protocol. But nodes must also be able to communicate with the outside world. These recipes will walk through a variety of communication methods. Briefly, Kinode can speak both HTTP and WebSockets, and can operate as a client or a server for both. You can find the APIs for HTTP client and server, as well as for WebSockets elsewhere. This document focuses on simple usage examples of each.
HTTP
HTTP Client
#![allow(unused)] fn main() { /// Simple example of sending an HTTP request. /// Usage: /// ``` /// # Start node. /// kit f /// /// # Start package from a new terminal. /// kit bs http-client /// ``` use kinode_process_lib::{call_init, http, println, Address}; wit_bindgen::generate!({ path: "target/wit", world: "process-v1", }); const URL: &str = "https://raw.githubusercontent.com/kinode-dao/kinode-wit/master/kinode.wit"; call_init!(init); fn init(_our: Address) { println!("begin"); let url = url::Url::parse(URL).expect("failed to parse url"); let response = http::client::send_request_await_response(http::Method::GET, url, None, 5, vec![]); match response { Err(e) => panic!("request failed: {e:?}"), Ok(r) => { let r = String::from_utf8(r.body().clone()).expect("couldn't read response"); println!("{r}"); } } } }
HTTP Server
#![allow(unused)] fn main() { /// Simple example of running an HTTP server. /// Usage: /// ``` /// # Start node. /// kit f /// /// # Start package from a new terminal. /// kit bs http-server /// /// # Send an HTTP request. /// curl -X PUT -d '{"Hello": "greetings"}' http://localhost:8080/http-server:http-server:template.os /// ``` use anyhow::{anyhow, Result}; use kinode_process_lib::{await_message, call_init, get_blob, http, println, Address, Message}; wit_bindgen::generate!({ path: "target/wit", world: "process-v1", }); /// Handle a message from the HTTP server. fn handle_http_message(message: &Message) -> Result<()> { let Ok(server_request) = http::server::HttpServerRequest::from_bytes(message.body()) else { return Err(anyhow!("received a message with weird `body`!")); }; let Some(http_request) = server_request.request() else { return Err(anyhow!("received a WebSocket message, skipping")); }; if http_request.method().unwrap() != http::Method::PUT { return Err(anyhow!("received a non-PUT HTTP request, skipping")); } let Some(body) = get_blob() else { return Err(anyhow!( "received a PUT HTTP request with no body, skipping" )); }; http::server::send_response(http::StatusCode::OK, None, vec![]); println!( "{:?}", serde_json::from_slice::<serde_json::Value>(&body.bytes) ); Ok(()) } call_init!(init); fn init(_our: Address) { println!("begin"); let mut server = http::server::HttpServer::new(5); server .bind_http_path( "/", http::server::HttpBindingConfig::new(false, false, false, None), ) .unwrap(); loop { match await_message() { Ok(message) => { if message.source().process == "http-server:distro:sys" { if let Err(e) = handle_http_message(&message) { println!("{e}"); } } } Err(_send_error) => println!("got send error!"), } } } }
WebSockets
WebSockets Client
The Kinode process:
#![allow(unused)] fn main() { /// Simple example of using the WebSockets client. /// Usage: /// ``` /// # Start node. /// kit f /// /// # Start WS server from a new terminal. /// ./ws-client/ws-server.py /// /// # Start package from a new terminal. /// kit bs ws-client /// ``` use anyhow::{anyhow, Result}; use kinode_process_lib::{ await_message, call_init, get_blob, http, println, Address, LazyLoadBlob, Message, }; #[cfg(feature = "test")] use kinode_process_lib::{OnExit, Request}; wit_bindgen::generate!({ path: "target/wit", world: "process-v1", }); const WS_URL: &str = "ws://localhost:8765"; const CONNECTION: u32 = 0; fn handle_http_message(message: &Message, connection: &u32) -> Result<()> { match serde_json::from_slice::<http::client::HttpClientRequest>(message.body())? { http::client::HttpClientRequest::WebSocketClose { channel_id } => { assert_eq!(*connection, channel_id); } http::client::HttpClientRequest::WebSocketPush { channel_id, message_type, } => { assert_eq!(*connection, channel_id); if message_type == http::client::WsMessageType::Close { println!("got Close push"); return Ok(()); } assert_eq!(message_type, http::client::WsMessageType::Text); let Some(blob) = get_blob() else { return Err(anyhow!("got WebSocketPush with no blob")); }; println!("Received from server: {:?}", String::from_utf8(blob.bytes)); http::client::send_ws_client_push( connection.clone(), http::client::WsMessageType::Text, LazyLoadBlob { mime: Some("application/json".to_string()), bytes: serde_json::to_vec("Hello from client").unwrap(), }, ); } } Ok(()) } fn talk_to_ws() -> Result<()> { let connection = CONNECTION; http::client::open_ws_connection(WS_URL.to_string(), None, connection)?; match await_message() { Ok(message) => { if message.source().process == "http-client:distro:sys" { if let Err(e) = handle_http_message(&message, &connection) { println!("{e}"); } } } Err(_send_error) => println!("got send error!"), } Ok(()) } #[cfg(feature = "test")] fn talk_to_ws_test() -> Result<()> { println!("in test"); let message = await_message()?; let parent_address = message.source(); println!("got parent {parent_address:?}"); match talk_to_ws() { Ok(_) => {} Err(e) => println!("error talking to ws: {e}"), } Request::to(parent_address) .body(serde_json::to_vec(&Ok::<(), ()>(())).unwrap()) .send() .unwrap(); OnExit::None.set().unwrap(); println!("done"); Ok(()) } call_init!(init); fn init(our: Address) { println!("{}: begin", our.process()); #[cfg(not(feature = "test"))] match talk_to_ws() { Ok(_) => {} Err(e) => println!("error talking to ws: {e}"), } #[cfg(feature = "test")] match talk_to_ws_test() { Ok(_) => {} Err(e) => println!("error talking to ws: {e}"), } } }
An example WS server:
#!/usr/bin/env python3
import asyncio
import websockets
async def ws_handler(websocket, path, shutdown_event):
try:
await websocket.send("ack client connection")
response = await websocket.recv()
print(f"Received response from client: {response}")
finally:
await websocket.close()
shutdown_event.set()
async def main():
shutdown_event = asyncio.Event()
async with websockets.serve(lambda ws, path: ws_handler(ws, path, shutdown_event), "localhost", 8765):
print("Server started at ws://localhost:8765")
await shutdown_event.wait()
print("Shutting down server.")
if __name__ == '__main__':
asyncio.run(main())
Full example package & client.
WebSockets Server
The Kinode process:
#![allow(unused)] fn main() { /// Simple example of running a WebSockets server. /// Usage: /// ``` /// # Start node. /// kit f /// /// # Start package from a new terminal. /// kit bs ws-server /// /// # Connect from WS client script. /// ./ws-server/ws-client.py /// ``` use anyhow::{anyhow, Result}; use kinode_process_lib::{ await_message, call_init, get_blob, http, println, Address, LazyLoadBlob, Message, }; wit_bindgen::generate!({ path: "target/wit", world: "process-v1", }); const WS_PATH: &str = "/"; fn handle_http_message( _our: &Address, message: &Message, connection: &mut Option<u32>, ) -> Result<()> { match serde_json::from_slice::<http::server::HttpServerRequest>(message.body())? { http::server::HttpServerRequest::Http(_) => { return Err(anyhow!("unexpected HTTP request")); } http::server::HttpServerRequest::WebSocketOpen { path, channel_id } => { assert_eq!(path, WS_PATH); assert_eq!(*connection, None); *connection = Some(channel_id); http::server::send_ws_push( channel_id, http::server::WsMessageType::Text, LazyLoadBlob { mime: Some("application/json".to_string()), bytes: serde_json::to_vec("ack client connection").unwrap(), }, ); } http::server::HttpServerRequest::WebSocketClose(channel_id) => { assert_eq!(*connection, Some(channel_id)); *connection = None; } http::server::HttpServerRequest::WebSocketPush { channel_id, message_type, } => { assert_eq!(*connection, Some(channel_id)); if message_type == http::server::WsMessageType::Close { println!("got Close push"); return Ok(()); } assert_eq!(message_type, http::server::WsMessageType::Text); let Some(blob) = get_blob() else { return Err(anyhow!("got WebSocketPush with no blob")); }; println!("got Text from WS: {:?}", String::from_utf8(blob.bytes)); } } Ok(()) } call_init!(init); fn init(our: Address) { println!("begin"); let mut connection: Option<u32> = None; let mut server = http::server::HttpServer::new(5); server .bind_ws_path( WS_PATH, http::server::WsBindingConfig::new(false, false, false), ) .unwrap(); loop { match await_message() { Ok(message) => { if message.source().process == "http-server:distro:sys" { if let Err(e) = handle_http_message(&our, &message, &mut connection) { println!("{e}"); } } } Err(_send_error) => println!("got send error!"), } } } }
An example WS client:
#!/usr/bin/env python3
import asyncio
import websockets
async def connect_websocket(
uri="ws://localhost:8080/ws-server:ws-server:template.os",
max_retries=5,
delay_secs=0.5,
):
attempt = 0
while attempt < max_retries:
try:
return await websockets.connect(uri, ping_interval=None)
except (
websockets.ConnectionClosedError,
websockets.InvalidURI,
websockets.InvalidStatusCode,
) as e:
attempt += 1
await asyncio.sleep(delay_secs)
raise Exception("Max retries exceeded, unable to connect.")
async def websocket_client():
websocket = await connect_websocket()
message = await websocket.recv()
print(f"Received from server: {message}")
response = "Hello from client"
await websocket.send(response)
print(f"Sent to server: {response}")
await websocket.close()
def main():
asyncio.run(websocket_client())
if __name__ == "__main__":
main()
Full example package & client.
WebSockets Server with Reply Type
One constraint of Kinode's default WebSockets server Push is that it breaks the Request/Response pairing. This is because the server cannot specify it expects a Response back: all Pushes are Requests.
Use the following pattern to allow the WebSocket client to reply with a Response:
The Kinode process:
#![allow(unused)] fn main() { /// Simple example of running a WebSockets server, specifying reply type as Response. /// Usage: /// ``` /// # Start node. /// kit f /// /// # Start package from a new terminal. /// kit bs ws-server-with-reply /// /// # Connect from WS client script. /// ./ws-server/ws-client.py /// ``` use anyhow::{anyhow, Result}; use kinode_process_lib::{ await_message, call_init, get_blob, http, println, Address, LazyLoadBlob, Message, Request, }; wit_bindgen::generate!({ path: "target/wit", world: "process-v1", }); const WS_PATH: &str = "/"; fn handle_http_message( _our: &Address, message: &Message, connection: &mut Option<u32>, ) -> Result<()> { match serde_json::from_slice::<http::server::HttpServerRequest>(message.body())? { http::server::HttpServerRequest::Http(_) => { return Err(anyhow!("unexpected HTTP request")); } http::server::HttpServerRequest::WebSocketOpen { path, channel_id } => { assert_eq!(path, WS_PATH); assert_eq!(*connection, None); *connection = Some(channel_id.clone()); Request::to("our@http-server:distro:sys".parse::<Address>()?) .body(serde_json::to_vec( &http::server::HttpServerAction::WebSocketExtPushOutgoing { channel_id, message_type: http::server::WsMessageType::Binary, desired_reply_type: http::server::MessageType::Response, }, )?) .expects_response(15) .blob(LazyLoadBlob { mime: Some("application/json".to_string()), bytes: rmp_serde::to_vec_named("ack client connection").unwrap(), }) .send()?; } http::server::HttpServerRequest::WebSocketClose(channel_id) => { assert_eq!(*connection, Some(channel_id)); *connection = None; } http::server::HttpServerRequest::WebSocketPush { channel_id, message_type, } => { assert_eq!(*connection, Some(channel_id)); if message_type == http::server::WsMessageType::Close { println!("got Close push"); return Ok(()); } assert_eq!(message_type, http::server::WsMessageType::Binary); let Some(blob) = get_blob() else { return Err(anyhow!("got WebSocketPush with no blob")); }; println!( "got Text from WS: {:?}", rmp_serde::from_slice::<String>(&blob.bytes) ); } } Ok(()) } call_init!(init); fn init(our: Address) { println!("begin"); let mut connection: Option<u32> = None; let mut server = http::server::HttpServer::new(5); server .bind_ws_path( WS_PATH, http::server::WsBindingConfig::new(false, false, false), ) .unwrap(); loop { match await_message() { Ok(message) => { if message.source().process == "http-server:distro:sys" { if let Err(e) = handle_http_message(&our, &message, &mut connection) { println!("{e}"); } } } Err(_send_error) => println!("got send error!"), } } } }
An example WS client:
#!/usr/bin/env python3
import asyncio
import msgpack
import websockets
async def connect_websocket(
uri="ws://localhost:8080/ws-server-with-reply:ws-server-with-reply:template.os",
max_retries=5,
delay_secs=0.5,
):
attempt = 0
while attempt < max_retries:
try:
return await websockets.connect(uri, ping_interval=None)
except (
websockets.ConnectionClosedError,
websockets.InvalidURI,
websockets.InvalidStatusCode,
) as e:
attempt += 1
await asyncio.sleep(delay_secs)
raise Exception("Max retries exceeded, unable to connect.")
async def websocket_client():
websocket = await connect_websocket()
message = await websocket.recv()
message = msgpack.unpackb(message, raw=False)
message = message["WebSocketExtPushData"]
m = msgpack.unpackb(bytes(message["blob"]), raw=False)
print(f"Received from server: {m}")
response = "Hello from client"
response = msgpack.packb(response, use_bin_type=True)
await websocket.send(response)
await websocket.close()
def main():
asyncio.run(websocket_client())
if __name__ == "__main__":
main()
Full example package & client.
You can find this pattern used in Kinode Extensions.
Exporting & Importing Package APIs
Kinode packages can export APIs, as discussed here. Processes can also import APIs. These APIs can consist of types as well as functions. This recipe focuses on:
- Simple examples of exporting and importing APIs (find the full code here).
- Demonstrations of
kittooling to help build and export or import APIs.
Exporting an API
APIs are defined in a WIT file. A brief summary of more thorough discussion is provided here:
- WIT (Wasm Interface Type) is a language to define APIs.
Kinode packages may define a WIT API by placing a WIT file in the top-level
api/directory. - Processes define a WIT
interface. - Packages define a WIT
world. - APIs define their own WIT
worldthatexports at least one processes WITinterface.
Example: Remote File Storage Server
WIT API
#![allow(unused)] fn main() { interface server { variant client-request { put-file(string), get-file(string), list-files, } variant client-response { put-file(result<_, string>), get-file(result<_, string>), list-files(result<list<string>, string>), } /// `put-file()`: take a file from local VFS and store on remote `host`. put-file: func(host: string, path: string, name: string) -> result<_, string>; /// `get-file()`: retrieve a file from remote `host`. /// The file populates the lazy load blob and can be retrieved /// by a call of `get-blob()` after calling `get-file()`. get-file: func(host: string, name: string) -> result<_, string>; /// `list-files()`: list all files we have stored on remote `host`. list-files: func(host: string) -> result<list<string>, string>; } world server-template-dot-os-api-v0 { export server; } world server-template-dot-os-v0 { import server; include process-v1; } }
As summarized above, the server process defines an interface of the same name, and the package defines the world server-template-dot-os-v0.
The API is defined by server-template-dot-os-api-v0: the functions in the server interface are defined below by wit_bindgen::generate!()ing that world.
The example covered in this document shows an interface that has functions exported.
However, for interfaces that export only types, no -api- world (like server-template-dot-os-api-v0 here) is required.
Instead, the WIT API alone suffices to export the types, and the importer writes a world that looks like this, below.
For example, consider the chat template's api/ and its usage in the test/ package:
kit n my-chat
cat my-chat/api/my-chat\:template.os-v0.wit
cat my-chat/test/my-chat-test/api/my-chat-test\:template.os-v0.wit
API Function Definitions
#![allow(unused)] fn main() { use crate::exports::kinode::process::server::{ClientRequest, ClientResponse, Guest}; use kinode_process_lib::{vfs, Request, Response}; wit_bindgen::generate!({ path: "target/wit", world: "server-template-dot-os-api-v0", generate_unused_types: true, additional_derives: [serde::Deserialize, serde::Serialize, process_macros::SerdeJsonInto], }); const READ_TIMEOUT_SECS: u64 = 5; const PUT_TIMEOUT_SECS: u64 = 5; fn make_put_file_error(message: &str) -> anyhow::Result<Result<(), String>> { Response::new() .body(ClientResponse::PutFile(Err(message.to_string()))) .send()?; return Err(anyhow::anyhow!(message.to_string())); } fn make_get_file_error(message: &str) -> anyhow::Result<Result<(), String>> { Response::new() .body(ClientResponse::GetFile(Err(message.to_string()))) .send()?; return Err(anyhow::anyhow!(message.to_string())); } fn make_list_files_error(message: &str) -> anyhow::Result<Result<Vec<String>, String>> { Response::new() .body(ClientResponse::GetFile(Err(message.to_string()))) .send()?; return Err(anyhow::anyhow!(message.to_string())); } fn put_file(host: String, path: String, name: String) -> anyhow::Result<Result<(), String>> { // rather than using `vfs::open_file()?.read()?`, which reads // the file into process memory, send the Request to VFS ourselves, // `inherit`ing the file contents into the ClientRequest // // let contents = vfs::open_file(path, false, None)?.read()?; // let response = Request::new() .target(("our", "vfs", "distro", "sys")) .body(serde_json::to_vec(&vfs::VfsRequest { path: path.to_string(), action: vfs::VfsAction::Read, })?) .send_and_await_response(READ_TIMEOUT_SECS)??; let response = response.body(); let Ok(vfs::VfsResponse::Read) = serde_json::from_slice(&response) else { return make_put_file_error(&format!("Could not find file at {path}.")); }; let ClientResponse::PutFile(result) = Request::new() .target((&host, "server", "server", "template.os")) .inherit(true) .body(ClientRequest::PutFile(name)) .send_and_await_response(PUT_TIMEOUT_SECS)?? .body() .try_into()? else { return make_put_file_error(&format!("Got unexpected Response from server.")); }; Ok(result) } fn get_file(host: String, name: String) -> anyhow::Result<Result<(), String>> { let ClientResponse::GetFile(result) = Request::new() .target((&host, "server", "server", "template.os")) .body(ClientRequest::GetFile(name)) .send_and_await_response(PUT_TIMEOUT_SECS)?? .body() .try_into()? else { return make_get_file_error(&format!("Got unexpected Response from server.")); }; Ok(result) } fn list_files(host: String) -> anyhow::Result<Result<Vec<String>, String>> { let ClientResponse::ListFiles(result) = Request::new() .target((&host, "server", "server", "template.os")) .inherit(true) .body(ClientRequest::ListFiles) .send_and_await_response(PUT_TIMEOUT_SECS)?? .body() .try_into()? else { return make_list_files_error(&format!("Got unexpected Response from server.")); }; Ok(result) } struct Api; impl Guest for Api { fn put_file(host: String, path: String, name: String) -> Result<(), String> { match put_file(host, path, name) { Ok(result) => result, Err(e) => Err(format!("{e:?}")), } } fn get_file(host: String, name: String) -> Result<(), String> { match get_file(host, name) { Ok(result) => result, Err(e) => Err(format!("{e:?}")), } } fn list_files(host: String) -> Result<Vec<String>, String> { match list_files(host) { Ok(result) => result, Err(ref e) => Err(format!("{e:?}")), } } } export!(Api); }
Functions must be defined if exported in an interface, as they are here.
Functions are defined by creating a directory just like a process directory, but with a slightly different lib.rs (see directory structure).
Note the definition of struct Api, the impl Guest for Api, and the export!(Api):
#![allow(unused)] fn main() { struct Api; impl Guest for Api { ... } export!(Api); }
The exported functions are defined here.
Note the function signatures match those defined in the WIT API.
Process
A normal process: the server handles Requests from consumers of the API.
#![allow(unused)] fn main() { use std::collections::{HashMap, HashSet}; use crate::kinode::process::server::{ClientRequest, ClientResponse}; use kinode_process_lib::{ await_message, call_init, get_blob, println, vfs, Address, Message, PackageId, Request, Response, }; wit_bindgen::generate!({ path: "target/wit", world: "server-template-dot-os-v0", generate_unused_types: true, additional_derives: [serde::Deserialize, serde::Serialize, process_macros::SerdeJsonInto], }); type State = HashMap<String, HashSet<String>>; const READ_TIMEOUT_SECS: u64 = 5; fn make_drive_name(our: &PackageId, source: &str) -> String { format!("/{our}/{source}") } fn make_put_file_error(message: &str) -> anyhow::Result<()> { Response::new() .body(ClientResponse::PutFile(Err(message.to_string()))) .send()?; return Err(anyhow::anyhow!(message.to_string())); } fn make_get_file_error(message: &str) -> anyhow::Result<()> { Response::new() .body(ClientResponse::GetFile(Err(message.to_string()))) .send()?; return Err(anyhow::anyhow!(message.to_string())); } fn make_list_files_error(message: &str) -> anyhow::Result<()> { Response::new() .body(ClientResponse::ListFiles(Err(message.to_string()))) .send()?; return Err(anyhow::anyhow!(message.to_string())); } fn handle_put_file( name: &str, our: &PackageId, source: &str, state: &mut State, ) -> anyhow::Result<()> { let Some(ref blob) = get_blob() else { return make_put_file_error("Must give a file in the blob."); }; let drive = vfs::create_drive(our.clone(), source, None)?; vfs::create_file(&format!("{drive}/{name}"), None)?.write(blob.bytes())?; state .entry(source.to_string()) .or_insert_with(HashSet::new) .insert(name.to_string()); Response::new() .body(ClientResponse::PutFile(Ok(()))) .send()?; Ok(()) } fn handle_get_file(name: &str, our: &PackageId, source: &str, state: &State) -> anyhow::Result<()> { let Some(ref names) = state.get(source) else { return make_get_file_error(&format!("{source} has no files to Get.")); }; if !names.contains(name) { return make_get_file_error(&format!("{source} has no such file {name}.")); } // rather than using `vfs::open_file()?.read()?`, which reads // the file into process memory, send the Request to VFS ourselves, // `inherit`ing the file contents into the ClientResponse // // let contents = vfs::open_file(path, false, None)?.read()?; // let path = format!("{}/{name}", make_drive_name(our, source)); let response = Request::new() .target(("our", "vfs", "distro", "sys")) .body(serde_json::to_vec(&vfs::VfsRequest { path, action: vfs::VfsAction::Read, })?) .send_and_await_response(READ_TIMEOUT_SECS)??; let response = response.body(); let Ok(vfs::VfsResponse::Read) = serde_json::from_slice(&response) else { return make_get_file_error(&format!("Could not find file at {name}.")); }; Response::new() .inherit(true) .body(ClientResponse::GetFile(Ok(()))) .send()?; Ok(()) } fn handle_list_files(source: &str, state: &State) -> anyhow::Result<()> { let Some(ref names) = state.get(source) else { return make_list_files_error(&format!("{source} has no files to List.")); }; let mut names: Vec<String> = names.iter().cloned().collect(); names.sort(); Response::new() .body(ClientResponse::ListFiles(Ok(names))) .send()?; Ok(()) } fn handle_message(our: &Address, message: &Message, state: &mut State) -> anyhow::Result<()> { let source = message.source(); if !message.is_request() { return Err(anyhow::anyhow!("unexpected Response from {source}")); } match message.body().try_into()? { ClientRequest::PutFile(ref name) => { handle_put_file(name, &our.package_id(), source.node(), state)? } ClientRequest::GetFile(ref name) => { handle_get_file(name, &our.package_id(), source.node(), state)? } ClientRequest::ListFiles => handle_list_files(source.node(), state)?, } Ok(()) } call_init!(init); fn init(our: Address) { println!("begin"); let mut state: State = HashMap::new(); loop { match await_message() { Err(send_error) => println!("got SendError: {send_error}"), Ok(ref message) => match handle_message(&our, message, &mut state) { Err(e) => println!("got error while handling message: {e:?}"), Ok(_) => {} }, } } } }
Importing an API
Dependencies
metadata.json
The metadata.json file has a properties.dependencies field.
When the dependencies field is populated, kit build will fetch that dependency from either:
- A livenet Kinode hosting it.
- A local path.
- An HTTP endpoint (coming soon).
Fetching Dependencies
kit build resolves dependencies in a few ways.
The first is from a livenet Kinode hosting the depenency.
This method requires a --port (or -p for short) flag when building a package that has a non-empty dependencies field.
That --port corresponds to the Kinode hosting the API dependency.
To host an API, your Kinode must either:
- Have that package downloaded by the
app-store. - Be a live node, in which case it will attempt to contact the publisher of the package, and download the package. Thus, when developing on a fake node, you must first build and start any dependencies on your fake node before building packages that depend upon them: see usage example below.
The second way kit build resolves dependencies is with a local path.
Example: Remote File Storage Client Script
WIT API
#![allow(unused)] fn main() { world client-template-dot-os-v0 { import server; include process-v1; } }
Process
The client process here is a script.
In general, importers of APIs are just processes, but in this case, it made more sense for this specific functionality to write it as a script.
The Args and Command structs set up command-line parsing and are unrelated to the WIT API.
#![allow(unused)] fn main() { use clap::{Parser, Subcommand}; use crate::kinode::process::server::{get_file, list_files, put_file}; use kinode_process_lib::{await_next_message_body, call_init, get_blob, println, Address}; wit_bindgen::generate!({ path: "target/wit", world: "client-template-dot-os-v0", generate_unused_types: true, additional_derives: [serde::Deserialize, serde::Serialize, process_macros::SerdeJsonInto], }); #[derive(Parser)] #[command(version, about)] struct Args { #[command(subcommand)] command: Option<Command>, } #[derive(Subcommand)] enum Command { /// Take a file from local VFS and store on remote `host`. PutFile { host: String, #[arg(short, long)] path: String, #[arg(short, long)] name: Option<String>, }, /// Retrieve a file from remove `host`. GetFile { host: String, #[arg(short, long)] name: String, }, /// List all files we have stored on remote `host`. ListFiles { host: String }, } fn handle_put_file(host: &str, path: &str, name: &str) -> anyhow::Result<()> { match put_file(host, path, name) { Err(e) => Err(anyhow::anyhow!("{e}")), Ok(_) => { println!("Successfully PutFile {path} to host {host}."); Ok(()) } } } fn handle_get_file(host: &str, name: &str) -> anyhow::Result<()> { match get_file(host, name) { Err(e) => Err(anyhow::anyhow!("{e}")), Ok(_) => { if let Some(blob) = get_blob() { if let Ok(contents) = String::from_utf8(blob.bytes().to_vec()) { println!("Successfully GetFile {name} from host {host}:\n\n{contents}"); return Ok(()); } } println!("Successfully GetFile {name} from host {host}."); Ok(()) } } } fn handle_list_files(host: &str) -> anyhow::Result<()> { match list_files(host) { Err(e) => Err(anyhow::anyhow!("{e}")), Ok(paths) => { println!("{paths:#?}"); Ok(()) } } } fn execute() -> anyhow::Result<()> { let body = await_next_message_body()?; let body_string = format!("client {}", String::from_utf8(body)?); let args = body_string.split(' '); match Args::try_parse_from(args)?.command { Some(Command::PutFile { ref host, ref path, name, }) => handle_put_file( host, path, &name.unwrap_or_else(|| path.split('/').last().unwrap().to_string()), )?, Some(Command::GetFile { ref host, ref name }) => handle_get_file(host, name)?, Some(Command::ListFiles { ref host }) => handle_list_files(host)?, None => {} } Ok(()) } call_init!(init); fn init(_our: Address) { match execute() { Ok(_) => {} Err(e) => println!("error: {e:?}"), } } }
Remote File Storage Usage Example
Build
# Start fake node to host server.
kit f
# Start fake node to host client.
kit f -o /tmp/kinode-fake-node-2 -p 8081 -f fake2.dev
# Build & start server.
## Note starting is required because we need a deployed copy of server's API in order to build client.
## Below is it assumed that `kinode-book` is the CWD.
kit bs src/../code/remote-file-storage/server
# Build & start client.
## Here the `-p 8080` is to fetch deps for building client (see the metadata.json dependencies field).
kit b src/../code/remote-file-storage/client -p 8080 && kit s src/../code/remote-file-storage/client -p 8081
An alternative way to satisfy the server dependency of client:
## The `-l` satisfies the dependency using a local path.
kit b src/../code/remote-file-storage/client -l src/../code/remote-file-storage/server
Usage
# In fake2.dev terminal:
## Put a file onto fake.dev.
client:client:template.os put-file fake.dev -p client:template.os/pkg/manifest.json -n manifest.json
## Check the file was Put properly.
client:client:template.os list-files fake.dev
## Put a different file.
client:client:template.os put-file fake.dev -p client:template.os/pkg/scripts.json -n scripts.json
## Check the file was Put properly.
client:client:template.os list-files fake.dev
## Read out a file.
client:client:template.os get-file fake.dev -n scripts.json
Exporting Workers in Package APIs
Kinode packages can export workers and expose them in easy-to-use ways. Exporting and importing functions is discussed in the previous recipe. This recipe focuses on:
- A simple example of exporting a worker and exposing it in an ergonmoic API.
- A simple example of importing a worker.
- Demonstrations of
kittooling for the above.
Exporting a Worker
Exporting or importing a worker is much the same as exporting or importing an API as usual as discussed in the previous recipe.
The main difference, in general, is that the exporter must include the worker when kit building — see below.
In the specific example here, the exporter also exports a function that makes use of the worker ergonomic: that function, start_download(), spawn()s the worker.
In addition, in this specific example, the importer handles the message types of the worker.
Example: File Transfer
WIT API
#![allow(unused)] fn main() { ... interface file-transfer-worker { use standard.{address}; /// external-facing requests variant request { /// download starts a download. /// * used by requestor to start whole process /// * used by provider to spin up worker to serve request download(download-request), /// progress is from worker to parent /// * acks not required, but provided for completeness progress(progress-request), } variant response { download(result<_, string>), /// ack: not required, but provided for completeness progress, } /// requests used between workers to transfer the file /// parent will not receive these, so need not handle them variant internal-request { chunk(chunk-request), size(u64), } record download-request { name: string, target: address, is-requestor: bool, } record progress-request { name: string, progress: u64, } record chunk-request { name: string, offset: u64, length: u64, } /// easiest way to use file-transfer-worker /// handle file-transfer-worker::request by calling this helper function start-download: func( our: address, source: address, name: string, target: address, is-requestor: bool, ) -> result<_, string>; } world file-transfer-worker-api-v0 { export file-transfer-worker; } ... }
API Function Definitions
The API here spawn()s a worker, and so the worker is part of the API.
API
#![allow(unused)] fn main() { use crate::exports::kinode::process::file_transfer_worker::{ DownloadRequest, Guest, Request as WorkerRequest, Response as WorkerResponse, }; use crate::kinode::process::standard::Address as WitAddress; use kinode_process_lib::{our_capabilities, spawn, Address, OnExit, Request, Response}; wit_bindgen::generate!({ path: "target/wit", world: "file-transfer-worker-api-v0", generate_unused_types: true, additional_derives: [serde::Deserialize, serde::Serialize, process_macros::SerdeJsonInto], }); fn start_download( our: &WitAddress, source: &WitAddress, name: &str, target: &WitAddress, is_requestor: bool, ) -> anyhow::Result<()> { // spin up a worker, initialize based on whether it's a downloader or a sender. let our_worker = spawn( None, &format!( "{}:{}/pkg/file_transfer_worker.wasm", our.process.package_name, our.process.publisher_node, ), OnExit::None, our_capabilities(), vec![], false, )?; let target = if is_requestor { target } else { source }; let our_worker_address = Address { node: our.node.clone(), process: our_worker, }; Response::new() .body(WorkerResponse::Download(Ok(()))) .send()?; Request::new() .expects_response(5) .body(WorkerRequest::Download(DownloadRequest { name: name.to_string(), target: target.clone(), is_requestor, })) .target(&our_worker_address) .send()?; Ok(()) } struct Api; impl Guest for Api { fn start_download( our: WitAddress, source: WitAddress, name: String, target: WitAddress, is_requestor: bool, ) -> Result<(), String> { match start_download(&our, &source, &name, &target, is_requestor) { Ok(result) => Ok(result), Err(e) => Err(format!("{e:?}")), } } } export!(Api); }
Worker
#![allow(unused)] fn main() { use crate::kinode::process::file_transfer_worker::{ ChunkRequest, DownloadRequest, InternalRequest, ProgressRequest, Request as WorkerRequest, Response as WorkerResponse, }; use crate::kinode::process::standard::{Address as WitAddress, ProcessId as WitProcessId}; use kinode_process_lib::{ await_message, call_init, get_blob, println, vfs::{open_dir, open_file, Directory, File, SeekFrom}, Address, Message, ProcessId, Request, Response, }; wit_bindgen::generate!({ path: "target/wit", world: "{package_name_kebab}-{publisher_dotted_kebab}-v0", generate_unused_types: true, additional_derives: [serde::Deserialize, serde::Serialize, process_macros::SerdeJsonInto], }); #[derive(Debug, serde::Deserialize, serde::Serialize, process_macros::SerdeJsonInto)] #[serde(untagged)] // untagged as a meta-type for all incoming messages enum Msg { // requests WorkerRequest(WorkerRequest), InternalRequest(InternalRequest), // responses WorkerResponse(WorkerResponse), } impl From<WitAddress> for Address { fn from(address: WitAddress) -> Self { Address { node: address.node, process: address.process.into(), } } } impl From<WitProcessId> for ProcessId { fn from(process: WitProcessId) -> Self { ProcessId { process_name: process.process_name, package_name: process.package_name, publisher_node: process.publisher_node, } } } const CHUNK_SIZE: u64 = 1048576; // 1MB fn handle_worker_request( request: &WorkerRequest, file: &mut Option<File>, files_dir: &Directory, ) -> anyhow::Result<bool> { match request { WorkerRequest::Download(DownloadRequest { name, target, is_requestor, }) => { Response::new() .body(WorkerResponse::Download(Ok(()))) .send()?; // open/create empty file in both cases. let mut active_file = open_file(&format!("{}/{}", files_dir.path, &name), true, None)?; if *is_requestor { *file = Some(active_file); Request::new() .expects_response(5) .body(WorkerRequest::Download(DownloadRequest { name: name.to_string(), target: target.clone(), is_requestor: false, })) .target::<Address>(target.clone().into()) .send()?; } else { // we are sender: chunk the data, and send it. let size = active_file.metadata()?.len; let num_chunks = (size as f64 / CHUNK_SIZE as f64).ceil() as u64; // give receiving worker file size so it can track download progress Request::new() .body(InternalRequest::Size(size)) .target(target.clone()) .send()?; active_file.seek(SeekFrom::Start(0))?; for i in 0..num_chunks { let offset = i * CHUNK_SIZE; let length = CHUNK_SIZE.min(size - offset); let mut buffer = vec![0; length as usize]; active_file.read_at(&mut buffer)?; Request::new() .body(InternalRequest::Chunk(ChunkRequest { name: name.clone(), offset, length, })) .target(target.clone()) .blob_bytes(buffer) .send()?; } return Ok(true); } } WorkerRequest::Progress(_) => { return Err(anyhow::anyhow!( "worker: got unexpected WorkerRequest::Progress", )); } } Ok(false) } fn handle_internal_request( request: &InternalRequest, file: &mut Option<File>, size: &mut Option<u64>, parent: &Option<Address>, ) -> anyhow::Result<bool> { match request { InternalRequest::Chunk(ChunkRequest { name, offset, length, }) => { // someone sending a chunk to us let file = match file { Some(file) => file, None => { return Err(anyhow::anyhow!( "worker: receive error: no file initialized" )); } }; let bytes = match get_blob() { Some(blob) => blob.bytes, None => { return Err(anyhow::anyhow!("worker: receive error: no blob")); } }; file.write_all(&bytes)?; // if sender has sent us a size, give a progress update to main transfer let Some(ref parent) = parent else { return Ok(false); }; if let Some(size) = size { let progress = ((offset + length) as f64 / *size as f64 * 100.0) as u64; Request::new() .expects_response(5) .body(WorkerRequest::Progress(ProgressRequest { name: name.to_string(), progress, })) .target(parent) .send()?; if progress >= 100 { return Ok(true); } } } InternalRequest::Size(incoming_size) => { *size = Some(*incoming_size); } } Ok(false) } fn handle_worker_response(response: &WorkerResponse) -> anyhow::Result<bool> { match response { WorkerResponse::Download(ref result) => { if let Err(e) = result { return Err(anyhow::anyhow!("{e}")); } } WorkerResponse::Progress => {} } Ok(false) } fn handle_message( our: &Address, message: &Message, file: &mut Option<File>, files_dir: &Directory, size: &mut Option<u64>, parent: &mut Option<Address>, ) -> anyhow::Result<bool> { return Ok(match message.body().try_into()? { // requests Msg::WorkerRequest(ref wr) => { *parent = Some(message.source().clone()); handle_worker_request(wr, file, files_dir)? } Msg::InternalRequest(ref ir) => handle_internal_request(ir, file, size, parent)?, // responses Msg::WorkerResponse(ref wr) => handle_worker_response(wr)?, }); } call_init!(init); fn init(our: Address) { println!("worker: begin"); let start = std::time::Instant::now(); let drive_path = format!("{}/files", our.package_id()); let files_dir = open_dir(&drive_path, false, None).unwrap(); let mut file: Option<File> = None; let mut size: Option<u64> = None; let mut parent: Option<Address> = None; loop { match await_message() { Err(send_error) => println!("worker: got SendError: {send_error}"), Ok(ref message) => { match handle_message(&our, message, &mut file, &files_dir, &mut size, &mut parent) { Ok(exit) => { if exit { println!("worker: done: exiting, took {:?}", start.elapsed()); break; } } Err(e) => println!("worker: got error while handling message: {e:?}"), } } } } } }
Process
The file_transfer process imports and uses the exported start_download():
#![allow(unused)] fn main() { use crate::kinode::process::standard::{Address as WitAddress, ProcessId as WitProcessId}; use crate::kinode::process::file_transfer_worker::{start_download, Request as WorkerRequest, Response as WorkerResponse, DownloadRequest, ProgressRequest}; use crate::kinode::process::{package_name}::{Request as TransferRequest, Response as TransferResponse, FileInfo}; use kinode_process_lib::{ await_message, call_init, println, vfs::{create_drive, metadata, open_dir, Directory, FileType}, Address, Message, ProcessId, Response, }; wit_bindgen::generate!({ path: "target/wit", world: "{package_name_kebab}-{publisher_dotted_kebab}-v0", generate_unused_types: true, additional_derives: [serde::Deserialize, serde::Serialize, process_macros::SerdeJsonInto], }); #[derive(Debug, serde::Deserialize, serde::Serialize, process_macros::SerdeJsonInto)] #[serde(untagged)] // untagged as a meta-type for all incoming messages enum Msg { // requests TransferRequest(TransferRequest), WorkerRequest(WorkerRequest), // responses TransferResponse(TransferResponse), WorkerResponse(WorkerResponse), } impl From<Address> for WitAddress { fn from(address: Address) -> Self { WitAddress { node: address.node, process: address.process.into(), } } } impl From<ProcessId> for WitProcessId { fn from(process: ProcessId) -> Self { WitProcessId { process_name: process.process_name, package_name: process.package_name, publisher_node: process.publisher_node, } } } fn ls_files(files_dir: &Directory) -> anyhow::Result<Vec<FileInfo>> { let entries = files_dir.read()?; let files: Vec<FileInfo> = entries .iter() .filter_map(|file| match file.file_type { FileType::File => match metadata(&file.path, None) { Ok(metadata) => Some(FileInfo { name: file.path.clone(), size: metadata.len, }), Err(_) => None, }, _ => None, }) .collect(); Ok(files) } fn handle_transfer_request( request: &TransferRequest, files_dir: &Directory, ) -> anyhow::Result<()> { match request { TransferRequest::ListFiles => { let files = ls_files(files_dir)?; Response::new() .body(TransferResponse::ListFiles(files)) .send()?; } } Ok(()) } fn handle_worker_request( our: &Address, source: &Address, request: &WorkerRequest, ) -> anyhow::Result<()> { match request { WorkerRequest::Download(DownloadRequest { ref name, ref target, is_requestor }) => { match start_download( &our.clone().into(), &source.clone().into(), name, target, *is_requestor, ) { Ok(_) => {} Err(e) => return Err(anyhow::anyhow!("{e}")), } } WorkerRequest::Progress(ProgressRequest { name, progress }) => { println!("{} progress: {}%", name, progress); Response::new() .body(WorkerResponse::Progress) .send()?; } } Ok(()) } fn handle_transfer_response(source: &Address, response: &TransferResponse) -> anyhow::Result<()> { match response { TransferResponse::ListFiles(ref files) => { println!( "{}", files.iter(). fold(format!("{source} available files:\nFile\t\tSize (bytes)\n"), |mut msg, file| { msg.push_str(&format!( "{}\t\t{}", file.name.split('/').last().unwrap(), file.size, )); msg }) ); } } Ok(()) } fn handle_worker_response(response: &WorkerResponse) -> anyhow::Result<()> { match response { WorkerResponse::Download(ref result) => { if let Err(e) = result { return Err(anyhow::anyhow!("{e}")) } } WorkerResponse::Progress => {} } Ok(()) } fn handle_message( our: &Address, message: &Message, files_dir: &Directory, ) -> anyhow::Result<()> { match message.body().try_into()? { // requests Msg::TransferRequest(ref tr) => handle_transfer_request(tr, files_dir), Msg::WorkerRequest(ref wr) => handle_worker_request(our, message.source(), wr), // responses Msg::TransferResponse(ref tr) => handle_transfer_response(message.source(), tr), Msg::WorkerResponse(ref wr) => handle_worker_response(wr), } } call_init!(init); fn init(our: Address) { println!("begin"); let drive_path = create_drive(our.package_id(), "files", None).unwrap(); let files_dir = open_dir(&drive_path, false, None).unwrap(); loop { match await_message() { Err(send_error) => println!("got SendError: {send_error}"), Ok(ref message) => match handle_message(&our, message, &files_dir) { Ok(_) => {} Err(e) => println!("got error while handling message: {e:?}"), } } } } }
Importing an API
Dependencies
metadata.json
The metadata.json file has a properties.dependencies field.
When the dependencies field is populated, kit build will fetch that dependency from a Kinode hosting it.
See previous recipe for more discussion of dependencies.
Example: Chat with File Transfer
The example here is the kit n chat chat template with the small addition of file transfer functionality.
The addition of file transfer requires changes to the WIT API (to import the file-transfer-worker interface, e.g.) as well as to the process itself to make use of the imported types and functions.
Compare the process with the unmodified kit n chat process.
WIT API
#![allow(unused)] fn main() { interface chat-with-file-transfer { variant request { send(send-request), /// history of chat with given node history(string), } variant response { send, history(list<chat-message>), } record send-request { target: string, message: string, } record chat-message { author: string, content: string, } } world chat-with-file-transfer-template-dot-os-v0 { import chat-with-file-transfer; import file-transfer-worker; include process-v1; } }
Process
#![allow(unused)] fn main() { use std::collections::HashMap; use crate::kinode::process::chat_with_file_transfer::{ ChatMessage, Request as ChatRequest, Response as ChatResponse, SendRequest, }; use crate::kinode::process::file_transfer_worker::{ start_download, DownloadRequest, ProgressRequest, Request as WorkerRequest, Response as WorkerResponse, }; use crate::kinode::process::standard::{Address as WitAddress, ProcessId as WitProcessId}; use kinode_process_lib::{ await_message, call_init, get_capability, println, vfs::{create_drive, open_file}, Address, Message, ProcessId, Request, Response, }; wit_bindgen::generate!({ path: "target/wit", world: "chat-with-file-transfer-template-dot-os-v0", generate_unused_types: true, additional_derives: [serde::Deserialize, serde::Serialize, process_macros::SerdeJsonInto], }); #[derive(Debug, serde::Deserialize, serde::Serialize, process_macros::SerdeJsonInto)] #[serde(untagged)] // untagged as a meta-type for all incoming messages enum Msg { // requests ChatRequest(ChatRequest), WorkerRequest(WorkerRequest), // responses WorkerResponse(WorkerResponse), } impl From<Address> for WitAddress { fn from(address: Address) -> Self { WitAddress { node: address.node, process: address.process.into(), } } } impl From<ProcessId> for WitProcessId { fn from(process: ProcessId) -> Self { WitProcessId { process_name: process.process_name, package_name: process.package_name, publisher_node: process.publisher_node, } } } type MessageArchive = HashMap<String, Vec<ChatMessage>>; fn handle_chat_request( our: &Address, source: &Address, request: &ChatRequest, message_archive: &mut MessageArchive, ) -> anyhow::Result<()> { match request { ChatRequest::Send(SendRequest { ref target, ref message, }) => { if target == &our.node { println!("{}: {}", source.node, message); let message = ChatMessage { author: source.node.clone(), content: message.into(), }; message_archive .entry(source.node.clone()) .and_modify(|e| e.push(message.clone())) .or_insert(vec![message]); } else { let _ = Request::new() .target(Address { node: target.clone(), process: "chat-with-file-transfer:chat-with-file-transfer:template.os" .parse()?, }) .body(request) .send_and_await_response(5)? .unwrap(); let message = ChatMessage { author: our.node.clone(), content: message.into(), }; message_archive .entry(target.clone()) .and_modify(|e| e.push(message.clone())) .or_insert(vec![message]); } Response::new().body(ChatResponse::Send).send().unwrap(); } ChatRequest::History(ref node) => { Response::new() .body(ChatResponse::History( message_archive .get(node) .map(|msgs| msgs.clone()) .unwrap_or_default(), )) .send() .unwrap(); } } Ok(()) } fn handle_worker_request( our: &Address, source: &Address, request: &WorkerRequest, ) -> anyhow::Result<()> { match request { WorkerRequest::Download(DownloadRequest { ref name, ref target, is_requestor, }) => { match start_download( &our.clone().into(), &source.clone().into(), name, target, *is_requestor, ) { Ok(_) => {} Err(e) => return Err(anyhow::anyhow!("{e}")), } } WorkerRequest::Progress(ProgressRequest { name, progress }) => { println!("{} progress: {}%", name, progress); Response::new().body(WorkerResponse::Progress).send()?; } } Ok(()) } fn handle_worker_response(response: &WorkerResponse) -> anyhow::Result<()> { match response { WorkerResponse::Download(ref result) => { if let Err(e) = result { return Err(anyhow::anyhow!("{e}")); } } WorkerResponse::Progress => {} } Ok(()) } fn handle_message( our: &Address, message: &Message, message_archive: &mut MessageArchive, ) -> anyhow::Result<()> { match message.body().try_into()? { // requests Msg::ChatRequest(ref cr) => handle_chat_request(our, message.source(), cr, message_archive), Msg::WorkerRequest(ref wr) => handle_worker_request(our, message.source(), wr), // responses Msg::WorkerResponse(ref wr) => handle_worker_response(wr), } } #[cfg(feature = "test")] #[derive(Debug, serde::Deserialize, serde::Serialize, process_macros::SerdeJsonInto)] #[cfg(feature = "test")] enum Setup { Caps, WriteFile { name: String, contents: Vec<u8> }, } #[cfg(feature = "test")] fn handle_tester_setup(our: &Address, drive_path: &str) -> anyhow::Result<()> { println!("awaiting setup..."); let Ok(message) = await_message() else { return Err(anyhow::anyhow!("a")); }; // TODO: confirm its from tester match message.body().try_into()? { Setup::Caps => { println!("got caps..."); let vfs_read_cap = serde_json::json!({ "kind": "read", "drive": drive_path, }) .to_string(); let vfs_address = Address { node: our.node.clone(), process: "vfs:distro:sys".parse()?, }; let read_cap = get_capability(&vfs_address, &vfs_read_cap).unwrap(); Response::new() .body(vec![]) .capabilities(vec![read_cap]) .send() .unwrap(); println!("sent caps"); } Setup::WriteFile { ref name, ref contents, } => { println!("got write file..."); let file = open_file(&format!("{drive_path}/{name}"), true, None)?; file.write(contents)?; } } println!("setup done"); Ok(()) } call_init!(init); fn init(our: Address) { println!("begin"); let drive_path = create_drive(our.package_id(), "files", None).unwrap(); let mut message_archive = HashMap::new(); #[cfg(feature = "test")] handle_tester_setup(&our, &drive_path).unwrap(); loop { match await_message() { Err(send_error) => println!("got SendError: {send_error}"), Ok(ref message) => match handle_message(&our, message, &mut message_archive) { Ok(_) => {} Err(e) => println!("got error while handling message: {e:?}"), }, } } } }
Chat with File Transfer Usage Example
Build
# Start fake nodes.
kit f
kit f -o /tmp/kinode-fake-node-2 -p 8081 -f fake2.dev
# Create & build file_transfer dependency.
## The `-a` adds the worker Wasm file to the API so it can be exported properly.
kit n file_transfer -t file_transfer
kit b file_transfer -a file_transfer/pkg/file_transfer_worker.wasm
# Build chat_with_file_transfer.
## The `-l` satisfies the dependency using a local path.
kit b src/../code/chat-with-file-transfer -l file-transfer
# Start chat_with_file_transfer on fake nodes.
kit s src/../code/chat-with-file-transfer
kit s src/../code/chat-with-file-transfer -p 8081
Usage
# First, put a file into `/tmp/kinode-fake-node-2/vfs/chat-with-file-transfer:template.os/files/`, e.g.:
echo 'hello world' > /tmp/kinode-fake-node-2/vfs/chat-with-file-transfer:template.os/files/my_file.txt
# In fake.dev terminal, download the file.
download:chat-with-file-transfer:template.os my_file.txt fake2.dev
# Confirm file was downloaded:
cat /tmp/kinode-fake-node/vfs/chat-with-file-transfer:template.os/files/my_file.txt
APIs Overview
The APIs documented in this section refer to Kinode runtime modules. Specifically, they are the patterns of Requests and Responses that an app can use to interact with these modules.
Note: App developers usually should not use these APIs directly. Most standard use-cases are better served by using functions in the Process Standard Library.
ETH Provider API
Note: Most processes will not use this API directly. Instead, they will use the eth portion of theprocess_lib library, which papers over this API and provides a set of types and functions which are much easier to natively use.
This is mostly useful for re-implementing this module in a different client or performing niche actions unsupported by the library.
Processes can send two kinds of requests to eth:distro:sys: EthAction and EthConfigAction.
The former only requires the capability to message the process, while the latter requires the root capability issued by eth:distro:sys.
Most processes will only need to send EthAction requests.
#![allow(unused)] fn main() { /// The Action and Request type that can be made to eth:distro:sys. Any process with messaging /// capabilities can send this action to the eth provider. /// /// Will be serialized and deserialized using [`serde_json::to_vec`] and [`serde_json::from_slice`]. #[derive(Clone, Debug, Serialize, Deserialize)] pub enum EthAction { /// Subscribe to logs with a custom filter. ID is to be used to unsubscribe. /// Logs come in as JSON value which can be parsed to [`alloy::rpc::types::eth::pubsub::SubscriptionResult`] SubscribeLogs { sub_id: u64, chain_id: u64, kind: SubscriptionKind, params: serde_json::Value, }, /// Kill a SubscribeLogs subscription of a given ID, to stop getting updates. UnsubscribeLogs(u64), /// Raw request. Used by kinode_process_lib. Request { chain_id: u64, method: String, params: serde_json::Value, }, } /// Subscription kind. Pulled directly from alloy (https://github.com/alloy-rs/alloy). /// Why? Because alloy is not yet 1.0 and the types in this interface must be stable. /// If alloy SubscriptionKind changes, we can implement a transition function in runtime /// for this type. #[derive(Clone, Copy, Debug, PartialEq, Eq, Hash, Serialize, Deserialize)] #[serde(deny_unknown_fields)] #[serde(rename_all = "camelCase")] pub enum SubscriptionKind { /// New block headers subscription. /// /// Fires a notification each time a new header is appended to the chain, including chain /// reorganizations. In case of a chain reorganization the subscription will emit all new /// headers for the new chain. Therefore the subscription can emit multiple headers on the same /// height. NewHeads, /// Logs subscription. /// /// Returns logs that are included in new imported blocks and match the given filter criteria. /// In case of a chain reorganization previous sent logs that are on the old chain will be /// resent with the removed property set to true. Logs from transactions that ended up in the /// new chain are emitted. Therefore, a subscription can emit logs for the same transaction /// multiple times. Logs, /// New Pending Transactions subscription. /// /// Returns the hash or full tx for all transactions that are added to the pending state and /// are signed with a key that is available in the node. When a transaction that was /// previously part of the canonical chain isn't part of the new canonical chain after a /// reorganization its again emitted. NewPendingTransactions, /// Node syncing status subscription. /// /// Indicates when the node starts or stops synchronizing. The result can either be a boolean /// indicating that the synchronization has started (true), finished (false) or an object with /// various progress indicators. Syncing, } }
The Request containing this action should always expect a response, since every action variant triggers one and relies on it to be useful.
The ETH provider will respond with the following type:
#![allow(unused)] fn main() { /// The Response body type which a process will get from requesting /// with an [`EthAction`] will be of this type, serialized and deserialized /// using [`serde_json::to_vec`] and [`serde_json::from_slice`]. /// /// In the case of an [`EthAction::SubscribeLogs`] request, the response will indicate if /// the subscription was successfully created or not. #[derive(Debug, Serialize, Deserialize, Clone)] pub enum EthResponse { Ok, Response(serde_json::Value), Err(EthError), } #[derive(Clone, Debug, Serialize, Deserialize)] pub enum EthError { /// RPC provider returned an error. /// Can be parsed to [`alloy::rpc::json_rpc::ErrorPayload`] RpcError(serde_json::Value), /// provider module cannot parse message MalformedRequest, /// No RPC provider for the chain NoRpcForChain, /// Subscription closed SubscriptionClosed(u64), /// Invalid method InvalidMethod(String), /// Invalid parameters InvalidParams, /// Permission denied PermissionDenied, /// RPC timed out RpcTimeout, /// RPC gave garbage back RpcMalformedResponse, } }
The EthAction::SubscribeLogs request will receive a response of EthResponse::Ok if the subscription was successfully created, or EthResponse::Err(EthError) if it was not.
Then, after the subscription is successfully created, the process will receive Requests from eth:distro:sys containing subscription updates.
That request will look like this:
#![allow(unused)] fn main() { /// Incoming `Request` containing subscription updates or errors that processes will receive. /// Can deserialize all incoming requests from eth:distro:sys to this type. /// /// Will be serialized and deserialized using `serde_json::to_vec` and `serde_json::from_slice`. pub type EthSubResult = Result<EthSub, EthSubError>; /// Incoming type for successful subscription updates. #[derive(Clone, Debug, Serialize, Deserialize)] pub struct EthSub { pub id: u64, /// can be parsed to [`alloy::rpc::types::eth::pubsub::SubscriptionResult`] pub result: serde_json::Value, } /// If your subscription is closed unexpectedly, you will receive this. #[derive(Clone, Debug, Serialize, Deserialize)] pub struct EthSubError { pub id: u64, pub error: String, } }
Again, for most processes, this is the entire API.
The eth portion of the process_lib library will handle the serialization and deserialization of these types and provide a set of functions and types that are much easier to use.
Config API
If a process has the root capability from eth:distro:sys, it can send EthConfigAction requests.
These actions are used to adjust the underlying providers and relays used by the module, and its settings regarding acting as a relayer for other nodes (public/private/granular etc).
The configuration of the ETH provider is persisted across two files named .eth_providers and .eth_access_settings in the node's home directory. .eth_access_settings is only created if the configuration is set past the default (private, empty allow/deny lists).
#![allow(unused)] fn main() { /// The action type used for configuring eth:distro:sys. Only processes which have the "root" /// capability from eth:distro:sys can successfully send this action. #[derive(Debug, Serialize, Deserialize)] pub enum EthConfigAction { /// Add a new provider to the list of providers. AddProvider(ProviderConfig), /// Remove a provider from the list of providers. /// The tuple is (chain_id, node_id/rpc_url). RemoveProvider((u64, String)), /// make our provider public SetPublic, /// make our provider not-public SetPrivate, /// add node to whitelist on a provider AllowNode(String), /// remove node from whitelist on a provider UnallowNode(String), /// add node to blacklist on a provider DenyNode(String), /// remove node from blacklist on a provider UndenyNode(String), /// Set the list of providers to a new list. /// Replaces all existing saved provider configs. SetProviders(SavedConfigs), /// Get the list of current providers as a [`SavedConfigs`] object. GetProviders, /// Get the current access settings. GetAccessSettings, /// Get the state of calls and subscriptions. Used for debugging. GetState, } pub type SavedConfigs = HashSet<ProviderConfig>; /// Provider config. Can currently be a node or a ws provider instance. #[derive(Clone, Debug, Deserialize, Serialize, Hash, Eq, PartialEq)] pub struct ProviderConfig { pub chain_id: u64, pub trusted: bool, pub provider: NodeOrRpcUrl, } #[derive(Clone, Debug, Deserialize, Serialize, Hash, Eq, PartialEq)] pub enum NodeOrRpcUrl { Node { kns_update: crate::core::KnsUpdate, use_as_provider: bool, // false for just-routers inside saved config }, RpcUrl(String), } }
EthConfigAction requests should always expect a response. The response body will look like this:
#![allow(unused)] fn main() { /// Response type from an [`EthConfigAction`] request. #[derive(Debug, Serialize, Deserialize)] pub enum EthConfigResponse { Ok, /// Response from a GetProviders request. /// Note the [`crate::core::KnsUpdate`] will only have the correct `name` field. /// The rest of the Update is not saved in this module. Providers(SavedConfigs), /// Response from a GetAccessSettings request. AccessSettings(AccessSettings), /// Permission denied due to missing capability PermissionDenied, /// Response from a GetState request State { active_subscriptions: HashMap<crate::core::Address, HashMap<u64, Option<String>>>, // None if local, Some(node_provider_name) if remote outstanding_requests: HashSet<u64>, }, } /// Settings for our ETH provider #[derive(Clone, Debug, Deserialize, Serialize)] pub struct AccessSettings { pub public: bool, // whether or not other nodes can access through us pub allow: HashSet<String>, // whitelist for access (only used if public == false) pub deny: HashSet<String>, // blacklist for access (always used) } }
A successful GetProviders request will receive a response of EthConfigResponse::Providers(SavedConfigs), and a successful GetAccessSettings request will receive a response of EthConfigResponse::AccessSettings(AccessSettings).
The other requests will receive a response of EthConfigResponse::Ok if they were successful, or EthConfigResponse::PermissionDenied if they were not.
All of these types are serialized to a JSON string via serde_json and stored as bytes in the request/response body.
The source code for this API can be found in the eth section of the Kinode runtime library.
Frontend/UI Development
Kinode can easily serve any webpage or web app developed with normal libraries and frameworks.
There are some specific endpoints, JS libraries, and process_lib functions that are helpful for doing frontend development.
There are also some important considerations and "gotchas" that can happen when trying to do frontend development.
Kinode can serve a website or web app just like any HTTP webserver.
The preferred method is to upload your static assets on install by placing them in the pkg folder.
By convention, kit bundles these assets into a directory inside pkg called ui, but you can call it anything.
You must place your index.html in the top-level folder.
The structure should look like this:
my-package
└── pkg
└── ui (can have any name)
├── assets (can have any name)
└── index.html
/our & /our.js
Every node has both /our and /our.js endpoints.
/our returns the node's ID as a string like 'my-node'.
/our.js returns a JS script that sets window.our = { node: 'my-node' }.
By convention, you can then easily set window.our.process either in your UI code or from a process-specific endpoint.
The frontend would then have window.our set for use in your code.
Serving a Website
The simplest way to serve a UI is using the serve_ui function from process_lib:
serve_ui(&our, "ui", true, false, vec!["/"]).unwrap();
This will serve the index.html in the specified folder (here, "ui") at the home path of your process.
If your process is called my-process:my-package:template.os and your Kinode is running locally on port 8080,
then the UI will be served at http://localhost:8080/my-process:my-package:template.os.
serve_ui takes five arguments: our &Address, the name of the folder that contains your frontend, whether the UI requires authentication, whether the UI is local-only, and the path(s) on which to serve the UI (usually ["/"]).
Development without kit
The kit UI template uses the React framework compiled with Vite.
But you can use any UI framework as long as it generates an index.html and associated assets.
To make development easy, your setup should support a base URL and http proxying.
Base URL
All processes on Kinode are namespaced by process name in the standard format of process:package:publisher.
So if your process is called my-process:my-package:template.os, then your process can only bind HTTP paths that start with /my-process:my-package:template.os.
Your UI should be developed and compiled with the base URL set to the appropriate process path.
Vite
In vite.config.ts (or .js) set base to your full process name, i.e.
base: '/my-process:my-package:template.os'
Create React App
In package.json set homepage to your full process name, i.e.
homepage: '/my-process:my-package:template.os'
Proxying HTTP Requests
In UI development, it is very useful to proxy HTTP requests from the in-dev UI to your Kinode. Below are some examples.
Vite
Follow the server entry in the kit template in your own vite.config.ts.
Create React App
In package.json set proxy to your Kinode's URL, i.e.
proxy: 'http://localhost:8080'
Making HTTP Requests
When making HTTP requests in your UI, make sure to prepend your base URL to the request.
For example, if your base URL is /my-process:my-package:template.os, then a fetch request to /my-endpoint would look like this:
fetch('/my-process:my-package:template.os/my-endpoint')
Local Development and "gotchas"
When developing a frontend locally, particularly with a framework like React, it is helpful to proxy HTTP requests through to your node.
The vite.config.ts provided in the kit template has code to handle this proxying.
It is important to remember that the frontend will always have the process name as the first part of the HTTP path,
so all HTTP requests and file sources should start with the process name.
Many frontend JavaScript frameworks will handle this by default if you set the base or baseUrl properly.
In development, websocket connections can be more annoying to proxy, so it is often easier to simply hardcode the URL if in development.
See your framework documentation for how to check if you are in dev or prod.
The kit template already handles this for you.
Developing against a remote node is simple, you just have to change the proxy target in vite.config.ts to the URL of your node.
By default the template will target http://localhost:8080.
HTTP API
Incoming HTTP requests are handled by a Rust warp server in the core http-server:distro:sys process.
This process handles binding (registering) routes, simple JWT-based authentication, and serving a /login page if auth is missing.
Binding (Registering) HTTP Paths
Any process that you build can bind (register) any number of HTTP paths with http-server.
Every path that you bind will be automatically prepended with the current process' ID.
For example, bind the route /messages within a process called main:my-package:myname.os like so:
#![allow(unused)] fn main() { use kinode_process_lib::{http::bind_http_path}; bind_http_path("/messages", true, false).unwrap(); }
Now, any HTTP requests to your node at /main:my-package:myname.os/messages will be routed to your process.
The other two parameters to bind_http_path are authenticated: bool and local_only: bool.
authenticated means that http-server will check for an auth cookie (set at login/registration), and local_only means that http-server will only allow requests that come from localhost.
Incoming HTTP requests will come via http-server and have both a body and a lazy_load_blob.
The lazy_load_blob is the HTTP request body itself, and the body is an IncomingHttpRequest:
#![allow(unused)] fn main() { pub struct IncomingHttpRequest { /// will parse to SocketAddr pub source_socket_addr: Option<String>, /// will parse to http::Method pub method: String, /// will parse to url::Url pub url: String, /// the matching path that was bound pub bound_path: String, /// will parse to http::HeaderMap pub headers: HashMap<String, String>, pub url_params: HashMap<String, String>, pub query_params: HashMap<String, String>, } }
Note that url is the host and full path of the original HTTP request that came in.
bound_path is the matching path that was originally bound in http-server.
Handling HTTP Requests
Usually, you will want to:
- determine if an incoming request is a HTTP request.
- figure out what kind of
IncomingHttpRequestit is. - handle the request based on the path and method.
Here is an example from the kit UI-enabled chat app template that handles both POST and GET requests to the /messages path:
#![allow(unused)] fn main() { fn handle_http-server_request( our: &Address, message_archive: &mut MessageArchive, source: &Address, body: &[u8], our_channel_id: &mut u32, ) -> anyhow::Result<()> { let Ok(server_request) = serde_json::from_slice::<HttpServerRequest>(body) else { // Fail silently if we can't parse the request return Ok(()); }; match server_request { // IMPORTANT BIT: HttpServerRequest::Http(IncomingHttpRequest { method, url, .. }) => { // Check the path if url.ends_with(&format!("{}{}", our.process.to_string(), "/messages")) { // Match on the HTTP method match method.as_str() { // Get all messages "GET" => { let mut headers = HashMap::new(); headers.insert("Content-Type".to_string(), "application/json".to_string()); send_response( StatusCode::OK, Some(headers), serde_json::to_vec(&ChatResponse::History { messages: message_archive.clone(), }) .unwrap(), )?; } // Send a message "POST" => { print_to_terminal(0, "1"); let Some(blob) = get_blob() else { return Ok(()); }; print_to_terminal(0, "2"); handle_chat_request( our, message_archive, our_channel_id, source, &blob.bytes, true, )?; // Send an http response via the http server send_response(StatusCode::CREATED, None, vec![])?; } _ => { // Method not allowed send_response(StatusCode::METHOD_NOT_ALLOWED, None, vec![])?; } } } } _ => {} }; Ok(()) } }
send_response is a process_lib function that sends an HTTP response. The function signature is as follows:
#![allow(unused)] fn main() { pub fn send_response( status: StatusCode, headers: Option<HashMap<String, String>>, body: Vec<u8>, ) -> anyhow::Result<()> }
App-Specific Authentication
COMING SOON
HTTP Client API
See also: docs.rs for HTTP Client part of process_lib.
Note: Most processes will not use this API directly. Instead, they will use the process_lib library, which papers over this API and provides a set of types and functions which are much easier to natively use. This is mostly useful for re-implementing this module in a different client or performing niche actions unsupported by the library.
The HTTP client is used for sending and receiving HTTP requests and responses.
It is also used for connecting to a websocket endpoint as a client.
From a process, you may send an HttpClientAction to the http-client:distro:sys process.
The action must be serialized to JSON and sent in the body of a request.
HttpClientAction is an enum type that includes both HTTP and websocket actions.
#![allow(unused)] fn main() { /// Request type sent to the `http-client:distro:sys` service. /// /// Always serialized/deserialized as JSON. #[derive(Clone, Debug, Serialize, Deserialize)] pub enum HttpClientAction { Http(OutgoingHttpRequest), WebSocketOpen { url: String, headers: HashMap<String, String>, channel_id: u32, }, WebSocketPush { channel_id: u32, message_type: WsMessageType, }, WebSocketClose { channel_id: u32, }, } }
The websocket actions, WebSocketOpen, WebSocketPush, and WebSocketClose all require a channel_id.
The channel_id is used to identify the connection, and must be unique for each connection from a given process.
Two or more connections can have the same channel_id if they are from different processes.
OutgoingHttpRequest is used to send an HTTP request.
#![allow(unused)] fn main() { /// HTTP Request type that can be shared over Wasm boundary to apps. /// This is the one you send to the `http-client:distro:sys` service. /// /// BODY is stored in the lazy_load_blob, as bytes /// /// TIMEOUT is stored in the message expect_response value #[derive(Clone, Debug, Serialize, Deserialize)] pub struct OutgoingHttpRequest { /// must parse to [`http::Method`] pub method: String, /// must parse to [`http::Version`] pub version: Option<String>, /// must parse to [`url::Url`] pub url: String, pub headers: HashMap<String, String>, } }
All requests to the HTTP client will receive a response of Result<HttpClientResponse, HttpClientError> serialized to JSON.
The process can await or ignore this response, although the desired information will be in the HttpClientResponse if the request was successful.
An HTTP request will have an HttpResponse defined in the http-server module.
A websocket request (open, push, close) will simply respond with a HttpClientResponse::WebSocketAck.
#![allow(unused)] fn main() { /// Response type received from the `http-client:distro:sys` service after /// sending a successful [`HttpClientAction`] to it. #[derive(Debug, Serialize, Deserialize)] pub enum HttpClientResponse { Http(HttpResponse), WebSocketAck, } }
#![allow(unused)] fn main() { #[derive(Error, Debug, Serialize, Deserialize)] pub enum HttpClientError { // HTTP errors #[error("http-client: request is not valid HttpClientRequest: {req}.")] BadRequest { req: String }, #[error("http-client: http method not supported: {method}.")] BadMethod { method: String }, #[error("http-client: url could not be parsed: {url}.")] BadUrl { url: String }, #[error("http-client: http version not supported: {version}.")] BadVersion { version: String }, #[error("http-client: failed to execute request {error}.")] RequestFailed { error: String }, // WebSocket errors #[error("http-client: failed to open connection {url}.")] WsOpenFailed { url: String }, #[error("http-client: failed to send message {req}.")] WsPushFailed { req: String }, #[error("http-client: failed to close connection {channel_id}.")] WsCloseFailed { channel_id: u32 }, } }
The HTTP client can also receive external websocket messages over an active client connection.
These incoming websocket messages are processed and sent as HttpClientRequest to the process that originally opened the websocket.
The message itself is accessible with get_blob().
#![allow(unused)] fn main() { /// Request that comes from an open WebSocket client connection in the /// `http-client:distro:sys` service. Be prepared to receive these after /// using a [`HttpClientAction::WebSocketOpen`] to open a connection. #[derive(Clone, Copy, Debug, Serialize, Deserialize)] pub enum HttpClientRequest { WebSocketPush { channel_id: u32, message_type: WsMessageType, }, WebSocketClose { channel_id: u32, }, } }
HTTP Server API
See also: docs.rs for HTTP Server part of process_lib.
Note: Most processes will not use this API directly. Instead, they will use the process_lib library, which papers over this API and provides a set of types and functions which are much easier to natively use. This is mostly useful for re-implementing this module in a different client or performing niche actions unsupported by the library.
The HTTP server is used by sending and receiving requests and responses.
From a process, you may send an HttpServerAction to the http-server:distro:sys process.
#![allow(unused)] fn main() { /// Request type sent to `http-server:distro:sys` in order to configure it. /// /// If a response is expected, all actions will return a Response /// with the shape `Result<(), HttpServerActionError>` serialized to JSON. #[derive(Clone, Debug, Serialize, Deserialize)] pub enum HttpServerAction { /// Bind expects a lazy_load_blob if and only if `cache` is TRUE. The lazy_load_blob should /// be the static file to serve at this path. Bind { path: String, /// Set whether the HTTP request needs a valid login cookie, AKA, whether /// the user needs to be logged in to access this path. authenticated: bool, /// Set whether requests can be fielded from anywhere, or only the loopback address. local_only: bool, /// Set whether to bind the lazy_load_blob statically to this path. That is, take the /// lazy_load_blob bytes and serve them as the response to any request to this path. cache: bool, }, /// SecureBind expects a lazy_load_blob if and only if `cache` is TRUE. The lazy_load_blob should /// be the static file to serve at this path. /// /// SecureBind is the same as Bind, except that it forces requests to be made from /// the unique subdomain of the process that bound the path. These requests are /// *always* authenticated, and *never* local_only. The purpose of SecureBind is to /// serve elements of an app frontend or API in an exclusive manner, such that other /// apps installed on this node cannot access them. Since the subdomain is unique, it /// will require the user to be logged in separately to the general domain authentication. SecureBind { path: String, /// Set whether to bind the lazy_load_blob statically to this path. That is, take the /// lazy_load_blob bytes and serve them as the response to any request to this path. cache: bool, }, /// Unbind a previously-bound HTTP path Unbind { path: String }, /// Bind a path to receive incoming WebSocket connections. /// Doesn't need a cache since does not serve assets. WebSocketBind { path: String, authenticated: bool, extension: bool, }, /// SecureBind is the same as Bind, except that it forces new connections to be made /// from the unique subdomain of the process that bound the path. These are *always* /// authenticated. Since the subdomain is unique, it will require the user to be /// logged in separately to the general domain authentication. WebSocketSecureBind { path: String, extension: bool }, /// Unbind a previously-bound WebSocket path WebSocketUnbind { path: String }, /// Processes will RECEIVE this kind of request when a client connects to them. /// If a process does not want this websocket open, they should issue a *request* /// containing a [`HttpServerAction::WebSocketClose`] message and this channel ID. WebSocketOpen { path: String, channel_id: u32 }, /// When sent, expects a lazy_load_blob containing the WebSocket message bytes to send. WebSocketPush { channel_id: u32, message_type: WsMessageType, }, /// When sent, expects a `lazy_load_blob` containing the WebSocket message bytes to send. /// Modifies the `lazy_load_blob` by placing into `WebSocketExtPushData` with id taken from /// this `KernelMessage` and `kinode_message_type` set to `desired_reply_type`. WebSocketExtPushOutgoing { channel_id: u32, message_type: WsMessageType, desired_reply_type: MessageType, }, /// For communicating with the ext. /// Kinode's http-server sends this to the ext after receiving `WebSocketExtPushOutgoing`. /// Upon receiving reply with this type from ext, http-server parses, setting: /// * id as given, /// * message type as given (Request or Response), /// * body as HttpServerRequest::WebSocketPush, /// * blob as given. WebSocketExtPushData { id: u64, kinode_message_type: MessageType, blob: Vec<u8>, }, /// Sending will close a socket the process controls. WebSocketClose(u32), } /// The possible message types for [`HttpServerRequest::WebSocketPush`]. /// Ping and Pong are limited to 125 bytes by the WebSockets protocol. /// Text will be sent as a Text frame, with the lazy_load_blob bytes /// being the UTF-8 encoding of the string. Binary will be sent as a /// Binary frame containing the unmodified lazy_load_blob bytes. #[derive(Clone, Copy, Debug, PartialEq, Serialize, Deserialize)] pub enum WsMessageType { Text, Binary, Ping, Pong, Close, } }
This struct must be serialized to JSON and placed in the body of a requests to http-server:distro:sys.
For actions that take additional data, such as Bind and WebSocketPush, it is placed in the lazy_load_blob of that request.
After handling such a request, the HTTP server will always give a response of the shape Result<(), HttpServerError>, also serialized to JSON. This can be ignored, or awaited and handled.
#![allow(unused)] fn main() { /// Part of the Response type issued by `http-server:distro:sys` #[derive(Error, Debug, Serialize, Deserialize)] pub enum HttpServerError { #[error("request could not be parsed to HttpServerAction: {req}.")] BadRequest { req: String }, #[error("action expected blob")] NoBlob, #[error("path binding error: {error}")] PathBindError { error: String }, #[error("WebSocket error: {error}")] WebSocketPushError { error: String }, } }
Certain actions will cause the HTTP server to send requests to the process in the future.
If a process uses Bind or SecureBind, that process will need to field future requests from the HTTP server. The server will handle incoming HTTP protocol messages to that path by sending an HttpServerRequest to the process which performed the binding, and will expect a response that it can then send to the client.
Note: Paths bound using the HTTP server are always prefixed by the ProcessId of the process that bound them.
Note 2: If a process creates a static binding by setting cache to true, the HTTP server will serve whatever bytes were in the accompanying lazy_load_blob to all GET requests on that path.
If a process uses WebSocketBind or WebSocketSecureBind, future WebSocket connections to that path will be sent to the process, which is expected to issue a response that can then be sent to the client.
Bindings can be removed using Unbind and WebSocketUnbind actions.
Note that the HTTP server module will persist bindings until the node itself is restarted (and no later), so unbinding paths is usually not necessary unless cleaning up an old static resource.
The incoming request, whether the binding is for HTTP or WebSocket, will look like this:
#![allow(unused)] fn main() { /// HTTP Request received from the `http-server:distro:sys` service as a /// result of either an HTTP or WebSocket binding, created via [`HttpServerAction`]. #[derive(Clone, Debug, Serialize, Deserialize)] pub enum HttpServerRequest { Http(IncomingHttpRequest), /// Processes will receive this kind of request when a client connects to them. /// If a process does not want this websocket open, they should issue a *request* /// containing a [`HttpServerAction::WebSocketClose`] message and this channel ID. WebSocketOpen { path: String, channel_id: u32, }, /// Processes can both SEND and RECEIVE this kind of request /// (send as [`HttpServerAction::WebSocketPush`]). /// When received, will contain the message bytes as lazy_load_blob. WebSocketPush { channel_id: u32, message_type: WsMessageType, }, /// Receiving will indicate that the client closed the socket. Can be sent to close /// from the server-side, as [`type@HttpServerAction::WebSocketClose`]. WebSocketClose(u32), } /// An HTTP request routed to a process as a result of a binding. /// /// BODY is stored in the lazy_load_blob, as bytes. #[derive(Clone, Debug, Serialize, Deserialize)] pub struct IncomingHttpRequest { /// will parse to SocketAddr pub source_socket_addr: Option<String>, /// will parse to http::Method pub method: String, /// will parse to url::Url pub url: String, /// the matching path that was bound pub bound_path: String, /// will parse to http::HeaderMap pub headers: HashMap<String, String>, pub url_params: HashMap<String, String>, pub query_params: HashMap<String, String>, } }
Processes that use the HTTP server should expect to field this request type, serialized to JSON. The process must issue a response with this structure in the body, serialized to JSON:
#![allow(unused)] fn main() { /// HTTP Response type that can be shared over Wasm boundary to apps. /// Respond to [`IncomingHttpRequest`] with this type. /// /// BODY is stored in the lazy_load_blob, as bytes #[derive(Debug, Serialize, Deserialize)] pub struct HttpResponse { pub status: u16, pub headers: HashMap<String, String>, } }
This response is only required for HTTP requests.
WebSocketOpen, WebSocketPush, and WebSocketClose requests do not require a response.
If a process is meant to send data over an open WebSocket connection, it must issue a HttpServerAction::WebSocketPush request with the appropriate channel_id.
Find discussion of the HttpServerAction::WebSocketExt* requests in the extensions document.
Kernel API
Generally, userspace applications will not have the capability to message the kernel. Those that can, such as the app store, have full control over starting and stopping all userspace processes.
The kernel runtime task accepts one kind of Request:
#![allow(unused)] fn main() { /// IPC format for requests sent to kernel runtime module #[derive(Debug, Serialize, Deserialize)] pub enum KernelCommand { /// RUNTIME ONLY: used to notify the kernel that booting is complete and /// all processes have been loaded in from their persisted or bootstrapped state. Booted, /// Tell the kernel to install and prepare a new process for execution. /// The process will not begin execution until the kernel receives a /// `RunProcess` command with the same `id`. /// /// The process that sends this command will be given messaging capabilities /// for the new process if `public` is false. /// /// All capabilities passed into initial_capabilities must be held by the source /// of this message, or the kernel will discard them (silently for now). InitializeProcess { id: ProcessId, wasm_bytes_handle: String, wit_version: Option<u32>, on_exit: OnExit, initial_capabilities: HashSet<Capability>, public: bool, }, /// Create an arbitrary capability and grant it to a process. GrantCapabilities { target: ProcessId, capabilities: Vec<Capability>, }, /// Drop capabilities. Does nothing if process doesn't have these caps DropCapabilities { target: ProcessId, capabilities: Vec<Capability>, }, /// Tell the kernel to run a process that has already been installed. /// TODO: in the future, this command could be extended to allow for /// resource provision. RunProcess(ProcessId), /// Kill a running process immediately. This may result in the dropping / mishandling of messages! KillProcess(ProcessId), /// RUNTIME ONLY: notify the kernel that the runtime is shutting down and it /// should gracefully stop and persist the running processes. Shutdown, /// Ask kernel to produce debugging information Debug(KernelPrint), } }
All KernelCommands are sent in the body field of a Request, serialized to JSON.
Only InitializeProcess, RunProcess, and KillProcess will give back a Response, also serialized to JSON text bytes using serde_json:
#![allow(unused)] fn main() { #[derive(Debug, Serialize, Deserialize)] pub enum KernelResponse { InitializedProcess, InitializeProcessError, StartedProcess, RunProcessError, KilledProcess(ProcessId), Debug(KernelPrintResponse), } #[derive(Debug, Serialize, Deserialize)] pub enum KernelPrintResponse { ProcessMap(UserspaceProcessMap), Process(Option<UserspacePersistedProcess>), HasCap(Option<bool>), } pub type UserspaceProcessMap = HashMap<ProcessId, UserspacePersistedProcess>; #[derive(Clone, Debug, Serialize, Deserialize)] pub struct UserspacePersistedProcess { pub wasm_bytes_handle: String, pub wit_version: Option<u32>, pub on_exit: OnExit, pub capabilities: HashSet<Capability>, pub public: bool, } }
Booted
Purely for internal use within the kernel. Sent by the kernel, to the kernel, to indicate that all persisted processes have been initialized and are ready to run.
InitializeProcess
The first command used to start a new process.
Generally available to apps via the spawn() function in the WIT interface.
The wasm_bytes_handle is a pointer generated by the filesystem API — it should be a valid .wasm file compiled using the Kinode tooling.
The on_panic field is an enum that specifies what to do if the process panics.
The initial_capabilities field is a set of capabilities that the process will have access to — note that the capabilities are signed by this kernel.
The public field specifies whether the process should be visible to other processes without needing to grant a messaging capability.
InitializeProcess must be sent with a lazy_load_blob.
The blob must be the same .wasm file, in raw bytes, that the wasm_bytes_handle points to.
This will not cause the process to begin running.
To do that, send a RunProcess command after a successful InitializeProcess command.
GrantCapabilities
This command directly inserts a list of capabilities into another process' state.
While you generally don't want to do this for security reasons, it helps you clean up the "handshake" process by which capabilities must be handed off between two processes before engaging in the business logic.
For instance, if you want a kernel module like http-server to be able to message a process back, you do this by directly inserting that "messaging" cap into http-server's store.
Only the app-store, terminal, and tester make use of this.
DropCapabilities
This command removes a list of capabilities from another process' state. Currently, no app makes use of this, as it is very powerful.
RunProcess
Takes a process ID and tells kernel to call the init function.
The process must have first been initialized with a successful InitializeProcess.
KillProcess
Takes a process ID and kills it. This is a dangerous operation as messages queued for the process will be lost. The process will be removed from the kernel's process table and will no longer be able to receive messages.
Shutdown
Send to the kernel in order to gracefully shut down the system. The runtime must perform this request before exiting in order to see that all processes are properly cleaned up.
kinode.wit
Throughout this book, readers will see references to WIT, the WebAssembly Component Model. WIT, or Wasm Interface Type, is a language for describing the types and functions that are available to a WebAssembly module. In conjunction with the Component Model itself, WIT allows for the creation of WebAssembly modules that can be used as components in a larger system. This standard has been under development for many years, and while still under construction, it's the perfect tool for building an operating-system-like environment for Wasm apps.
Kinode uses WIT to present a standard interface for Kinode processes.
This interface is a set of types and functions that are available to all processes.
It also contains functions (well, just a single function: init()) that processes must implement in order to compile and run on Kinode.
If one can generate WIT bindings in a language that compiles to Wasm, that language can be used to write Kinode processes.
So far, we've written Kinode processes in Rust, Javascript, Go, and Python.
To see exactly how to use WIT to write Kinode processes, see the My First App chapter or the Chess Tutorial.
To see kinode.wit for itself, see the file in the GitHub repo.
Since this interface applies to all processes, it's one of the places in the OS where breaking changes are most likely to make an impact.
To that end, the version of the WIT file that a process uses must be compatible with the version of Kinode on which it runs.
Kinode intends to achieve perfect backwards compatibility upon first major release (1.0.0) of the OS and the WIT file.
After that point, since processes signal the version of the WIT file they use, subsequent updates can be made without breaking existing processes or needing to change the version they use.
Types
These 15 types make up the entirety of the shared type system between processes and the kernel. Most types presented here are implemented in the process standard library for ease of use.
Functions
These 16 functions are available to processes. They are implemented in the kernel. Again, the process standard library makes it such that these functions often don't need to be directly called in processes, but they are always available. The functions are generally separated into 4 categories: system utilities, process management, capabilities management, and message I/O. Future versions of the WIT file will certainly add more functions, but the categories themselves are highly unlikely to change.
System utilities are functions like print_to_terminal, whose role is to provide a way for processes to interact with the runtime in an idiosyncratic way.
Process management functions are used to adjust a processes' state in the kernel. This includes its state-store and its on-exit behavior. This category is also responsible for functions that give processes the ability to spawn and manage child processes.
Capabilities management functions relate to the capabilities-based security system imposed by the kernel on processes. Processes must acquire and manage capabilities in order to perform tasks external to themselves, such as messaging another process or writing to a file. See the capabilities overview for more details.
Lastly, message I/O functions are used to send and receive messages between processes.
Message-passing is the primary means by which processes communicate not only with themselves, but also with runtime modules which expose all kinds of I/O abilities.
For example, handling an HTTP request involves sending and receiving messages to and from the http-server:disto:sys runtime module.
Interacting with this module and others occurs through message I/O.
KV API
Useful helper functions can be found in the kinode_process_lib.
More discussion of databases in Kinode can be found here.
Creating/Opening a database
#![allow(unused)] fn main() { use kinode_process_lib::kv; let kv = kv::open(our.package_id(), "birthdays")?; // You can now pass this KV struct as a reference to other functions }
Set
#![allow(unused)] fn main() { let key = b"hello"; let value= b"world"; let returnvalue = kv.set(&key, &value, None)?; // The third argument None is for tx_id. // You can group sets and deletes and commit them later. }
Get
#![allow(unused)] fn main() { let key = b"hello"; let returnvalue = kv.get(&key)?; }
Delete
#![allow(unused)] fn main() { let key = b"hello"; kv.delete(&key, None)?; }
Transactions
#![allow(unused)] fn main() { let tx_id = kv.begin_tx()?; let key = b"hello"; let key2 = b"deleteme"; let value= b"value"; kv.set(&key, &value, Some(tx_id))?; kv.delete(&key, Some(tx_id))?; kv.commit_tx(tx_id)?; }
API
#![allow(unused)] fn main() { /// Actions are sent to a specific key value database. `db` is the name, /// `package_id` is the [`PackageId`] that created the database. Capabilities /// are checked: you can access another process's database if it has given /// you the read and/or write capability to do so. #[derive(Clone, Debug, Serialize, Deserialize)] pub struct KvRequest { pub package_id: PackageId, pub db: String, pub action: KvAction, } /// IPC Action format representing operations that can be performed on the /// key-value runtime module. These actions are included in a [`KvRequest`] /// sent to the `kv:distro:sys` runtime module. #[derive(Clone, Debug, Serialize, Deserialize)] pub enum KvAction { /// Opens an existing key-value database or creates a new one if it doesn't exist. /// Requires `package_id` in [`KvRequest`] to match the package ID of the sender. /// The sender will own the database and can remove it with [`KvAction::RemoveDb`]. /// /// A successful open will respond with [`KvResponse::Ok`]. Any error will be /// contained in the [`KvResponse::Err`] variant. Open, /// Permanently deletes the entire key-value database. /// Requires `package_id` in [`KvRequest`] to match the package ID of the sender. /// Only the owner can remove the database. /// /// A successful remove will respond with [`KvResponse::Ok`]. Any error will be /// contained in the [`KvResponse::Err`] variant. RemoveDb, /// Sets a value for the specified key in the database. /// /// # Parameters /// * `key` - The key as a byte vector /// * `tx_id` - Optional transaction ID if this operation is part of a transaction /// * blob: [`Vec<u8>`] - Byte vector to store for the key /// /// Using this action requires the sender to have the write capability /// for the database. /// /// A successful set will respond with [`KvResponse::Ok`]. Any error will be /// contained in the [`KvResponse::Err`] variant. Set { key: Vec<u8>, tx_id: Option<u64> }, /// Deletes a key-value pair from the database. /// /// # Parameters /// * `key` - The key to delete as a byte vector /// * `tx_id` - Optional transaction ID if this operation is part of a transaction /// /// Using this action requires the sender to have the write capability /// for the database. /// /// A successful delete will respond with [`KvResponse::Ok`]. Any error will be /// contained in the [`KvResponse::Err`] variant. Delete { key: Vec<u8>, tx_id: Option<u64> }, /// Retrieves the value associated with the specified key. /// /// # Parameters /// * The key to look up as a byte vector /// /// Using this action requires the sender to have the read capability /// for the database. /// /// A successful get will respond with [`KvResponse::Get`], where the response blob /// contains the value associated with the key if any. Any error will be /// contained in the [`KvResponse::Err`] variant. Get(Vec<u8>), /// Begins a new transaction for atomic operations. /// /// Sending this will prompt a [`KvResponse::BeginTx`] response with the /// transaction ID. Any error will be contained in the [`KvResponse::Err`] variant. BeginTx, /// Commits all operations in the specified transaction. /// /// # Parameters /// * `tx_id` - The ID of the transaction to commit /// /// A successful commit will respond with [`KvResponse::Ok`]. Any error will be /// contained in the [`KvResponse::Err`] variant. Commit { tx_id: u64 }, } #[derive(Clone, Debug, Serialize, Deserialize)] pub enum KvResponse { /// Indicates successful completion of an operation. /// Sent in response to actions Open, RemoveDb, Set, Delete, and Commit. Ok, /// Returns the transaction ID for a newly created transaction. /// /// # Fields /// * `tx_id` - The ID of the newly created transaction BeginTx { tx_id: u64 }, /// Returns the value for the key that was retrieved from the database. /// /// # Parameters /// * The retrieved key as a byte vector /// * blob: [`Vec<u8>`] - Byte vector associated with the key Get(Vec<u8>), /// Indicates an error occurred during the operation. Err(KvError), } #[derive(Clone, Debug, Serialize, Deserialize, Error)] pub enum KvError { #[error("db [{0}, {1}] does not exist")] NoDb(PackageId, String), #[error("key not found")] KeyNotFound, #[error("no transaction {0} found")] NoTx(u64), #[error("no write capability for requested DB")] NoWriteCap, #[error("no read capability for requested DB")] NoReadCap, #[error("request to open or remove DB with mismatching package ID")] MismatchingPackageId, #[error("failed to generate capability for new DB")] AddCapFailed, #[error("kv got a malformed request that either failed to deserialize or was missing a required blob")] MalformedRequest, #[error("RocksDB internal error: {0}")] RocksDBError(String), #[error("IO error: {0}")] IOError(String), } /// The JSON parameters contained in all capabilities issued by `kv:distro:sys`. /// /// # Fields /// * `kind` - The kind of capability, either [`KvCapabilityKind::Read`] or [`KvCapabilityKind::Write`] /// * `db_key` - The database key, a tuple of the [`PackageId`] that created the database and the database name #[derive(Clone, Debug, Serialize, Deserialize)] pub struct KvCapabilityParams { pub kind: KvCapabilityKind, pub db_key: (PackageId, String), } #[derive(Clone, Debug, Serialize, Deserialize)] #[serde(rename_all = "lowercase")] pub enum KvCapabilityKind { Read, Write, } }
Net API
Most processes will not use this API directly. Instead, processes will make use of the networking protocol simply by sending messages to processes running on other nodes. This API is documented, rather, for those who wish to implement their own networking protocol.
The networking API is implemented in the net:distro:sys process.
For the specific networking protocol, see the networking protocol chapter.
This chapter is rather to describe the message-based API that the net:distro:sys process exposes.
Net, like all processes and runtime modules, is architected around a main message-receiving loop.
The received Requests are handled in one of three ways:
-
If the
target.nodeis "our domain", i.e. the domain name of the local node, and thesource.nodeis also our domain, the message is parsed and treated as either a debugging command or one of theNetActionsenum. -
If the
target.nodeis our domain, but thesource.nodeis not, the message is either parsed as theNetActionsenum, or if it fails to parse, is treated as a "hello" message and printed in the terminal, size permitting. This "hello" protocol simply attempts to display themessage.bodyas a UTF-8 string and is mostly used for network debugging. -
If the
source.nodeis our domain, but thetarget.nodeis not, the message is sent to the target using the networking protocol implementation.
Let's look at NetActions. Note that this message type can be received from remote or local processes.
Different implementations of the networking protocol may reject actions depending on whether they were instigated locally or remotely, and also discriminate on which remote node sent the action.
This is, for example, where a router would choose whether or not to perform routing for a specific node<>node connection.
#![allow(unused)] fn main() { /// Must be parsed from message pack vector. /// all Get actions must be sent from local process. used for debugging #[derive(Clone, Debug, Serialize, Deserialize)] pub enum NetAction { /// Received from a router of ours when they have a new pending passthrough for us. /// We should respond (if we desire) by using them to initialize a routed connection /// with the NodeId given. ConnectionRequest(NodeId), /// can only receive from trusted source: requires net root cap KnsUpdate(KnsUpdate), /// can only receive from trusted source: requires net root cap KnsBatchUpdate(Vec<KnsUpdate>), /// get a list of peers we are connected to GetPeers, /// get the [`Identity`] struct for a single peer GetPeer(String), /// get a user-readable diagnostics string containing networking inforamtion GetDiagnostics, /// sign the attached blob payload, sign with our node's networking key. /// **only accepted from our own node** /// **the source [`Address`] will always be prepended to the payload** Sign, /// given a message in blob payload, verify the message is signed by /// the given source. if the signer is not in our representation of /// the PKI, will not verify. /// **the `from` [`Address`] will always be prepended to the payload** Verify { from: Address, signature: Vec<u8> }, } #[derive(Clone, Debug, Serialize, Deserialize, Hash, Eq, PartialEq)] pub struct KnsUpdate { pub name: String, pub public_key: String, pub ips: Vec<String>, pub ports: BTreeMap<String, u16>, pub routers: Vec<String>, } }
This type must be parsed from a request body using MessagePack.
ConnectionRequest is sent by remote nodes as part of the WebSockets networking protocol in order to ask a router to connect them to a node that they can't connect to directly.
This is responded to with either an Accepted or Rejected variant of NetResponses.
KnsUpdate and KnsBatchUpdate both are used as entry point by which the net module becomes aware of the Kinode PKI, or KNS.
In the current distro these are only accepted from the local node, and specifically the kns-indexer distro package.
GetPeers is used to request a list of peers that the net module is connected to. It can only be received from the local node.
GetPeer is used to request the Identity struct for a single peer. It can only be received from the local node.
GetName is used to request the NodeId associated with a given namehash. It can only be received from the local node.
GetDiagnostics is used to request a user-readable diagnostics string containing networking information. It can only be received from the local node.
Sign is used to request that the attached blob payload be signed with our node's networking key. It can only be received from the local node.
Verify is used to request that the attached blob payload be verified as being signed by the given source. It can only be received from the local node.
Finally, let's look at the type parsed from a Response.
#![allow(unused)] fn main() { /// Must be parsed from message pack vector #[derive(Clone, Debug, Serialize, Deserialize)] pub enum NetResponse { /// response to [`NetAction::ConnectionRequest`] Accepted(NodeId), /// response to [`NetAction::ConnectionRequest`] Rejected(NodeId), /// response to [`NetAction::GetPeers`] Peers(Vec<Identity>), /// response to [`NetAction::GetPeer`] Peer(Option<Identity>), /// response to [`NetAction::GetDiagnostics`]. a user-readable string. Diagnostics(String), /// response to [`NetAction::Sign`]. contains the signature in blob Signed, /// response to [`NetAction::Verify`]. boolean indicates whether /// the signature was valid or not. note that if the signer node /// cannot be found in our representation of PKI, this will return false, /// because we cannot find the networking public key to verify with. Verified(bool), } }
This type must be also be parsed using MessagePack, this time from responses received by net.
In the future, NetActions and NetResponses may both expand to cover message types required for implementing networking protocols other than the WebSockets one.
SQLite API
Useful helper functions can be found in the kinode_process_lib.
More discussion of databases in Kinode can be found here.
Creating/Opening a database
#![allow(unused)] fn main() { use kinode_process_lib::sqlite; let db = sqlite::open(our.package_id(), "users")?; // You can now pass this SQLite struct as a reference to other functions }
Write
#![allow(unused)] fn main() { let statement = "INSERT INTO users (name) VALUES (?), (?), (?);".to_string(); let params = vec![ serde_json::Value::String("Bob".to_string()), serde_json::Value::String("Charlie".to_string()), serde_json::Value::String("Dave".to_string()), ]; sqlite.write(statement, params, None)?; }
Read
#![allow(unused)] fn main() { let query = "SELECT FROM users;".to_string(); let rows = sqlite.read(query, vec![])?; // rows: Vec<HashMap<String, serde_json::Value>> println!("rows: {}", rows.len()); for row in rows { println!(row.get("name")); } }
Transactions
#![allow(unused)] fn main() { let tx_id = sqlite.begin_tx()?; let statement = "INSERT INTO users (name) VALUES (?);".to_string(); let params = vec![serde_json::Value::String("Eve".to_string())]; let params2 = vec![serde_json::Value::String("Steve".to_string())]; sqlite.write(statement, params, Some(tx_id))?; sqlite.write(statement, params2, Some(tx_id))?; sqlite.commit_tx(tx_id)?; }
API
#![allow(unused)] fn main() { /// Actions are sent to a specific SQLite database. `db` is the name, /// `package_id` is the [`PackageId`] that created the database. Capabilities /// are checked: you can access another process's database if it has given /// you the read and/or write capability to do so. #[derive(Clone, Debug, Serialize, Deserialize)] pub struct SqliteRequest { pub package_id: PackageId, pub db: String, pub action: SqliteAction, } /// IPC Action format representing operations that can be performed on the /// SQLite runtime module. These actions are included in a [`SqliteRequest`] /// sent to the `sqlite:distro:sys` runtime module. #[derive(Clone, Debug, Serialize, Deserialize)] pub enum SqliteAction { /// Opens an existing key-value database or creates a new one if it doesn't exist. /// Requires `package_id` in [`SqliteRequest`] to match the package ID of the sender. /// The sender will own the database and can remove it with [`SqliteAction::RemoveDb`]. /// /// A successful open will respond with [`SqliteResponse::Ok`]. Any error will be /// contained in the [`SqliteResponse::Err`] variant. Open, /// Permanently deletes the entire key-value database. /// Requires `package_id` in [`SqliteRequest`] to match the package ID of the sender. /// Only the owner can remove the database. /// /// A successful remove will respond with [`SqliteResponse::Ok`]. Any error will be /// contained in the [`SqliteResponse::Err`] variant. RemoveDb, /// Executes a write statement (INSERT/UPDATE/DELETE) /// /// * `statement` - SQL statement to execute /// * `tx_id` - Optional transaction ID /// * blob: Vec<SqlValue> - Parameters for the SQL statement, where SqlValue can be: /// - null /// - boolean /// - i64 /// - f64 /// - String /// - Vec<u8> (binary data) /// /// Using this action requires the sender to have the write capability /// for the database. /// /// A successful write will respond with [`SqliteResponse::Ok`]. Any error will be /// contained in the [`SqliteResponse::Err`] variant. Write { statement: String, tx_id: Option<u64>, }, /// Executes a read query (SELECT) /// /// * blob: Vec<SqlValue> - Parameters for the SQL query, where SqlValue can be: /// - null /// - boolean /// - i64 /// - f64 /// - String /// - Vec<u8> (binary data) /// /// Using this action requires the sender to have the read capability /// for the database. /// /// A successful query will respond with [`SqliteResponse::Query`], where the /// response blob contains the results of the query. Any error will be contained /// in the [`SqliteResponse::Err`] variant. Query(String), /// Begins a new transaction for atomic operations. /// /// Sending this will prompt a [`SqliteResponse::BeginTx`] response with the /// transaction ID. Any error will be contained in the [`SqliteResponse::Err`] variant. BeginTx, /// Commits all operations in the specified transaction. /// /// # Parameters /// * `tx_id` - The ID of the transaction to commit /// /// A successful commit will respond with [`SqliteResponse::Ok`]. Any error will be /// contained in the [`SqliteResponse::Err`] variant. Commit { tx_id: u64 }, } #[derive(Clone, Debug, Serialize, Deserialize)] pub enum SqliteResponse { /// Indicates successful completion of an operation. /// Sent in response to actions Open, RemoveDb, Write, Query, BeginTx, and Commit. Ok, /// Returns the results of a query. /// /// * blob: Vec<Vec<SqlValue>> - Array of rows, where each row contains SqlValue types: /// - null /// - boolean /// - i64 /// - f64 /// - String /// - Vec<u8> (binary data) Read, /// Returns the transaction ID for a newly created transaction. /// /// # Fields /// * `tx_id` - The ID of the newly created transaction BeginTx { tx_id: u64 }, /// Indicates an error occurred during the operation. Err(SqliteError), } /// Used in blobs to represent array row values in SQLite. #[derive(Clone, Debug, Serialize, Deserialize, PartialEq)] pub enum SqlValue { Integer(i64), Real(f64), Text(String), Blob(Vec<u8>), Boolean(bool), Null, } #[derive(Clone, Debug, Serialize, Deserialize, Error)] pub enum SqliteError { #[error("db [{0}, {1}] does not exist")] NoDb(PackageId, String), #[error("no transaction {0} found")] NoTx(u64), #[error("no write capability for requested DB")] NoWriteCap, #[error("no read capability for requested DB")] NoReadCap, #[error("request to open or remove DB with mismatching package ID")] MismatchingPackageId, #[error("failed to generate capability for new DB")] AddCapFailed, #[error("write statement started with non-existent write keyword")] NotAWriteKeyword, #[error("read query started with non-existent read keyword")] NotAReadKeyword, #[error("parameters blob in read/write was misshapen or contained invalid JSON objects")] InvalidParameters, #[error("sqlite got a malformed request that failed to deserialize")] MalformedRequest, #[error("rusqlite error: {0}")] RusqliteError(String), #[error("IO error: {0}")] IOError(String), } /// The JSON parameters contained in all capabilities issued by `sqlite:distro:sys`. /// /// # Fields /// * `kind` - The kind of capability, either [`SqliteCapabilityKind::Read`] or [`SqliteCapabilityKind::Write`] /// * `db_key` - The database key, a tuple of the [`PackageId`] that created the database and the database name #[derive(Clone, Debug, Serialize, Deserialize)] pub struct SqliteCapabilityParams { pub kind: SqliteCapabilityKind, pub db_key: (PackageId, String), } #[derive(Clone, Debug, Serialize, Deserialize)] #[serde(rename_all = "lowercase")] pub enum SqliteCapabilityKind { Read, Write, } }
Terminal API
It is extremely rare for an app to have direct access to the terminal api. Normally, the terminal will be used to call scripts, which will have access to the process in question. For documentation on using, writing, publishing, and composing scripts, see the terminal use documentation, or for a quick start, the script cookbook.
The Kinode terminal is broken up into two segments: a Wasm app, called terminal:terminal:sys, and a runtime module called terminal:distro:sys.
The Wasm app is the central area where terminal logic and authority live.
It parses Requests by attempting to read the body field as a UTF-8 string, then parsing that string into various commands to perform.
The runtime module exists in order to actually use this app from the terminal which is launched by starting Kinode.
It manages the raw input and presents an interface with features such as command history, text manipulation, and shortcuts.
To "use" the terminal as an API, one simply needs the capability to message terminal:terminal:sys.
This is a powerful capability, equivalent to giving an application root authority over your node.
For this reason, users are unlikely to grant direct terminal access to most apps.
If one does have the capability to send Requests to the terminal, they can execute commands like so:
script-name:package-name:publisher-name <ARGS>
For example, the hi script, which pings another node's terminal with a message, can be called like so:
hi:terminal:sys default-router-1.os what's up?
In this case, the arguments are both default-router-1.os and the message what's up?.
Some commonly used scripts have shorthand aliases because they are invoked so frequently.
For example, hi:terminal:sys can be shortened to just hi as in:
hi default-router-1.os what's up?
The other most commonly used script is m:terminal:sys, or just m - which stands for Message.
m lets you send a request to any node or application like so:
m some-node.os@proc:pkg:pub '{"foo":"bar"}'
Note that if your process has the ability to message the terminal app, then that process can call any script.
However, they will all have this standard calling convention of <script-name> <ARGS>.
Timer API
The Timer API allows processes to manage time-based operations within Kinode.
This API provides a simple yet powerful mechanism for scheduling actions to be executed after a specified delay.
The entire API is just the TimerAction:
#![allow(unused)] fn main() { pub enum TimerAction { Debug, SetTimer(u64), } }
This defines just two actions: Debug and SetTimer
Debug
This action will print information about all active timers to the terminal.
SetTimer
This lets you set a timer to pop after a set number of milliseconds, so e.g. {"SetTimer": 1000} would pop after one second.
The timer finishes by sending a Response once the timer has popped.
The response will have no information in the body.
To keep track of different timers, you can use two methods:
send_and_await_responsewhich will block your app while it is waiting- use
kinode_process_lib::timer::set_and_await_timerfor this
- use
- use
contextto keep track of multiple timers without blocking- use
kinode_process_lib::timer::set_timerto set the timer with optional context
- use
VFS API
Useful helper functions can be found in the kinode_process_lib
The VFS API tries to map over the std::fs calls as directly as possible.
Every request takes a path and a corresponding action.
Drives
A drive is a directory within a package's VFS directory, e.g., app-store:sys/pkg/ or your_package:publisher.os/my_drive/.
Drives are owned by packages.
Packages can share access to drives they own via capabilities.
Each package is spawned with two drives: pkg/ and tmp/.
All processes in a package have caps to those drives.
Processes can also create additional drives.
pkg/ drive
The pkg/ drive contains metadata about the package that Kinode requires to run that package, .wasm binaries, and optionally the API of the package and the UI.
When creating packages, the pkg/ drive is populated by kit build and loaded into the Kinode using kit start-package.
tmp/ drive
The tmp/ drive can be written to directly by the owning package using standard filesystem functionality (i.e. std::fs in Rust) via WASI in addition to the Kinode VFS.
Imports
#![allow(unused)] fn main() { use kinode_process_lib::vfs::{ create_drive, open_file, open_dir, create_file, metadata, File, Directory, }; }
Opening/Creating a Drive
#![allow(unused)] fn main() { let drive_path: String = create_drive(our.package_id(), "drive_name")?; // you can now prepend this path to any files/directories you're interacting with let file = open_file(&format!("{}/hello.txt", &drive_path), true); }
Sharing a Drive Capability
#![allow(unused)] fn main() { let vfs_read_cap = serde_json::json!({ "kind": "read", "drive": drive_path, }).to_string(); let vfs_address = Address { node: our.node.clone(), process: ProcessId::from_str("vfs:distro:sys").unwrap(), }; // get this capability from our store let cap = get_capability(&vfs_address, &vfs_read_cap); // now if we have that Capability, we can attach it to a subsequent message. if let Some(cap) = cap { Request::new() .capabilities(vec![cap]) .body(b"hello".to_vec()) .send()?; } }
#![allow(unused)] fn main() { // the receiving process can then save the capability to it's store, and open the drive. save_capabilities(incoming_request.capabilities); let dir = open_dir(&drive_path, false)?; }
Files
Open a File
#![allow(unused)] fn main() { /// Opens a file at path, if no file at path, creates one if boolean create is true. let file_path = format!("{}/hello.txt", &drive_path); let file = open_file(&file_path, true); }
Create a File
#![allow(unused)] fn main() { /// Creates a file at path, if file found at path, truncates it to 0. let file_path = format!("{}/hello.txt", &drive_path); let file = create_file(&file_path); }
Read a File
#![allow(unused)] fn main() { /// Reads the entire file, from start position. /// Returns a vector of bytes. let contents = file.read()?; }
Write a File
#![allow(unused)] fn main() { /// Write entire slice as the new file. /// Truncates anything that existed at path before. let buffer = b"Hello!"; file.write(&buffer)?; }
Write to File
#![allow(unused)] fn main() { /// Write buffer to file at current position, overwriting any existing data. let buffer = b"World!"; file.write_all(&buffer)?; }
Read at position
#![allow(unused)] fn main() { /// Read into buffer from current cursor position /// Returns the amount of bytes read. let mut buffer = vec![0; 5]; file.read_at(&buffer)?; }
Set Length
#![allow(unused)] fn main() { /// Set file length, if given size > underlying file, fills it with 0s. file.set_len(42)?; }
Seek to a position
#![allow(unused)] fn main() { /// Seek file to position. /// Returns the new position. let position = SeekFrom::End(0); file.seek(&position)?; }
Sync
#![allow(unused)] fn main() { /// Syncs path file buffers to disk. file.sync_all()?; }
Metadata
#![allow(unused)] fn main() { /// Metadata of a path, returns file type and length. let metadata = file.metadata()?; }
Directories
Open a Directory
#![allow(unused)] fn main() { /// Opens or creates a directory at path. /// If trying to create an existing file, will just give you the path. let dir_path = format!("{}/my_pics", &drive_path); let dir = open_dir(&dir_path, true); }
Read a Directory
#![allow(unused)] fn main() { /// Iterates through children of directory, returning a vector of DirEntries. /// DirEntries contain the path and file type of each child. let entries = dir.read()?; }
General path Metadata
#![allow(unused)] fn main() { /// Metadata of a path, returns file type and length. let some_path = format!("{}/test", &drive_path); let metadata = metadata(&some_path)?; }
API
#![allow(unused)] fn main() { /// IPC Request format for the vfs:distro:sys runtime module. #[derive(Debug, Serialize, Deserialize)] pub struct VfsRequest { pub path: String, pub action: VfsAction, } #[derive(Debug, Serialize, Deserialize, PartialEq)] pub enum VfsAction { CreateDrive, CreateDir, CreateDirAll, CreateFile, OpenFile { create: bool }, CloseFile, Write, WriteAll, Append, SyncAll, Read, ReadDir, ReadToEnd, ReadExact { length: u64 }, ReadToString, Seek(SeekFrom), RemoveFile, RemoveDir, RemoveDirAll, Rename { new_path: String }, Metadata, AddZip, CopyFile { new_path: String }, Len, SetLen(u64), Hash, } #[derive(Debug, Serialize, Deserialize, PartialEq)] pub enum SeekFrom { Start(u64), End(i64), Current(i64), } #[derive(Debug, Serialize, Deserialize)] pub enum FileType { File, Directory, Symlink, Other, } #[derive(Debug, Serialize, Deserialize)] pub struct FileMetadata { pub file_type: FileType, pub len: u64, } #[derive(Debug, Serialize, Deserialize)] pub struct DirEntry { pub path: String, pub file_type: FileType, } #[derive(Debug, Serialize, Deserialize)] pub enum VfsResponse { Ok, Err(VfsError), Read, SeekFrom { new_offset: u64 }, ReadDir(Vec<DirEntry>), ReadToString(String), Metadata(FileMetadata), Len(u64), Hash([u8; 32]), } #[derive(Error, Debug, Serialize, Deserialize)] pub enum VfsError { #[error("No capability for action {action} at path {path}")] NoCap { action: String, path: String }, #[error("Bytes blob required for {action} at path {path}")] BadBytes { action: String, path: String }, #[error("bad request error: {error}")] BadRequest { error: String }, #[error("error parsing path: {path}: {error}")] ParseError { error: String, path: String }, #[error("IO error: {error}, at path {path}")] IOError { error: String, path: String }, #[error("kernel capability channel error: {error}")] CapChannelFail { error: String }, #[error("Bad JSON blob: {error}")] BadJson { error: String }, #[error("File not found at path {path}")] NotFound { path: String }, #[error("Creating directory failed at path: {path}: {error}")] CreateDirError { path: String, error: String }, #[error("Other error: {error}")] Other { error: String }, } }
WebSocket API
WebSocket connections are made with a Rust warp server in the core http-server:distro:sys process.
Each connection is assigned a channel_id that can be bound to a given process using a WsRegister message.
The process receives the channel_id for pushing data into the WebSocket, and any subsequent messages from that client will be forwarded to the bound process.
Opening a WebSocket Channel from a Client
To open a WebSocket channel, connect to the main route on the node / and send a WsRegister message as either text or bytes.
The simplest way to connect from a browser is to use the @kinode/client-api like so:
const api = new KinodeEncryptorApi({
nodeId: window.our.node, // this is set if the /our.js script is present in index.html
processId: "my-package:my-package:template.os",
onOpen: (_event, api) => {
console.log('Connected to Kinode')
// Send a message to the node via WebSocket
api.send({ data: 'Hello World' })
},
})
@kinode/client-api is available here: https://www.npmjs.com/package/@kinode/client-api
Simple JavaScript/JSON example:
function getCookie(name) {
const cookies = document.cookie.split(';');
for (let i = 0; i < cookies.length; i++) {
const cookie = cookies[i].trim();
if (cookie.startsWith(name)) {
return cookie.substring(name.length + 1);
}
}
}
const websocket = new WebSocket("http://localhost:8080/");
const message = JSON.stringify({
"auth_token": getCookie(`kinode-auth_${nodeId}`),
"target_process": "my-package:my-package:template.os",
"encrypted": false,
});
websocket.send(message);
Handling Incoming WebSocket Messages
Incoming WebSocket messages will be enums of HttpServerRequest with type WebSocketOpen, WebSocketPush, or WebSocketClose.
You will want to store the channel_id that comes in with WebSocketOpen so that you can push data to that WebSocket.
If you expect to have more than one client connected at a time, then you will most likely want to store the channel IDs in a Set (Rust HashSet).
With a WebSocketPush, the incoming message will be on the LazyLoadBlob, accessible with get_blob().
WebSocketClose will have the channel_id of the closed channel, so that you can remove it from wherever you are storing it.
A full example:
fn handle_http-server_request(
our: &Address,
message_archive: &mut MessageArchive,
source: &Address,
body: &[u8],
channel_ids: &mut HashSet,
) -> anyhow::Result<()> {
let Ok(server_request) = serde_json::from_slice::<HttpServerRequest>(body) else {
// Fail silently if we can't parse the request
return Ok(());
};
match server_request {
HttpServerRequest::WebSocketOpen { channel_id, .. } => {
// Set our channel_id to the newly opened channel
// Note: this code could be improved to support multiple channels
channel_ids.insert(channel_id);
}
HttpServerRequest::WebSocketPush { .. } => {
let Some(blob) = get_blob() else {
return Ok(());
};
handle_chat_request(
our,
message_archive,
our_channel_id,
source,
&blob.bytes,
false,
)?;
}
HttpServerRequest::WebSocketClose(_channel_id) => {
channel_ids.remove(channel_id);
}
HttpServerRequest::Http(IncomingHttpRequest { method, url, bound_path, .. }) => {
// Handle incoming HTTP requests here
}
};
Ok(())
}
Pushing Data to a Client via WebSocket
Pushing data to a connected WebSocket is very simple. Call the send_ws_push function from process_lib:
pub fn send_ws_push(
node: String,
channel_id: u32,
message_type: WsMessageType,
blob: LazyLoadBlob,
) -> anyhow::Result<()>
node will usually be our.node (although you can also send a WS push to another node's http-server!), channel_id is the client you want to send to, message_type will be either WsMessageType::Text or WsMessageType::Binary, and blob will be a standard LazyLoadBlob with an optional mime field and required bytes field.
If you would prefer to send the request without the helper function, this is that what send_ws_push looks like under the hood:
Request::new()
.target(Address::new(
node,
ProcessId::from_str("http-server:distro:sys").unwrap(),
))
.body(
serde_json::json!(HttpServerRequest::WebSocketPush {
channel_id,
message_type,
})
.to_string()
.as_bytes()
.to_vec(),
)
.blob(blob)
.send()?;
Hosted Nodes User Guide
Sybil Technologies runs a Kinode hosting service for users who do not want to run a node themselves. These hosted Kinodes are useful for both end users and developers. This guide is largely targeted at developers who want to develop Kinode applications using their hosted Kinode. End users may also find the Managing Your Kinode section useful.
Here, ssh is used extensively.
This guide is specifically tailored to sshs use for the Kinode hosting service.
A more expansive guide can be found here.
Managing Your Kinode
Valet is the interface for managing your hosted node.
We plan to open-source the hosting code so there will be other hosting options in the future.
Once logged in, Your Kinodes will be displayed: clicking on the name of a Kinode will navigate to the homepage for that Kinode.
Clicking on the gear icon will open a modal with some information about the Kinode.
Click Show advanced details to reveal information for accessing your Kinode's terminal.
Accessing Your Kinode's Terminal
As discussed in Managing Your Kinode, navigate to:
- https://valet.uncentered.systems
Your Kinodes- Gear icon
Show advanced details
In the advanced details, note the SSH Address and SSH Password.
To access your Kinode remote instance, open a terminal and
ssh <SSH Address>
where <SSH Address> should be replaced with the one from your Valet advanced details.
You will be prompted for a password: copy-paste the SSH Password.
You should now have a different terminal prompt, indicating you have sshd into the remote instance hosting your Kinode.
Using SSH keys
Rather than typing in a password to create a SSH connection, you can use a keypair.
Generating Keypair
ssh-agent
How to use ssh-agent to store a keypair
SSH Config
How to use ~/.ssh/config to make SSH easier to use
Adding Public Key to Remote Node
How to add the public key to a remote node to allow login with it
Using kit With Your Hosted Node
kit interacts with a Kinode through the Kinode's HTTP RPC.
However, Kinode limits HTTP RPC access to localhost — remote requests are rejected.
The local limit is a security measure, since the HTTP RPC allows injection of arbitrary messages with "root" capabilities.
To use kit with a hosted node, you need to create a SSH tunnel, which maps a port on your local machine to a port on the Kinode's remote host.
HTTP requests routed to that local port will then appear to the remote host as originating from its localhost.
It is recommended to use kit connect to create and destroy a SSH tunnel.
Otherwise, you can also follow the instructions below to do it yourself.
Create a SSH tunnel like so (again, replacing assumed values with those in your advanced details):
ssh -L 9090:localhost:<HTTP port> <SSH address>
e.g.,
ssh -L 9090:localhost:8099 [email protected]
or, if you've added your host to your ~/.ssh/config,
ssh -L 9090:localhost:<HTTP port> <Host>
You should see a ssh session open.
While this session is open, kit requests sent to 9090 will be routed to the remote Kinode, e.g.,
kit s foo -p 9090
will function the same as for a locally-hosted Kinode.
Closing the ssh connections with Ctrl+D or typing exit will close the tunnel.
Audits and Security
The Kinode operating system runtime has been audited by Enigma Dark. That report can be found here.
However, the audit was not comprehensive and focused on the robustness of the networking stack and the kernel. Therefore, other parts of the runtime, such as the filesystem modules and the ETH RPC layer, remain unaudited. Kinode OS remains a work in progress and will continue to be audited as it matures.
Smart Contracts
Kinode OS uses a number of smart contracts to manage global state. [link to smart contract audit when finished]
Glossary
Kinode uses a variety of technical terms. The glossary defines those terms.
Address
Processes have a globally-unique address to and from which messages can be routed.
App Store
The Kinode App Store is the place where users download Kinode apps and where devs distribute Kinode packages.
Blob
See LazyLoadBlob.
Capability
Kinode uses capabilities to restrict what processes can do. A capability is issued by a process (the "issuer") and signed by the kernel. The holder of a capability can then attach that capability to a message. The kernel will confirm it is valid by checking the signature. If valid, it will be passed to the recipient of the message. Only trust capabilties from local holders! A remote node need not follow the rules above (i.e. it may run a modified runtime).
There are system-level and userspace-level capabilities.
System-level capabilities are of two types:
"messaging", which allows the holder to send messages to the issuer."net", which allows the holder to send/receive messages over the network to/from remote nodes.
System-level capabilities need not be attached explicitly to messages. They are requested and granted at process start-time in the manifest.
Userspace-level capabilities are defined within a process. They are issued by that process. Holders must explictly attach these capabilities to their messages to the issuing process. The issuer must define the logic that determines what happens if a sender has or does not have a capability. E.g., the system Contacts app defines capabilities here and the logic that allows/disallows access given a sender's capabilities here.
Inherit
Kernel
The Kinode microkernel is responsible for:
- Starting and stopping processes.
- Routing messages.
- Enforcing capabilities.
Kimap
Kimap is the onchain component of Kinode. Kimap is a path-value map. Protocols can be defined on Kimap.
Examples:
The KNS protocol stores contact information for all Kinodes in Kimap entries. That contact information looks like:
- A public key.
- Either an IP address or a list of other nodes that will route messages to that node.
The
kns-indexerKinode process reads the Kimap, looking for these specific path/entries, and then uses that information to contact other nodes offchain.
The Kinode App Store protocol stores the app metadata URI and hash of that metadata in Kimap entries.
The app-store Kinode process reads the Kimap, looking for these specific path/entries, and then uses that information to coordinate:
- Fetching app information.
- Finding mirrors to download from (over the Kinode network or HTTP).
- Confirming those mirrors gave the expected files.
- Fetching and installing updates, if desired, when made available.
Read more here.
Kimap-safe
A String containing only a-z, 0-9, -, and, for a publisher node, ..
LazyLoadBlob
An optional part of a message that is "loaded lazily". The purpose of he LazyLoadBlob is to avoid the cost of repeatedly bringing large data across the Wasm boundary in a message-chain when only the ends of the chain need to access the data.
Local
Of or relating to our node. Contrasts with remote.
E.g., a local process is one that is running on our node. Messages sent to a local process need not traverse the Kinode network.
Capabilities attached to messages received from a local process can be trusted since the kernel can be trusted.
Manifest
Message
Kinode processes communicate with each other by passing messages. Messages are addressed to a local or remote process, contain some content, and have a variety of associated metadata. Messages can be requests or responses. Messages can set off message-chains of requests and responses. A process that sends a request must specify the address of the recipient. In contrast, a response will be routed automatically to the sender of the most recently-received request in the message-chain that expected a response.
Message-chain
Module
A module, or runtime module, is similar to a process. Messages are addressed to and received from a module just like a process. The difference is that processes are Wasm components, which restricts them in a number of ways, e.g., to be single-threaded. Runtime modules do not have these same restrictions. As such they provide some useful features for processes, such as access to the Kinode network, a virtual file system, databases, the Ethereum blockchain, an HTTP server and client, etc.
Node
A node (sometimes referred to as a Kinode) is a server running the Kinode runtime. It communicates with other nodes over the Kinode network using message passing. It has a variety of runtime modules and also runs userspace processes which are Wasm components.
Package
An "app". A set of one-or-more processes along with one-or-more UIs. Packages can be distributed using the Kinode App Store.
Packages have a unique identity.
PackageId
Process
Kinode processes are the code bundles that make up userspace. Kinode processes are Wasm components that use either the Kinode process WIT file or that define their own WIT file that wraps the Kinode process WIT file.
Processes have a unique identity and a globally unique address.
ProcessId
Remote
Of or relating to someone else's node. Contrasts with local.
E.g., a remote process is one that is running elsewhere. Messages sent to a remote process must traverse the Kinode network.
Capabilities attached to messages received from a remote process cannot be trusted since the kernel run by that remote node might be modified. E.g., the hypothetical modified kernel might take all capabilities issued to any process it runs and give it to all processes it runs.
Request
A message that requires the address of the recipient. A request can start off a messsage-chain if the sender sets metadata that indicates it expects a response.
Response
A message that is automatically routed to the sender of the most recently-received request in the message-chain that expected a response.
Runtime
Wasm Component
The WebAssembly Component Model is a standard that builds on top of WebAssembly and WASI. Wasm components define their interfaces using WIT. Kinode processes are Wasm components.
WIT
WIT is the Wasm Interface Type. WIT is used to define the interface for a Wasm component. Kinode processes must use either the Kinode process WIT file or define their own WIT file that wraps the Kinode process WIT file